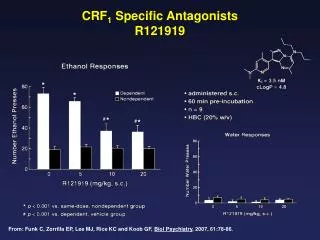
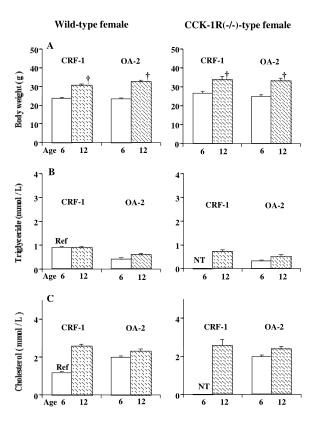
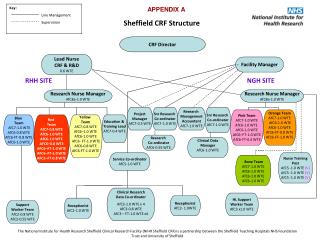
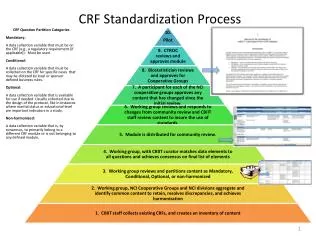
Download

1 / 0
30 likes | 212 Views
CRF Homework. Gaining familiarity with a standard NLP toolkit, and NLP tasks. Goals for this homework. Learn how to use Conditional Random Fields, a standard framework for sequence labeling in NLP Apply CRFs to two standard datasets

E N D








![[CRF] = Q.R.W [TRF]](https://cdn2.slideserve.com/4138927/slide1-dt.jpg)
![[CRF] = Q.R.W [TRF]](https://cdn2.slideserve.com/5156157/slide1-dt.jpg)