Download
1 / 39
390 likes | 592 Views
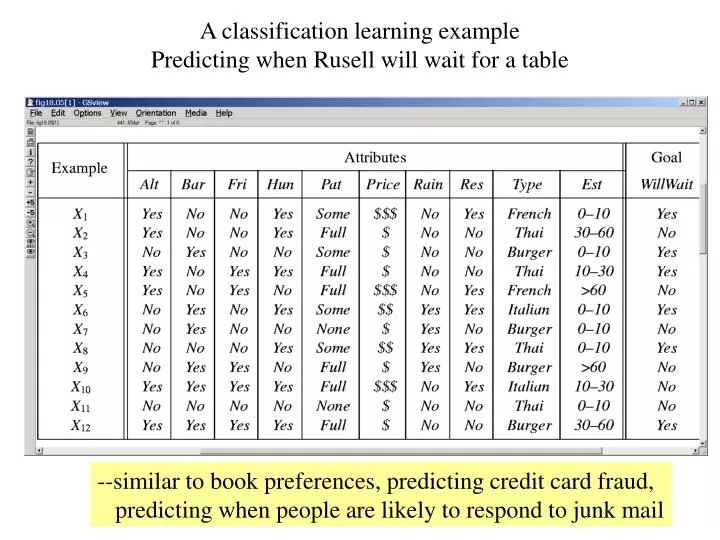
A classification learning example Predicting when Rusell will wait for a table. --similar to book preferences, predicting credit card fraud, predicting when people are likely to respond to junk mail. Uses different biases in predicting Russel’s waiting habbits. Decision Trees

E N D
A classification learning example Predicting when Rusell will wait for a table --similar to book preferences, predicting credit card fraud, predicting when people are likely to respond to junk mail
Uses different biases in predicting Russel’s waiting habbits Decision Trees --Examples are used to --Learn topology --Order of questions K-nearest neighbors If patrons=full and day=Friday then wait (0.3/0.7) If wait>60 and Reservation=no then wait (0.4/0.9) Association rules --Examples are used to --Learn support and confidence of association rules SVMs Neural Nets --Examples are used to --Learn topology --Learn edge weights Naïve bayes (bayesnet learning) --Examples are used to --Learn topology --Learn CPTs
Inductive Learning(Classification Learning) • Given a set of labeled examples, and a space of hypotheses • Find the rule that underlies the labeling • (so you can use it to predict future unlabeled examples) • Tabularasa, fully supervised • Idea: • Loop through all hypotheses • Rank each hypothesis in terms of its match to data • Pick the best hypothesis • The main problem is that • the space of hypotheses is too large • Given examples described in terms of n boolean variables • There are 2 different hypotheses • For 6 features, there are 18,446,744,073,709,551,616 hypotheses 2n
A good hypothesis will have fewest false positives (Fh+) and fewest false negatives (Fh-) [Ideally, we want them to be zero] On training or testing data?? Rank(h) = f(Fh+, Fh-) (loss function) --f depends on the domain by default f=Sum; but can give different weights to different errors (Cost-based learning) False +ve: The learner classifies the example as +ve, but it is actually -ve Ranking hypotheses H1: Russell waits only in italian restaurants false +ves: X10, false –ves: X1,X3,X4,X8,X12 H2: Russell waits only in cheap french restaurants False +ves: False –ves: X1,X3,X4,X6,X8,X12 • Medical domain • --Higher cost for F- • --But also high cost for F+ • Spam Mailer • --Very low cost for F+ • --higher cost for F- • Terrorist/Criminal Identification • --High cost for F+ (for the individual) • --High cost for F- (for the society)
(Idea) Learner must classify all new instances (test cases) correctly always Any test cases? Test cases drawn from the same distribution as the training cases Always? May be the training samples are not completely representative of the test samples So, we go with “probably” Correctly? May be impossible if the training data has noise (the teacher may make mistakes too) So, we go with “approximately” The goal of a learner then is to produce a probably approximately correct (PAC) hypothesis, for a given approximation (error rate) e and probability d. When is a learner A better than learner B? For the same e,dbounds, A needs fewer training samples than B to reach PAC. Complexity measured in number of Samples required to PAC-learn Learning Curves What is a reasonable goal in designing a learner?
