Download

1 / 24
250 likes | 376 Views
Instructional guide for E. coli O157:H7 module. This series of slides serve as a resource for using Mauve, BLAST, and the ASAP database to work on your individual projects. Welcome to the ASAP genome database. Using your web browser, #1) go to http://asap.ahabs.wisc.edu/asap/home.php.

E N D
Instructional guide for E. coli O157:H7 module This series of slides serve as a resource for using Mauve, BLAST, and the ASAP database to work on your individual projects.
Welcome to the ASAP genome database. Using your web browser, #1) go to http://asap.ahabs.wisc.edu/asap/home.php
The ASAP database houses all of the available genomes of the members of family Enterobacteriaceae Boxes, represent organisms with at least one genome sequenced as of 2010 Human Pathogens -Calymmatobacterium -Cedecea -Citrobacter -Edwardsiella -Enterobacter -Escherichia -Ewingella -Hafnia -Klebsiella -Kluyvera -Leclercia -Leminorella -Moellerella -Morganella -Plesiomonas -Proteus -Providencia -Rahnella -Salmonella -Serratia -Shigella -Tatumella -Yersinia -Yokenella Phytopathogens/ Plant-associated Insect Pathogens /Endosymbionts -Arsenophonus -Buchnera -Sodalis -Wigglesworthia -Xenorhabdus -Brenneria -Dickeya -Erwinia -Pantoea -Pectobacterium -Phlomobacter -Sacchararobacter -Samsonia Environmental/ Animals/Industrial -Alterococcus -Budvicia -Buttiauxella -Obesumbacterium -Pragia -Trabulsiella
For each genome, ASAP has information for every gene with the most up to date annotations available #1) For example lets look at the annotation page for stx2A, the gene for shiga-toxin 2 (A subunit), type stx2A into Search ASAP, and click search #2) Your search results will look like this, every gene has a Feature ID which consists of 3 capitol letters a dash and 7 numbers (Ex. ABC-1234567) #3) Click on the link that corresponds to genome EDL933 version 2 (ABH-0025275) Note: When genomes are first sequenced they are designated as version1, upon updates, the number of the version increases (ie. version2).
On the top of the page you will find some information, such as length of the gene/coding sequence and the length of the predicted protein There are also links to a variety of bioinformatics tools, you will be using the BLASTN and/or BLASTP against ASAP genomes to search in all 3 E. coli O157:H7 genomes
Further down the page are all of the annotations, such as product, comment, function, and subsystem You can see the data for each annotation type, and can click on the evidence link to see where the information was derived from (for example click on Experimental link for the first comment annotation). This will lead you to the scientific literature that supported the information for the annotation
Subsystem annotation: known or putative virulence factor When experimental or bioinformatic evidence suggests that the product of a gene is a virulence factor, the gene will have an annotation called subsystem. Examination of the subsystem annotation permits users to easily identify the main evidence that supports the role of the protein produced in virulence. Link to the supporting evidence Subsystem
Mauve To work with the 3 O157:H7 alignment, you will need to follow a few steps #1) download progressive Mauve (version 2.3.0 or later) at http://gel.ahabs.wisc.edu/mauve/download.php #2) download the compressed folder called 3 O157 alignments.zip at http://gel.ahabs.wisc.edu/~baumler/ #3) extract (uncompress) all files from the folder
In your start menu under programs go to Mauve, and start up the program. Notice there is a users guide in pdf form in this folder, this will contain useful information and commands to navigate. Note: your computer may need to update Java, since mauve uses a Java platform for the alignment. You should see a window for Mauve appear
Next double click on the uncompressed 3 O157H7 folder, it should contain the following files, take the first one (3 O157 alignment), and drag and drop it into the mauve window It should start to say reading sequences here, and in a few seconds the alignment will appear, note computers with less than 512MB RAM may not be able to open the file
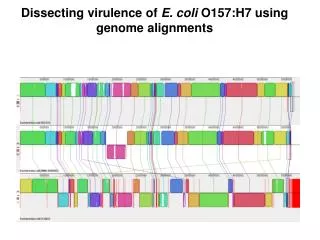
Your alignment should look like this Organism name notice the first is EDL933, the second is RIMD(Sakai), and the third is EC4042 (spinach) Using the up or down arrows, you can switch the position of the genomes
Your tool bar is at the top on the left, the tools you will use are in the View pulldown, and also the buttons Returns the viewer back to home Search for features Zoom in/out, you can also hold down the ctrl button and use the arrows on the keyboard Move left or right, you will find this useful to center a region of interest in the middle of the screen prior to zooming in
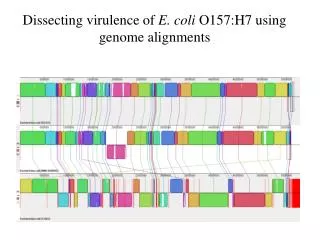
Top strand Bottom strand The colored blocks are called local colinear blocks (LCB’s), and represent regions of the genome that Mauve has identified as conserved. The lines connect the LCBs, notice that some are in different positions in the other genomes, and some are inverted and appear on the bottom strand of the double stranded genome.
