Download

1 / 62
640 likes | 881 Views
Философия на алгоритмизирането ( design techniques) ще разгледаме: постъпателни алг., алгоритми с “разделяй и владей”,подобрения в математ. операции, динамично програмиране, алгоритми с backtracking, елементи от теория на игрите 1. Постъпателни алгоритми ( greedy algorithms).

E N D
Философия на алгоритмизирането(design techniques)ще разгледаме: постъпателни алг., алгоритми с “разделяй и владей”,подобрения в математ. операции, динамично програмиране, алгоритми с backtracking, елементи от теория на игрите 1. Постъпателни алгоритми (greedy algorithms) работят поетапно. На всеки етап се взима изглеждащото за най-добро решение, независимо от последиците. Т.е. : локален оптимум. Или стратегията е “take what you can get now”. В края на алгоритъма приемаме, че локалния съвпада с глобалния оптимум. (без гаранция) пример за това е стратегията на връщане на монети: връща на всеки етап монета с мак. възможна стойност $17.61 1*$10 +1*$5 +2*$1 + 2*0.25(quarters) +1*0.1 (dime) + 1*0.01(penny). Този алгоритъм не работи във всички монетарни системи. Друг пример: авт. трафик ( не винаги работи оптимално).
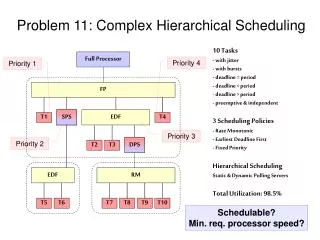
1.1simple scheduling problem • имаме дадени задачи j1 …jN с времена на изпълнение t1…tN и 1 процесор. Искаме разпределяне с цел мин. средно време на завъшване на задача (т.е. на коя мин. средно завършва задача). (няма прекъсване на задача). Задача време • j1 15 • j2 8 j1 j2 j3 j4 • j3 3 • j4 10 0 15 23 26 • Първата завършва след 15, втората след 23, третата след 26, след 36 общо 100 мин/4 = 25 средно ще завършва задача. • Друга подредба е показана по-долу: средно време 17.75 j3 j2 j4 j1 0 3 11 21 36
Стратегията е най-късата задача – най-напред(участва най-много във формиране времената за следващите задачи).Това винаги дава оптимално решение. Нека първата пусната задача е j i1…j iN с времена на завършване: t i1, t i1+t i2, t i1 +t i2 +t i3. Цената на разпределението става:N C = (N-k+1)tik “С” е оценката за направения график k = 1 N N C= (N+1) tik - k*tik k = 1 k = 1I член не зависи от подредбата, а само втория (“к”). Ако предположим, че в подредба съществува x >y, такова че tix<tiy, то ако разменим местата на jix и jiy, втория член нараства и следоват. общата цена намалява. Следоват. всяка подредба в която работите не са наредени в нарастващ ред е неоптимална.Затова и ОС sheduler дава приоритет на най-късите задачи първо.
многопоцесорен вариантИмаме j1……jN; ti….tN и P процесора. Нека подреждаме първо на късите задачи. Нека Р=3:задача времеj1 3j2 5j3 6j4 10j5 11j6 14j7 15j8 18j9 20едно решение (започваме с къси задачи и циклим по процесори):j1 j4 j7 j2 j5 j8 j3 j6 j90 3 5 6 13 16 20 28 34 40Общо време на завършване 165. Средно 165/9 = 18.33
Друга стратегия (когато Р дели N точно) е: за всяка група 0<= i < N/P неразпределени най-къси задачи, избираме случайно един от процесорите. J1 j5 j4 j2 j4 j7 j3 j6 j80 3 5 6 14 15 20 30 34 38ако целим:минимизация на крайното време на завършване на всички задачипо-горе това е 40 или 38. Ето подредба с t = 34: j2 j5 j8 j6 j9 j1 j3 j4 j70 3 5 9 14 16 19 34очевидно тази подредба не може да се подобри, защото всички са заети през цялото време. Това обаче е друга стратегия – най-късо общо завършване. Има много възможни стратегии
1.2 Кодове на Huffman ( компресия на файл.)Нормално ASCII има 100 печатащи се символа log100 =7 бита + 1 бит контрол по четност.Т.е. за С символа са нужни logC бита за кодиране.Нека във файл имаме само символи a,e,I,s,t,blank, NL. Нека след статистика знаем че във файла има 10 –a; 15 e; 12 I; 3 s; 4 t; 13 blanks; 1 ML. Нужни са 174 бита за съхраняване на поредицатабуква код честота общо битаa 000 10 30e 001 15 45I 010 12 36s 011 3 9t 100 4 12space 101 13 39NL 110 1 3общо 174
Ще представим стратегия постигаща за нормален файл 25% пестене, и 60% за дълги файлове. Варираме с д-ната на кода за различните символи. Най-честите с най-къс код. При еднаква честота – няма значение кой.Ето едно дърво, даващо начин за кодировка на нашата азбука от 7 символа: 0 1 1 a e I s t sp nlДанни има само в листата.Кодировката е еднозначнаАко символ c i е в дълбочина d i,и се среща f i пъти, то общата цена на кодираната инф. е d I * f i.