Inductive Learning(Classification Learning) • Main variations: • Bias: the “sort” of rule are you looking for? • If you are looking for only conjunctive hypotheses, there are just 3n • Search: • Greedy search • Decision tree learner • Systematic search • Version space learner • Iterative search • Neural net learner • Given a set of labeled examples, and a space of hypotheses • Find the rule that underlies the labeling • (so you can use it to predict future unlabeled examples) • Tabularasa, fully supervised • Idea: • Loop through all hypotheses • Rank each hypothesis in terms of its match to data • Pick the best hypothesis • The main problem is that • the space of hypotheses is too large • Given examples described in terms of n boolean variables • There are 2 different hypotheses • For 6 features, there are 18,446,744,073,709,551,616 hypotheses 2n
Uses different biases in predicting Russel’s waiting habbits Decision Trees --Examples are used to --Learn topology --Order of questions K-nearest neighbors If patrons=full and day=Friday then wait (0.3/0.7) If wait>60 and Reservation=no then wait (0.4/0.9) Association rules --Examples are used to --Learn support and confidence of association rules SVMs Neural Nets --Examples are used to --Learn topology --Learn edge weights Naïve bayes (bayesnet learning) --Examples are used to --Learn topology --Learn CPTs
Which one to pick? Learning Decision Trees---How? Basic Idea: --Pick an attribute --Split examples in terms of that attribute --If all examples are +ve label Yes. Terminate --If all examples are –ve label No. Terminate --If some are +ve, some are –ve continue splitting recursively (Special case: Decision Stumps If you don’t feel like splitting any further, return the majority label ) 20 Questions: AI Style
Depending on the order we pick, we can get smaller or bigger trees Which tree is better? Why do you think so??
Decision Trees & Sample Complexity • Decision Trees can Represent any boolean function • ..So PAC-learning decision trees should be exponentially hard (since there are 22n hypotheses) • ..however, decision tree learning algorithms use greedy approaches for learning a good (rather than the optimal) decision tree • Thus, using greedy rather than exhaustive search of hypotheses space is another way of keeping complexity low (at the expense of losing PAC guarantees)
Would you split on patrons or Type? Basic Idea: --Pick an attribute --Split examples in terms of that attribute --If all examples are +ve label Yes. Terminate --If all examples are –ve label No. Terminate --If some are +ve, some are –ve continue splitting recursively --if no attributes left to split? (label with majority element)
# expected comparisons needed to tell whether a given example is +ve or -ve N+ N- Splitting on feature fk N2+ N2- Nk+ Nk- N1+ N1- I(P1+ ,, P1-) I(P2+ ,, P2-) I(Pk+ ,, Pk-) k S [Ni+ + Ni- ]/[N+ + N-]I(Pi+ ,, Pi-) i=1 The Information Gain Computation P+ : N+ /(N++N-) P- : N- /(N++N-) I(P+ ,, P-) = -P+ log(P+) - P- log(P- ) The difference is the information gain So, pick the feature with the largest Info Gain I.e. smallest residual info Given k mutually exclusive and exhaustive events E1….Ek whose probabilities are p1….pk The “information” content (entropy) is defined as S i -pi log2 pi A split is good if it reduces the entropy..