When you move you mouse over a region of one genome it will show a box with a black border, and also show the corresponding region (boxes) in the other two genomes. Try scrolling left to right on one genome.
When viewing the LCB’s, mauve displays regions that are highly conserved/identical as full color. Areas that are unique/variable to one genome appear in white, and represent unique islands.
Notice, that when you scroll (slowly) over a white region (island) the black boxes pause in the other genomes. It then reappears once you have passed over the island and back into conserved regions.
If you would like to look at all three LCB’s, even though one is in a different position, scroll over one LCB and click the mouse button.
To use the zoom function, first press the home button to restore the alignment to original view. Now click on the white island in the top genome, and using the right button on your mouse bring it to the center of the screen. Now start to zoom in multiple times until boxes start to appear under the LCBs. You will start to see the genes that are predicted to encode proteins otherwise known as Open Reading Frames (ORFs). Scroll over an ORF and pause, then a window will pop-up and provide information for the product annotation. With this approach, you can view what ORFs are present in this EDL933 island, and not in the other two genomes.
Now place you mouse over one of the ORFs, in this example iha:irgA homolog adhesion has been chosen. Then, click your mouse once on the ORF, and a window will pop-up. Next, scroll down and select View CDS iha in ASAPdb. This will open the a page in the ASAP database for the selected ORF , containing all of the annotations. You can look to see if any of the annotations provide some evidence to suggest it may be involved in virulence. (note you may be prompted to a log-in screen, click on the button that says “Enter ASAP”)
To use the search feature: #1) Click on the search feature #2) Choose a genome (For example EDL933) #3) Type in a gene name (For example stx2A) #4) Click on search
Notice that it has found the stx2A gene (highlighted in blue), and also in the RIMD strain. Just because it isn't aligned in the EC4042 strain does not mean it isn't there, There may be multiple copies, for example if you look to the right in the EC4042 genome, you will find it one. Stx2A
One last feature you can use in Mauve To find a genomic island that is in two out of three strains you will switch the view of the genome alignment from LCB to backbone view. Press the home button first Then go to the View pull down select color scheme then backbone color
Your alignment should look like this in backbone color, regions in all three appear in light purple color ( ). There will be regions that are other colors that will correspond to regions conserved in 2 out of 3 genomes (you may have to zoom in a bit to see these regions). Regions in only EDL933 and RIMD appear olive green ( ) Regions in only EDL933 and EC4042 appear maroon ( ) Regions in only RIMD and EC4042 appear tan/brown ( ) This is how you identify genomic islands unique to 2 out of 3 strains
Congratulations, you should be able to work on your individual assignments with your newfound knowledge using Mauve and the ASAP database. One other useful commands in mauve: To export the current view as an image file press Ctrl+E (for presentations or to make illustrations for your assignment) Additional information is available in the Mauve users guide For additional background information on using BLAST, an online tutorial can be found at: http://www.ncbi.nlm.nih.gov/Education/index.html