Download

1 / 48
480 likes | 677 Views
第九章 Web 資料採掘 9.1 非結構化 Web 資料來源 9.2 Web 採掘分類 9.3 Web 內容採掘 9.4 Web 結構採掘 9.5 Web 存取採掘 9.6 利用 Web 日誌的群集演算法 9.7 電子商務中的 Web 挖掘 習題. Web 採掘是利用資料採掘技術從 Web 文件及 Web 服 務中自動發現並萃取人們感興趣的資訊。它是一項 整合式技術,涉及到 Internet 技術、人工智慧、電腦 語言學、資訊學、統計學等多個領域。通常 Web 採 掘過程可以分為以下幾個處理階段:資源發現、資

E N D
第九章 Web資料採掘9.1 非結構化Web資料來源 9.2 Web採掘分類9.3 Web內容採掘9.4 Web結構採掘9.5 Web存取採掘9.6 利用Web日誌的群集演算法9.7 電子商務中的Web挖掘習題
Web採掘是利用資料採掘技術從Web文件及Web服 務中自動發現並萃取人們感興趣的資訊。它是一項 整合式技術,涉及到Internet技術、人工智慧、電腦 語言學、資訊學、統計學等多個領域。通常Web採 掘過程可以分為以下幾個處理階段:資源發現、資 料萃取及資料預處理階段,資料匯總及模式識別階 段,分析驗證階段。
主要區別為: • 採掘系統則能夠從文本中萃取出目標資訊的特徵,然後根據目標特徵在網路中進行有目的的搜尋,最後將搜尋到的文件交付給客戶。 • 資訊檢索的目的是針對某一特定領域進行資訊或文件的收集,可以看作是Web採掘用於中文件分類的一種情況。 • Web採掘的目的就是將大量看似無關的資料關聯起來發現其中的規則和知識以供決策支援。
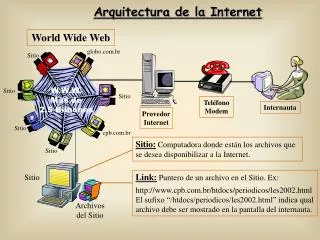
9.1 非結構化Web資料來源 • Web資料採掘的困難度 由於Web的開放性、動態性與異構性等固有特點, 要從這些分散的、異構的、沒有統一管理的巨量資 料中快速、準確地擷取資訊,也成為Web採掘所要 解決的一個困難之處,顯然,Web導向的資料採掘 比單一資料倉儲的資料採掘要複雜得多。以下是 Web資料採掘應考量的問題。
資料來源分析 在對網站作資料採掘時,所需要的資料主要來自於 三方面:Web伺服器中的日誌檔、Web伺服器中的其 他資訊以及客戶的背景資訊。 • 異構資料環境 從資料庫研究的角度出發,Web網站上的資訊也可 以看作一個資料庫,一個更大、更複雜的資料庫。 這就構成了一個巨大的異構資料庫環境。
半結構化的資料結構 Web上的資料具有一定的結構性,但因自我描述階 層的存在,從而是一種非完全結構化的資料,這也 被稱之為半結構化資料。 • 解決半結構化的資料來源問題 Web資料採掘技術首先要解決半結構化資料來源模 型,和半結構化資料模型的查詢與整合問題。
文本總結 文本總結是指從文件中萃取關鍵資訊,用簡潔的形 式對文件內容進行摘要或解釋。 • XML與Web資料採掘技術 • XML的產生與發展 • XML(extensible markup language,XML)是由全球資訊網協會(W3C)於1998年2月正式發佈XML 1.0 • XML是Web應用服務的SGML(standard general markup language,SGML)的一個重要部分,它是一種超標記語言(meta-markuplanguage)
XML解決了HTML不能解決的兩個關於Web的問題 • XML中的標記(TAG)是沒有預先定義的 • XML是能夠進行自我描述(self describing)的語言。 • XML使用文件類型定義(document type definition,DTD)來顯示這些資料
XML的主要特點 • XML不僅可以很好地相容原有的Web應用,而且可以更好地執行Web中的資訊共享與交換 • XML可看作一種半結構化的資料模型 • XML為一種標記語言 • XML提供了一個標示結構化資料的架構。XML提供了一個獨立的運用程式來共享資料 • XML支援世界上所有以主要語言編寫的混合文本。
XML在Web資料採掘中的應用 • XML能夠完成那些用標準的HTML無法完成的Web應用。這些應用可以被分成以下四類: • 需要Web客戶端在兩個或更多異質資料庫之間進行通訊的應用 • 試圖將大部分處理負載從Web伺服器轉到Web客戶端的應用 • 要Web客戶端將同樣的資料以不同的瀏覽形式提供給不同的客戶的應用 • 需要智慧型Web代理程式根據客戶個人的需要裁減資訊內容的應用。
XML給Web導向的應用軟體賦予了強大的功能和靈活性 • 軟體代理商可以在中間層的伺服器上對從後端資料庫和其他應用處來的資料進行整合 • XML的延伸性和靈活性允許它描述不同種類應用軟體中的資料 • 利用XML,客戶可以方便地進行局部計算和處理
