Download

1 / 82
820 likes | 826 Views
Inteligentni informacioni sistemi II deo (OLAP, data mining, BI). OLAP kocke Data mining algoritmi O BI sistemima. Beograd, 2016/2017. OLAP sistemi OLAP arhitektura OLAP interfejsi Studija slučaja. OLAP kocke. OLAP sistemi.

E N D
Inteligentni informacioni sistemi II deo (OLAP, data mining, BI) OLAP kocke Data mining algoritmi O BI sistemima Beograd, 2016/2017.
OLAP sistemi OLAP arhitektura OLAP interfejsi Studija slučaja OLAP kocke
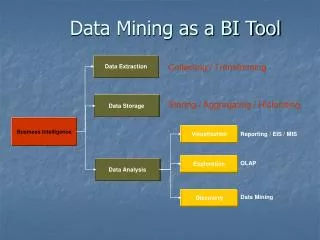
OLAP sistemi • OLAP (On-line Analytical Processing) rešenja omogućavaju korisnicima brz i fleksibilan pristup kombinovanim višedimenzionalnim podacima izvučenih iz skladišta podataka • OLAP kocke su upiti (queries) nad skladištem podataka • Poslovni podaci su uskladišteni u OLAP kocku • Podaci se analiziraju sa različitih perspektiva • Podaci su modelovani da odgovaraju poslovanju • OLAP kocka odgovara na pitanja, npr: • Da li se dešava isti šablon svake godine? • Da li se može posmatrati na drugačiji način?
Cubing servisi – OLAP analitika • MDX (MultiDimensional eXpressions) – visoko funkionalna sintaksa za postavljanje upita nad multidimenzionalnim podacima
Različite perspektive kocke kroz studiju slučaja Beograd Novi Sad Dimenzija Tržište Niš Veš mašine Frižideri Skoplje Klima Dimenzije Proizvodi Televizori Q1 Q2 Q3 Q4 Dimenzija Vreme
Pravljenje upita nad kockom Fakti o prodaji Beograd Novi Sad Dimenzija Tržište Niš Veš mašine Frižideri Skoplje Klime Dimenzija Proizvodi Televizori Q4 Q1 Q2 Q3 Dimenzija Vreme
Definisanje “kriške” (engl. slice) ili podskupa kocke Beograd Novi Sad Dimenzija Tržište Niš Veš mašine Frižideri Skoplje Klime Televizori Dimenzija Proizvodi Q4 Q1 Q2 Q3 Dimenzija Vreme
Različiti pogledi na iste podatke Mesec Grad P r o i z v o d Svi gradovi i meseci za jedan proizvod Svi proizvodi i meseci za jedan grad Svi proizvodi i gradovi za jedan mesec
Rad sa dimenzijama i hijerarhijama • Dimenzije vam dozvoljavaju • Slice • Dice • Hijerarhije vam dozvoljavaju • Drill Down • Drill Up
Interfejsi OLAP kocke • Upiti (Query) – mogućnost kreiranja sopstvenih izveštaja • Izveštavanje i dashboard (kontrolna tabla) – prikaz bilo kog predefinisanog izveštaja i ključnih org. podataka u realnom vremenu koji omogućavaju drill down i druge OLAP opcije • Analize – mogućnost višedimenzionalne analize, poređenja ... • Scorecarding– metrike ključnih poslovnih indikatora, pomaže korisnicima da shvate šta se dešava, ko je odgovoran i ko preduzima akciju ... • Upravljanje događajima (Event management)
OLAP arhitekture ROLAP MOLAP Kombinovana arhitektura
Data mining i otkrivanje znanja Tradicionalni vs evolutivni pristup Data mining proces Data mining modeli Otkrivanje znanja i data mining
Data mining i otkrivanje znanja • Data mining je proces otkrivanja skrivenih veza između vrednosti atributa i pronalaženja obrazaca (šablona) ponašanja iz ogromnih količina podataka • Proces otkrivanja znanja (Knowledge Discovery in Databases - KDD) uzima sirove rezultate iz data mining-a i transformiše ih u korisne i razumljive informacije
Data mining • Tipična pitanja koja se postavljaju sistemu: • Kakav je profil mojih klijenata? • Na koje klijente treba da ciljam u promociji? • Koje proizvode/usluge treba da promovišem? • Ko će se od mojih klijenata sigurno odazvati promociji? • Kako da poboljšam lojalnost kupaca? • Koji artikal će kupci najverovatnije kupiti? • Kako mogu da otkrijem potencijalne prevare? • ...