Едно подобрение става при свиване дълбочината за възли с 1 листо: nl a e I s t spОбщата цена става 173, което изобщо не е подобрение.Винаги работим с пълно бинарно дърво. Иначе редуцираме ..При символи само в листата, всяка последователност от 0 и 1 е еднозначна и може да се декодира. Това е != от т.нар. префиксно кодиране.Проблемът се сведе до: намиране на fullbinarytree с мин. цена, в което символи има само по листата. Ето оптималното за примера (цена 146): e I sp a t s nl виждаме колкото по-често, толкова по-горе.
Символ код честота общо-битовеa 001 10 30e 01 15 30 I 10 12 24s 00000 3 15t 0001 4 14space 11 13 26NL 00001 1 5общо 146Има не един оптимален код. Напр. ако разменим деца в листа…Хофман през 1952 дава алгоритъм за кодиране.Алгоритъм на HuffmanИмаме С символа.Правим набор дървета. “Тегло “ за дърво се получава от сума на честотите в листата му. С-1 пъти избираме 2 дървета Т1 и Т2 с мин. тегла и ги обединяваме. В началото имаме С дървета с по 1 възел.В края на алгоритъма имаме 1 дърво и това е оптималното кодово дърво.Ето за нашия пример:
начало:10 15 12 3 4 13 1 а е I s t sp nlпърво обединение ( няма значение кое е ляво, така че реализиращата процедура няма да прави връщания назад). Теглото на новополученото д-во е сума: 10 15 12 4 13 4 T1 a e I t sp s nlРеализацията в програма е лесна: правим нов възел, установяваме 2 указателя и изчисляваме тегло.продължаваме: T2 8 T1 t 10 15 12 13 s nl a e I sp T3 18 T2 a 15 12 13 T1 t e I sp s nl
18 T3 T2 a T4 25 T1 t e 15 I sp s nl 33 T5 T3 e T2 a T4 25 T1 t I sp s nlкраят ( след обединението) беше вече показан
Хофмановият алгоритъм води до оптимален код – някои разсъждения:1. полученото д-во е пълно То не може да се подобрява с местене възли нагоре.2. 2 букви (напр. “а, б” )с мин. честота винаги са най-долу. Доказваме с използване на обратно твърдение: ако това не е така , (поне едното от а и б не е в най-дълбоко листо), то има някакво г (дървото е пълно) което е там. Но щом а е по-рядко срещано от г, то най-лесно ще подобрим общата цена като разменим а и г .3. Очевидно, 2 символа във възли с еднаква дълбочина могат да се разместват без променяне на оптималния избор. 4. Всъщност сливайки дървета, можем да считаме че сливаме символи и метасимволи( пр. е, Т4, Т3), които имат мин. честота. Алгоритъмът работи еднотипно, при това позволявайки разширения в азбуката.5. Крайните символи изграждащи сливаните поддървета (напр Т3 и Т4) са кодирани с повече битове винаги са по-дълбоко в резултатното. Но те са и по-рядко срещани от е.Алгоритъмът е greedyзащото на всеки етап правим сливането без оглед на глобалната оптимизация, а само в локален оптимум.** Разбира се кодиращата инф. следва да се изпрати в началото на файла при трансмисия за да е възможно декодиране. За малки файлове това е лошо (много добавена инф.).*** Алгоритъмът е двупасов – първо се събират данни за честотата, после се кодира. За големи файлове това не е добре – има подходи за обединяване задачите.