I(1/2,1/2) = -1/2 *log 1/2 -1/2 *log 1/2 = 1/2 + 1/2 =1 I(1,0) = 1*log 1 + 0 * log 0 = 0 A simple example V(M) = 2/4 * I(1/2,1/2) + 2/4 * I(1/2,1/2) = 1 V(A) = 2/4 * I(1,0) + 2/4 * I(0,1) = 0 V(N) = 2/4 * I(1/2,1/2) + 2/4 * I(1/2,1/2) = 1 So Anxious is the best attribute to split on Once you split on Anxious, the problem is solved
“Majority” function (say yes if majority of attributes are yes) Russell Domain m-fold cross-validation Split N examples into m equal sized parts for i=1..m train with all parts except ith test with the ith part Evaluating the Decision Trees Lesson: Every bias makes some concepts easier to learn and others harder to learn… Learning curves… Given N examples, partition them into Ntr the training set and Ntest the test instances Loop for i=1 to |Ntr| Loop for Ns in subsets of Ntr of size I Train the learner over Ns Test the learned pattern over Ntest and compute the accuracy (%correct)
Decision Trees vs. Naïve Bayes For Russell Restaurant Scenario Decision trees are better if there is a “succinct” explanation in terms of a few features. NBC is better if all features wind up playing a role e.g. Spam mails
Problems with Info. Gain. Heuristics • Feature correlation: We are splitting on one feature at a time • The Costanza party problem • No obvious easy solution… • Overfitting: We may look too hard for patterns where there are none • E.g. Coin tosses classified by the day of the week, the shirt I was wearing, the time of the day etc. • Solution: Don’t consider splitting if the information gain given by the best feature is below a minimum threshold • Can use the c2 test for statistical significance • Will also help when we have noisy samples… • We may prefer features with very high branching • e.g. Branch on the “universal time string” for Russell restaurant example • Branch on social security number to look for patterns on who will get A • Solution: “gain ratio” --ratio of information gain with the attribute A to the information content of answering the question “What is the value of A?” • The denominator is smaller for attributes with smaller domains.
Decision stumps are decision trees where the leaf nodes do not necessarily have all +ve or all –ve training examples Could happen either because examples are noisy and mis-classified or because you want to stop before reaching pure leafs When you reach that node, you return the majority label as the decision. (We can associate a confidence with that decision using the P+ and P-) N+ N- N2+ N2- Nk+ Nk- N1+ N1- Decision Stumps Splitting on feature fk P+= N1+ / N1++N1- Sometimes, the best decision tree for a problem could be a decision stump (see coin toss example next)
Uses different biases in predicting Russel’s waiting habbits Decision Trees --Examples are used to --Learn topology --Order of questions K-nearest neighbors If patrons=full and day=Friday then wait (0.3/0.7) If wait>60 and Reservation=no then wait (0.4/0.9) Association rules --Examples are used to --Learn support and confidence of association rules SVMs Neural Nets --Examples are used to --Learn topology --Learn edge weights Naïve bayes (bayesnet learning) --Examples are used to --Learn topology --Learn CPTs
Decision Surface Learning(aka Neural Network Learning) • Idea: Since classification is really a question of finding a surface to separate the +ve examples from the -ve examples, why not directly search in the space of possible surfaces? • Mathematically, a surface is a function • Need a way of learning functions • “Threshold units”
The “Brain” Connection A Threshold Unit Threshold Functions differentiable …is sort of like a neuron
I1 w1 t=k I2 w2 I0=-1 w1 w0= k t=0 w2 Perceptron Networks What happened to the “Threshold”? --Can model as an extra weight with static input ==
Perceptron Learning as Gradient Descent Search in the weight-space Optimal perceptron has the lowest error on the training data Often a constant learning rate parameter is used instead Ij I
Perceptron Learning • Perceptron learning algorithm Loop through training examples • If the activation level of the output unit is 1 when it should be 0, reduce the weight on the link to the jth input unit by a*Ij, where Ii is the ith input value and aa learning rate • So, we are assuming g’(.) is a constant.. Which it is really not.. • If the activation level of the output unit is 0 when it should be 1, increase the weight on the link to the ith input unit by a*Ij • Otherwise, do nothing Until “convergence” Iterative search! --node -> network weights --goodness -> error Actually a “gradient descent” search A nice applet at: http://neuron.eng.wayne.edu/java/Perceptron/New38.html
Comparing Perceptrons and Decision Trees in Majority Function and Russell Domain Decision Trees Perceptron Decision Trees Perceptron Majority function Russell Domain Majority function is linearly seperable.. Russell domain is apparently not.... Encoding: one input unit per attribute. The unit takes as many distinct real values as the size of attribute domain
Can Perceptrons Learn All Boolean Functions? --Are all boolean functions linearly separable?
