Download

1 / 1
10 likes | 167 Views
PreDetector : Prokaryotic Regulatory Element Detector Samuel Hiard 1 , Sébastien Rigali 2 , Séverine Colson 2 , Raphaël Marée 1 and Louis Wehenkel 1

E N D
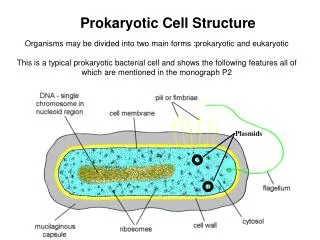
PreDetector : Prokaryotic Regulatory Element Detector Samuel Hiard1, Sébastien Rigali2, Séverine Colson2, Raphaël Marée1 and Louis Wehenkel1 1 Department of Electrical Engineering and Computer Science & Centre for biomedical inegrative genoproteomics CBIG/GIGA – University of Liège, Sart-Tilman B28 Liège, Belgium 2Centre for Protein Engineering – University of Liège, Sart-Tilman B6 Liège, Belgium Abstract PreDetector is a stand-alone software, written in java. Its final aim is to predict regulatory sites for prokaryotic species. It comprises two functionalities. The first one is very similar to Target Explorer1. From a set of sequences identified as potential target sites, PreDetector creates a consensus sequence and computes its scoring matrix. This sequence and matrix can be saved on a file and, then, be used to find along a selected genome the sequences that are close enough to the consensus sequence. To this end, a score is attributed to each locus in the genome according to the similarity measure defined by the matrix. The output of this functionality is filtered with a cut-off score and then directly used as input by the second one. The second functionality starts by fetching the gene positions of the selected species from the NCBI server. The loci having above cut-off score are then classified into four classes, allowing multiple classes for one element. This gives the biologists a better view of his discovered sequences. Matrix Generation When biologists search for a regulation motif, they find several potential sequences. We then have to find a way to obtain a consensus sequence that averages the potential ones. The first point would be to make a kind of alignment of the potential sequences. Target Explorer1 allows variable lengths for the sequences, but PreDetector doesn’t. It just takes the sequences « as it » and starts the generation of the matrix. The matrix should reflect the fact that nucleotides with higher frequencies at some position in the observed set should have a greater impact on the score on that position than nucleotides that are more equally distributed. In the other hand, nucleotides with high expected frequencies along the genome should not have much importance, as they are likely to be found, and conversely. So, the weight function for a specific nucleotide in the matrix is the following one1 : where : - ni,jis the observed frequency of nucleotide i in position j - N is the number of sequences in the set - pi is the expected frequency of nucleotide i in the genome Consensus search in genome When the matrix is computed, it can be used to find similar loci in the genome. The score for each locus is calculated as the sum of the values that each base of the sequence has in the weight matrix. Exemple : Use the previous matrix to find similar loci on nucleotides 100 – 200 on gene X of Drosophila Melanogaster. (Only the first 5 results are shown here). Then, only sequences that have a score greater than a user-defined cut-off score are kept. In this exemple, we could set the cut-off score at 2.40 and keep only the first three elements The four classes 1) Regulatory : The distal is located in the user- specified bounds, and at least one nucleotide is not in a gene 2) Upstream : The distal is facing a start codon and is not in a gene 3) Coding : The distal is in a gene 4) Terminator : At least one nucleotide facing a stop codon, and no start codon Screen shots Matrix Generation Search Parameters Results PreDetector in two words Sequence search ACGT …AACGTTTTTACGTCCCCACGT… Classification Genes positions Exemple of matrix Let’s assume that we have experimentally discovered these motifs: A C G T C A C G G T C C G C T on a specie known to have 40% CG, the consensus matrix will then be : Terminator Coding Score ≥ Threshold NCBI Server Regulatory Upstream Classification When several hits have been found, PreDetector then classifies them into 4 different classes : Regulatory, Upstream, Coding and Terminator, allowing multiple classes per element. To achieve this goal, PreDetector connects to the NCBI server, and downloads the specie’s genes positions. The classes are described in detail on the next column. Conclusion PreDetector can play an important role in automatic regulatory element detection and validation. It also can be upgraded for eukaryotic species handling. References 1. Target Explorer: an automated tool for the identification of new target genes for a specified set of transcription factors, Alona Sosinsky, Christopher P. Bonin, Richard S. Mann and Barry Honig, Nucleic Acids Research, 2003, Vol. 31, No. 13 3589-3592