Download

1 / 19
190 likes | 341 Views
Automatic Cue-Based Dialogue Act Tagging. Discourse & Dialogue CMSC 35900-1 November 3, 2006. Roadmap. Task & Corpus Dialogue Act Tagset Automatic Tagging Models Features Integrating Features Evaluation Comparison & Summary. Task & Corpus. Goal:

E N D
Automatic Cue-Based Dialogue Act Tagging Discourse & Dialogue CMSC 35900-1 November 3, 2006
Roadmap • Task & Corpus • Dialogue Act Tagset • Automatic Tagging Models • Features • Integrating Features • Evaluation • Comparison & Summary
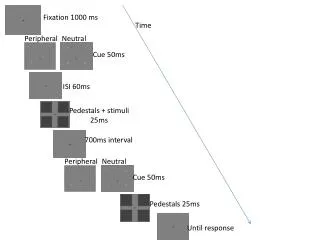
Task & Corpus • Goal: • Identify dialogue acts in conversational speech • Spoken corpus: Switchboard • Telephone conversations between strangers • Not task oriented; topics suggested • 1000s of conversations • recorded, transcribed, segmented
Dialogue Act Tagset • Cover general conversational dialogue acts • No particular task/domain constraints • Original set: ~50 tags • Augmented with flags for task, conv mgmt • 220 tags in labeling: some rare • Final set: 42 tags, mutually exclusive • Agreement: K=0.80 (high) • 1,155 conv labeled: split into train/test
Common Tags • Statement & Opinion: declarative +/- op • Question: Yes/No&Declarative: form, force • Backchannel: Continuers like uh-huh, yeah • Turn Exit/Adandon: break off, +/- pass • Answer : Yes/No, follow questions • Agreement: Accept/Reject/Maybe
Probabilistic Dialogue Models • HMM dialogue models • Argmax U P(U)P(E|U) – E: evidence,U:DAs • Assume decomposable by utterance • Evidence from true words, ASR words, prosody • Structured as offline decoding process on dialogue • States= DAs, Obs=Utts, P(Obs)=P(Ei|Ui), trans=P(U) • P(U): • Conditioning on speaker tags improves model • Bigram model adequate, useful
DA Classification -Words • Words • Combines notion of discourse markers and collocations: e.g. uh-huh=Backchannel • Contrast: true words, ASR 1-best, ASR n-best • Results: • Best: 71%- true words, 65% ASR 1-best
DA Classification - Prosody • Features: • Duration, pause, pitch, energy, rate, gender • Pitch accent, tone • Results: • Decision trees: 5 common classes • 45.4% - baseline=16.6% • In HMM with DT likelihoods as P(Ei|Ui) • 49.7% (vs. 35% baseline)
DA Classification - All • Combine word and prosodic information • Consider case with ASR words and acoustics • P(Ai,Wi,Fi|Ui) ~ P(Ai,Wi|Ui)P(Fi|Ui) • Reweight for different accuracies • Slightly better than raw ASR
Integrated Classification • Focused analysis • Prosodically disambiguated classes • Statement/Question-Y/N and Agreement/Backchannel • Prosodic decision trees for agreement vs backchannel • Disambiguated by duration and loudness • Substantial improvement for prosody+words • True words: S/Q: 85.9%-> 87.6; A/B: 81.0%->84.7 • ASR words: S/Q: 75.4%->79.8; A/B: 78.2%->81.7 • More useful when recognition is iffy
Observations • DA classification can work on open domain • Exploits word model, DA context, prosody • Best results for prosody+words • Words are quite effective alone – even ASR • Questions: • Whole utterance models? – more fine-grained • Longer structure, long term features
Automatic Metadata Annotation • What is structural metadata? • Why annotate?
What is Structural Metadata? • Issue: Speech is messy Sentence/Utterance boundaries not marked Basic units for dialogue act, etc Speech has disfluencies • Result: Automatic transcripts hard to read • Structural metadata annotation: • Mark utterance boundaries • Identify fillers, repairs
Metadata Details • Sentence-like units (SU) • Provide basic units for other processing • Not necessarily grammatical sentences • Distinguish full and incomplete SUs • Conversational fillers • Discourse markers, disfluencies – um, uh, anyway • Edit disfluencies • Repetitions, repairs, restarts • Mark material that should be excluded from fluent • Interruption point (IP): where corrective starts
Annotation Architecture • 2 step process: • For each word, mark IP, SU, ISU, none bound • For region – bound+words – identify CF/ED • Post-process to remove insertions • Boundary detection – decision trees • Prosodic features: duration, pitch, amp, silence • Lexical features: POS tags, word/POS tag patterns, adjacent filler words
Boundary Detection - LM • Language model based boundaries • “Hidden event language model” • Trigram model with boundary tags • Combine with decision tree • Use LM value as feature in DT • Linear interpolation of DT & LM probabilities • Jointly model with HMM
Edit and Filler Detection • Transformation-based learning • Baseline predictor, rule templates, objective fn • Classify with baseline • Use rule templates to generate rules to fix errors • Add best rule to baseline • Training: Supervised • Features: Word, POS, word use, repetition,loc • Tag: Filled pause, edit, marker, edit term
Evaluation • SU: Best combine all feature types • None great • CF/ED: Best features – lexical match, IP • Overall: SU detection relatively good • Better on reference than ASR • Most FP errors due to ASR errors • DM errors not due to ASR • Remainder of tasks problematic