Download

1 / 16
160 likes | 236 Views
Search Engine-Crawler Symbiosis: Adapting to Community Interests. Gautam Pant * , Shannon Bradshaw * and Filippo Menczer ** * Department of Management Sciences The University of Iowa, Iowa City, IA 52246 ** School of Informatics Indiana University, Bloomington, IN 47408. Overview.

E N D
Search Engine-Crawler Symbiosis: Adapting to Community Interests Gautam Pant*, Shannon Bradshaw* and Filippo Menczer** *Department of Management Sciences The University of Iowa, Iowa City, IA 52246 **School of Informatics Indiana University, Bloomington, IN 47408
Overview • Search Engines and Crawlers • The Symbiotic Model • Implementation • Simulation Study • Results
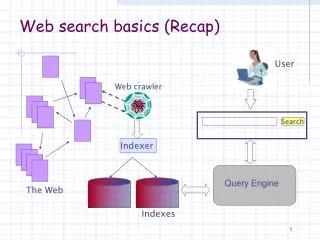
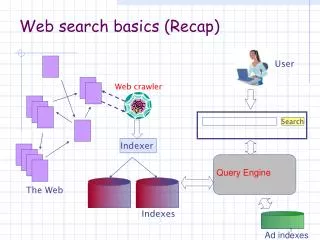
Modern Search Engines User Page Repository (Collection) Queries Results Query Engine Ranking Crawlers Indexer Indexes Text Structure Web (adapted from Searching the Web, Arasu et. al., ACM TOIT 2002)
Search Engine and Crawler • Dynamism of the Web • Exhaustive crawling • Focused needs of a community • Topical crawling • Freshness, Efficiency, Focus • Finding the “right” collection • Adapting to drifting interests
Implementation • Search Engine - Rosetta • RDI - Indexing based on contextual information • Voting mechanism • Topical Crawler – Naïve Best-First • Frontier as a priority queue • Similarity of parent page to the query
Simulation Study • DMOZ “Business/E-Commerce” category • Assumption: Interests of the simulated community lie within the selected category and its sub-categories • Random subset of URLs from categories – bookmark URLs • Database of queries – automatically identify phrases from description of the URLs – filter them manually
Simulation • Simulated 5 days of operation • Initial collection created through a breadth-first crawl of 100,000 pages starting from the bookmark URLs • 100 queries picked at random from query database for each day • 1Gz Pentium III IBM Thinkpad running Windows 2000 • Less than 11 hours to build and index a new collection for the next time period
Performance Metrics • Collection Quality • Precision@10 • Manual evaluation of query results – human subjects made aware of the context through DMOZ category page
Related Work • Vertical Portals • Context based classification, clustering and indexing • Topical or Focused crawlers • Collaborative Filtering
Conclusion • A model for adaptive vertical portals through tight coupling of a topical crawler and a search engine • Eliminates irrelevant information in short time to focus on the community interests efficiently • Future work • Use of more global information available to a search engine during the crawl • Distribution of symbiotic model to a P2P network
Thank You Acknowledgements: Padmini Srinivasan Kristian Hammod Rik Belew Student Volunteers NSF grant to FM