Any line that separates the +ve & –ve examples is a solution And perceptron learning finds one of them But could we have a preference among these? may want to get the line that provides maximum margin (equidistant from the nearest +ve/-ve) The nereast +ve and –ve holding up the line are called support vectors This changes optimization objective Quadratic Programming can be used to directly find such a line Max-Margin Classification & Support Vector Machines
First transform the data into higher dimensional space Find a linear surface Which is guaranteed to exist Transform it back to the original space TRICK is to do this without explicitly doing a transformation Learn non-linear surfaces directly (as multi-layer neural nets) Trick is to do training efficiently Back Propagation to the rescue.. Two ways to learn non-linear decision surfaces
= 1 if w1I1+w2I2 > k = 0 otherwise Recurrent Feed Forward Uni-directional connections Bi-directional connections Single Layer Multi-Layer Any “continuous” decision surface (function) can be approximated to any degree of accuracy by some 2-layer neural net Can act as associative memory Any linear decision surface can be represented by a single layer neural net “Neural Net” is a collection of with interconnections threshold units differentiable
Linear Separability in High Dimensions “Kernels” allow us to consider separating surfaces in high-D without first converting all points to high-D
Kernelized Support Vector Machines • Turns out that it is not always necessary to first map the data into high-D, and then do linear separation • The quadratic programming formulation for SVM winds up using only the pair-wise dot product of training vectors • Dot product is a form of similarity metric between points • If you replace that dot product by any non-linear function, you will, in essence, be transforming data into some high-dimensional space and then finding the max-margin linear classifier in that space • Which will correspond to some wiggly surface in the original dimension • The trick is to find the RIGHT similarity function • Which is a form of prior knowledge
Kernelized Support Vector Machines • Turns out that it is not always necessary to first map the data into high-D, and then do linear separation • The quadratic programming formulation for SVM winds up using only the pair-wise dot product of training vectors • Dot product is a form of similarity metric between points • If you replace that dot product by any non-linear function, you will, in essence, be tranforming data into some high-dimensional space and then finding the max-margin linear classifier in that space • Which will correspond to some wiggly surface in the original dimension • The trick is to find the RIGHT similarity function • Which is a form of prior knowledge
Those who ignore easily available domain knowledge are doomed to re-learn it… Santayana’s brother Domain-knowledge & Learning • Classification learning is a problem addressed by both people from AI (machine learning) and Statistics • Statistics folks tend to “distrust” domain-specific bias. • Let the data speak for itself… • ..but this is often futile. The very act of “describing” the data points introduces bias (in terms of the features you decided to use to describe them..) • …but much human learning occurs because of strong domain-specific bias.. • Machine learning is torn by these competing influences.. • In most current state of the art algorithms, domain knowledge is allowed to influence learning only through relatively narrow avenues/formats (E.g. through “kernels”) • Okay in domains where there is very little (if any) prior knowledge (e.g. what part of proteins are doing what cellular function) • ..restrictive in domains where there already exists human expertise..
Multi-layer Neural Nets How come back-prop doesn’t get stuck in local minima? One answer: It is actually hard for local minimas to form in high-D, as the “trough” has to be closed in all dimensions
Multi-Network Learning can learn Russell Domains Decision Trees Decision Trees Multi-layer networks Perceptron Russell Domain …but does it slowly…
Practical Issues in Multi-layer network learning • For multi-layer networks, we need to learn both the weights and the network topology • Topology is fixed for perceptrons • If we go with too many layers and connections, we can get over-fitting as well as sloooow convergence • Optimal brain damage • Start with more than needed hidden layers as well as connections; after a network is learned, remove the nodes and connections that have very low weights; retrain
Humans make 0.2% Neumans (postmen) make 2% Other impressive applications: --no-hands across america --learning to speak K-nearest-neighbor The test example’s class is determined by the class of the majority of its k nearest neighbors Need to define an appropriate distance measure --sort of easy for real valued vectors --harder for categorical attributes