XML可以被利用來分離使用者觀看資料的介面,使用簡單、靈活、開放的格式,可以給Web創建功能強大的應用軟體XML可以被利用來分離使用者觀看資料的介面,使用簡單、靈活、開放的格式,可以給Web創建功能強大的應用軟體 • XML定義的資料允許指定不同的顯示方式,使資料更合理地表現出來。 • CSS和XSL為資料的顯示提供了公佈的機制。透過XML資料,可以粒狀地更新。 • XML解決了資料的統一介面問題。
XML的自我解釋性使客戶端在收到資料的同時也瞭解資料的邏輯結構與含義,從而使廣泛、運用的分散式計算成為可能XML的自我解釋性使客戶端在收到資料的同時也瞭解資料的邏輯結構與含義,從而使廣泛、運用的分散式計算成為可能 • XML還被應用於網路代理 • 能夠使不同來源的結構化的資料很容易地結合在一起 • XML為組織、軟體開發者、Web網站和終端使用者提供了許多有利條件。
9.2 Web採掘分類 Web資料有三種類型: • HTML標記的Web文件資料 • Web文件內的連接的結構資料 • 客戶存取資料如伺服器的log日誌資訊 按照對應的資料類型,Web採掘可分為三類: • 內容採掘 • 結構採掘 • 客戶存取模式採掘
Web採掘一般分為以下幾步: • 資源發現 用爬蟲(crawler)和蜘蛛(spider)從WWW線上收集頁面。 • 資訊選擇與預先處理 如英文單字的字彙萃取、高低頻繁字過濾,漢字的切分和索引庫的建立 • 整合程式 發現Web網站的共通模式。 • 分析程式 對採掘到的模式進行驗證和視覺化處理。
9.3 Web內容採掘 文本Web導向採掘方法有: • 資料庫方法 • 建立Web資料倉儲方法 • 新近的軟體agent的分類器方法 • 概念導向的文本資訊採掘法
Web內容採掘按執行方法分為兩大類: • 資訊檢索(information retrieval,IR)方法 • 資料庫方法 兩種策略: • 直接採掘文件內容 • 在其他檢索工具搜尋的基礎上改進。
IR方法主要處理非結構資料和Web中由HTML標記的半結構化資料。前者一般採用字集(bags of words)方法,用一組組字句來表示無結構的文本。 • 資料庫方法,推導出Web網站的結構或把它變成一個資料庫。一般用OEM (object exchange model,OEM)表示半結構化資料。
直接採掘文件內容:採用這種策略比較好的Web查詢語言有Web SQL,Ahoy!等。 • 對搜尋引擎返回的結果進行採掘可提供給客戶更為準確的查詢結果。如Web SQL系統存取搜尋引擎獲取文件。
9.4 Web結構採掘 Page-Rank方法(Brin and Page 1998): Page-Rank的基本方法是:一個頁面被多次引用,則 這個頁面很可能是重要的;一個頁面儘管沒有被多 次引用,但被一個重要頁面引用,該頁面也可能是 很重要的;一個頁面的重要性被均分並被傳遞到它 所引用的頁面中。
如對於一個查詢q,搜尋引擎首先利用相似度函數找如對於一個查詢q,搜尋引擎首先利用相似度函數找 到K個頁面,然後利用公式計算每個頁面的重要 性,然後進行排序,如下所示: ranking ─ score (q,d)=ω1 × Sim (q,d) +ω2 × R (d)
9.5 Web存取採掘 Wet存取採掘一般分為兩種: • 一般存取模式追蹤和客 • 制化使用追蹤 一般存取模式追蹤透過分析Web日誌來了解客戶的 存取模式和傾向;客制化使用追蹤分析單一客戶的 偏好,根據其存取模式為每個客戶量身制定符合其 個人特色的Web網站。
預先處理 主要包括對Web日誌作淨化、過濾和轉換以及剔除無關記錄。 • 客戶存取模式的發現 可採用統計學(statistics)、模式識別(model identification)、人工智慧、資料庫資料採掘等領域的成熟技術在Web的使用記錄中採掘知識。
Web使用採掘中的模式分析 主要是為了在模式發現演算法找到的模式集合中發現有趣模式。 客戶導覽資訊的採掘通常要經過下面三個步驟: • 資料預先處理階段。 • 模式識別階段。 • 模式分析階段。
早期使用的方法除了廣度優先演算法為主的統計模早期使用的方法除了廣度優先演算法為主的統計模 型外,還有一種啟發的HPG (hyper-textprobabilistic grammar)模型用於客戶導覽行為的發現,它也是一 種統計導向的方法,由於HPG模型與K階馬可夫模 型相當,也有人提出用馬可夫模型採掘用戶導覽資 訊。
9.6 利用Web日誌的群集演算法 • 客戶群體的模糊群集演算法 用C表示客戶集合,C ={C1,C2…Ci,…, Cm}表示某一站點URL集合,U={C1, C2…,Cm};Ci客戶C的瀏覽圖 可用網站的 URL表示: 其中(Uj)→[0,1]是客戶Ci和URL(Uj)之間的關聯度函 數: =