Primene Data mininga • Reklamiranje na Internetu • Klasifikovanje grupa klijenata sa sličnim informacijama • Praćenje kretanja klijenata na Internetu i otkrivanje njihovih želja • Pretraživanja istih obrazaca klijenata na Internetu: “Ukoliko vam se dopada knjiga x, proverite i sledeće ponuđene knjige”. • Upravljanje kreditnim rizikom • Predviđanje da li je klijent dobar ili rizičan za davanje kredita
Data mining algoritmi • Nekoliko tehnika data mininga omogućava identifikovanje obrazaca u ogromnom broju podataka • Neki modeli su: • Drvo odlučivanja • Pravila asocijacije • Naivni Bajes (Naive Bayes) • Klastering • Vremenske serije • Neuronske mreže • Text Mining • Linearne regresije
Pravila asocijacije • Pravila asocijacije (Association Rules) – pomaže u identifikovanju relacija između različitih elemenata • grupiše po sličnosti, odnosno koristi se za pronalaženje grupe artikala koji se najčešće zajedno događaju u jednoj transakciji • Koji zapisi se podudaraju sa datim pravilom? (ciljani marketing) • Koja pravila se poklapaju sa istim zapisom? (Amazon ponuda)
Naïve Bayes Naive Bayes • Naive Bayes – ovaj algoritam se zasniva na Bayes-ovoj teoremi koji računa uslovnu verovatnoću između ulaznih i predvidljivih promenljivih i pretpostavlja da su promenljive nezavisne. Pogodna je za otkrivanje relacija između ulaznih promenljivih i predvidljivih promenljivih. • Na primer, marketing odelenje je odlučilo da targetira potencijalne klijente slanjem flajera poštom. Žele da pošalju flajere samo onim klijentima koji će najverovatnije odreagovati. Upoređuju potencijalne klijente sa klijentima koji imaju slične karakteristike, a koji su kupili u prethodnom periodu.
Klastering • Sequence Clustering – grupiše zapise podataka koji su slični na osnovu sekvenci prethodnih događaja • Kom klasteru/segmentu pripada dati zapis? • Npr., segmentacija klijenata po sličnim karakteristikama kako se kreću kroz veb stranice jednog sajta. Ovaj algoritam može da grupiše klijente prema njihovom redosledu otvaranja stranica na sajtu kako bi pomogli u analizi korisnika i u određivanju koje su putanje profitabilnije od drugih. Ovaj algoritam se takođe može koristiti u predviđanju koju će sledeću stranicu korisnik posetiti.
Vremenske serije • Vremenske serije (Time Series) – ovaj algoritam se koristi za analizu i predviđanje vremenskih trendova • Npr., određuje procente saobraćajnih nesreća tokom praznika na osnovu broja nesreća koje su se dogodile tokom istog perioda u protekloj godini.
Neural Net Neuronske mreže • Neuronske mreže(Neural Nets) – kao što čovek uči na osnovu iskustva tako može i računar. Neuronske mreže modeluju neuronske veze u ljudskom mozgu i na taj način simuliraju učenje. • Ukoliko sastavljate podatke gde su ulazne i izlazne činjenice poznate, računar može da nauči iz tih obrazaca i postavi pravila i matematičke faktore kako bi npr., pomogao izračunavanje ili predvideo izlaznu vrednost. • Pretpostavimo da želite da prodate kola, nekoliko faktora utiče na prodajnu cenu kao što su godine, stanje, proizvođač, model itd. Analizirajući cene kola, neuronske mreže mogu da kreiraju seriju ulaznih i izlaznih faktora kako bi predvideli cenu prodaje.