客戶存取興趣的演算法 K-PathS群集方法是一種分割而非分層的群集演算 法。它是按照路徑的相似性進行群集的演算法。以 一個客戶存取交易T為例,它具有 個交易,K- PathS群集方法將T分為 個群集( ),並使在每一 個群集中所有交易與該交易所在的群集中心相似度 的總和最小。
客戶群體群集的 Hamming 距離演算法 設 ,則 間Hamming距離 定義為 =
對於Mm×n關聯矩陣,若有任意 >0,可先令 =1,然後計算列向量間Hamming距離,從而建立列 向量之間的距離矩陣 。在對稱矩陣 。中的 表示第個列向量和第個 列向量間的Hamming距離。對於任意的 ,若 ,則將 第個客戶和所有滿足該條件的第 個客戶劃分為一 類。
客戶和所有滿足該條件的第 j 個客戶劃分為一類。 此時若考慮到客戶對某一URL的存取頻率,則需要 對群集結果加以確認。若客戶 C 和 K 之間連接 強度小於事先確定的閥值,則將該客戶剔除出類K 並與其他被剔除的 C 劃分為另一個類k。
模糊理論導向的Web頁面群集演算法 與客戶群體群聚的模糊群集定義相同,客戶存取情 況可用 表示。有 = ,其中 →[0,1]是客戶 和 間的關聯度: =
Web頁面群集的Hamming距離演算法 同Hamming距離客戶群體群集演算法一樣,對於 關聯矩陣,若有任意 >0,可先令 =1, 然後計算行向量間Hamming距離,從而建立行向量 間的距離矩陣 。在對稱矩陣 中, 表示第 i 個行向量和第 j 個行向量間的Hamming距離。
9.7 電子商務中的Web挖掘 • 電子商務中Web採掘的功能 設計電子商務個性化網站面臨如何發現客戶行為的 個性化特色及Web重要頁面的組織問題。由於個性 化服務是電子商務網站提高網路效率和吸引網路客 戶存取的有效方法,其資源組織方式、組織效率已 成為智慧型電子商務的技術焦點。
電子商務中Web採掘的基本問題 Web採掘大致可分為3類: • 以分析系統為目標 • 以設計系統為目標 • 以了解客戶意圖為目標。 由於各目標所鎖定的功能不同,採取的主要技術也 不同。
客戶的確定 在Web採掘中對於實際使用中惟一確定一個客戶很 難 ,有時候可以把伺服器日誌、代理(agent)和參照 (reference)頁面日誌整合起來確定一個客戶。 • 客戶存取序列的確定 就是按照時間順序找出客戶申請的一系列頁面。一 般伺服器日誌是以存取客戶的IP地址為輔助鍵、存 取時間為主鍵排列的
改善存取路徑 由於存在著客戶端的快取記憶體,用戶瀏覽頁面時 能使用瀏覽器的後退功能,要根據客戶存取的前後 頁面進行推理,將其疏漏的頁面補充在路徑裡。另 外,執行CGI程式時,由於其傳遞的參數不同,最 後的輸出結果不同,必要時還要結合參數確定顯示 的頁面內容。
電子商務中的資料採掘工具 Web資料採掘工具按其用途可有以下3種類型: • 文本資訊採掘工具 通常文本採掘工具主要完成下列兩種的工作: • 資訊檢索 • 對文本的分析 文本採掘工具的主要設計目標是使客戶易於瞭解文 件內容或用於收集相關文件所花費的時間最少。
客戶存取模式採掘工具 由Stephen Turner博士編寫的免費個人軟體Analog是 一個用來分析伺服器日誌檔的工具,它適用於 Windows及UNIX等作業系統。由於它使用起來較簡 單,可以直接在伺服器上執行,也可以將日誌檔下 載到客戶端。
客戶導航行為採掘工具 WUM (Web utilization miner,WUM)是一種序列採 掘的客戶導覽行為採掘工具。它主要用來分析客戶 導覽行為,適用於從任何類型的日誌檔中發現客戶 導覽資訊。
整合性Web分析工具 ACCRUE Insight5是Accrue公司的主要產品,它是一 個整合性的Web分析工具。它能夠對Web的執行狀況 有更深入、精密和準確的分析。 它的設計是顧客導向的,透過分析顧客的行為 模式,協助網站採取措施來提高顧客的忠誠度,從 而建立長期的客戶關係。
BI. Bank是針對銀行業適時推出的一套完備的商業智 慧解決方案,為銀行提供決策支援並執行資訊共享 和加強客戶關係的管理。BI. Bank包括銀行決策支援 系統、客戶關係管理系統、銀行資訊中心等鎖定不 同使用物件的子系統。BI. Bank利用資料倉儲、線上 分析處理、資料採掘以及Web等核心技術,並採用 了資料庫伺服器(DB SERVER)、應用伺服器(APP SERVER)和客戶端(C/B)三層架構。
習題 • XML在Web採掘中有何功能。 • 比較Web採掘三種方法的特色。 • 說明Web內容採掘與Web結構採掘得任務。 • 說明Web存取任務。 • 電子商務中Web採掘的功能,基本問題與意義分別是什麼。