Text Mining • Text Mining – analizira nestruktuirane tekstualne podatke • Veliki broj nestruktuiranih informacija (text) čini 80% informacija kompanije • Beleške call centara • Izveštaji o problemima • Izveštaji o popravkama • Potraživanja od osiguranja • E-mailovi sa klijentima • Komentari proizvoda ... • Text mining pretvara nestruktuirane informacije u struktuirane koje se mogu analizirati zajedno sa struktuiranim • Npr., kompanije mogu da analiziraju nestruktuirani podatak kao što je deo za komentare gde klijenti unose svoje utiske, zadovoljstvo o proizvodu i druge komentare
Linearna regresija • Regresija koristi postojeće vrednosti varijabli da bi se na bazi njih predvidele vrednosti ostalih varijabli. • Npr., prema istorijskim podacima klijenata, predviđaju se klijenti koji će biti najprofitabilniji u budućnosti • U ERP sistemima predviđaju se prodaja i prihodi, potreba za zalihama ... • U realnim situacijama, često ne postoji linearna međuzavisnost sadašnjih i budućih podataka. Recimo, vrednosti akcija na berzi je jako teško predvideti jer one zavise od složenih interakcija velikog broja varijabli. U tom slučaju, koriste se složene tehnike, kao što su logistička regresija, stabla odlučivanja ili neuronske mreže
Decision Trees Clustering Naïve Bayes Time Series Sequence Clustering Neural Net Association Logistic Regression Neki algoritmi Data Mining-a Linear Regression Text Mining
Studija slučaja: Text mining • Lanac restorana od svojih klijenata traži povratne informacije koristeći sledeću formu:
Studija slučaja • Podaci će biti uskladišteni u tabelu nad kojom će se postavljati upiti koji će odrediti: • Koja lokacija je naprofitabilnija? • Prosečan broj godina klijenata po lokaciji ... Međutim, šta da se radi sa kolonom komentari?
UIMA: Standard za obradu i analizu sadržaja • UIMA – Unstructured Information Management Architecture
Studija slučaja • Može se kreirati rečnik koji se zasniva na ključnim rečima
Studija slučaja • Kreira se nova kolona koja će pamtiti komentare klijenata • Sada se može kreirati upit zajedno sa drugim dimenzijama
Studija slučaja • Mogu se ekstrakovati i poštanski brojevi klijenata kako bi se uporedile adrese klijenata sa lokacijama restorana
Uvodni primer • Koji je ključni atribut za predviđanje da li će svršeni srednjoškolci upisati fakultet ili ne? • Postavljana su im sledeća pitanja: • Kog su pola? • Koliki je prihod njihovih roditelja? • Koliki im je IQ? • Da li ih roditelji ohrabruju da nastave studiranje ili ne? • Da li planiraju da upišu fakultet? • Da bi na osnovu prikupljenih podataka utvrdili koliko studenata će nastaviti školovanje, neophodno je da se postavi upit koji broji zapise studenata koji žele i onih koji ne žele da nastave školovanje.
Uvodni primer (nastavak) • Pretpostavimo da ste zainteresovani da odredite koji atribut ili kombinacija atributa imaju najveći uticaj da predvidi verovatnoću studenata koji će upisati fakultet. Ovo je složeniji upit i zahteva korišćenje tehnika data mininga. • Primenjujući algoritam drveta odlučivanja otkrivene su sledeće relacije: • Najuticajniji atribut je ohrabrivanje njihovih roditelja da upišu fakultet. Oni studenti koje roditelji ohrabruju da upišu fakultet, 60 % planira da upiše fakultet i to uglavnom oni sa visokim IQ.
Svi studenti Upisaće fakultet: 33% Da 67% Ne Ohrabrenje roditelja = Da Ohrabrenje roditelja = Ne Upisaće fakultet: 57% Da 43% Ne Upisaće fakultet: 6% Da 94% Ne Visok IQ Upisaće fakultet: 18% Da 82% Ne Nizak IQ Upisaće fakultet: 4% Da 96% Ne Visok IQ Nizak IQ Srednji IQ Upisaće fakultet: 74% Da 26% Ne Upisaće fakultet: 29% Da 71% Ne Upisaće fakultet: 9% Da 91% Ne Drvo odlučivanja Podsticaj od strane roditelja ? IQ IQ
Uvod u scenario Platne kartice • Direktor marketinga želi da oceni trenutni program platnih kartica. Da bi zadržao postojeće klijente i ispunio njihova očekivanja, želi da identifikuje mogućnosti kako bi povećao nivo usluga kod svih kartica: zlatna, srebrna, bronzana i obična • Raspoložive informacije od klijenata su pol, bračni status, godišnji prihodi, nivo obrazovanja • Da bi predvideli faktore koji utiču na izbor odgovarajuće kartice koristićemo Data mining: • Koristićemo tehniku drveta odlučivanja da bi pronašli obrazac za izbor platne kartice. • Odabraćemo Klijente kao dimenziju slučaja (case dimension). • Odabraćemo Platnu karticu kao informaciju koju će koristiti algoritam DM da bi identifikovao obrasce. • Iskoristiće se raspoložive informacije o klijentima kako bi se pronašao obrazac. • Ispitati drvo odlučivanja.