1.3 Проблемът “пакетиране”Тези алгоритми са бързи, но не винаги дават оптимално решение. Имаме N пакета с размери s1….sN (0 <= si <1). Искаме да ги пакетираме в min брой торби, като всяка торба има обем 1. Ето пример:0.8 0.3 0.5 0.1 0.2 0.7 0.4B1 B2 B3Съществуват 2 версии на решения:on-line всяка единица се поставя преди следваща (няма връщане назад). Off-line – първо изследваме всички, тогава започваме пакетирване.On-line алгоритмиНе винаги дават оптималното решение. Напр.-имаме поредица от I1 ел.от общо М с тегло ½ -б, следвани от останалите с тегло ½+б (б е нещо малко): очевидно, всички могат да се пакетират в М (1 малка + 1 голяма). Нека алгоритъм А прави това пакетиране. Тогава А ще постави малките I1 (половината) ел. всеки в отделен чувал (а не по 2) – общо напр. в М торби. Но как ще знае че следващите са по-големите, а не обратно. Значи А винаги ползва 2М торби вместо М.Или ако знае размер на малките, то при вх. поредица само от малки, ще ползва 2М торби (грешно). Алгоритмите от този вид дават само локална гаранция.
Теорема 1съществуват вх. поредици, които карат който и да е on-line алгоритъм да използва поне 4/3 от оптималния брой торби (M).Док. Предполагаме обратното и нека М е четно. Алгоритъм А обработва входната поредица I1(както горе- М малки ел., следвани от М големи). Вече сме обработили първите М ел. и сме използвали б торби. (знаем, че оптимално би било б=М/2, защото оптималният алг. би поставил 2 ел./торба). Т.е за всичките ел., алгоритъмът ще постигне :2б < 4/3M; или 2б/М < 4/3 или б/М <2/3От друга страна: Нека всички елементи са пакетирани. Имаме б торби с първите б ел. Алгоритъмът не може да постави по 2 от следващите големи ел. в 1 торба. Тогава след края на алгоритъма, първите б торби (те може да са < половината) ще имат най-много по 2 ел. (може 2 малки или в някои - малък и голям, докогато това е възможно), а в последащите -само по 1. За 2М ел. (които оптимално се редят в М торби) ще са нужни поне 2М – б торби. (2М – б) / М < 4/3 (съгласно допускането). Т.е. б/М >2/3Имаме противоречие. Следователно няма on-line алгоритъм, даващ по-добро от 4/3 спрямо оптималното решение.
Има 3 алгоритъма , гарантиращи че броят използвани торби не надхвърля двукратно оптималния. Nextfitпроверяваме дали следващият ел. в поредицата може да се постави в торбата, която съдържа последния ел. ако не – нова торба.Работи с линейно време.Ето резултат над предходната поредица: 0.1 0.5 0.7 0.3 0.8 0.2 B10.4 B2 B3 B4 B5Т2 Нека М е оптималния брой торби за пакетиране на I ел. Nextfit никога не използва повече от 2М торби.Док. Разглеждаме 2 съседни торби: Bj и B j+1:Сумата от обемите в тях е >1, иначе в 1 торба. Aко направим тези разсъждение за всички съседни, виждаме че най-много ½ пространство е похабено. Използвани са най-много двукратен брой торби.Ето най-лоша последователност на входа:нечетни si имат размер 0.5, четни – размер 2/N. Нека N се дели на 4. Оптимално пакетиране е от N/4 +1.Реалното в този алгоритъм заема N/2. T.e почти двойно:
0.5 0.5 0.5 2/N 2/N 0.5 0.5 0.5 2/N B1 B2 …. Bn/4 B n/4+1оптимално пакетиране за поредицата 2/N … 2/N 0.5 0.5 B1 B N/2 Next fit пакетиране за същата поредица(почти двойно)
First FitПредишният алгор. създава нова торба не винаги когато това е нужно, защото разглежда само последната. Напр. за схемата горе, ел. 0.3 може да се постави в В1 или В2 а не в нова.FirstFit стратегията сканира торбите подред за да установи дали може да постави новия ел. 0.1 0.5 0.3 0.7 0.8 0.2 B1 0.4 B2 B3 B42Тъй като се сканират предходните торби, О(N ). Може да се сведе до O(NlogN) – ако сканираме както при бинарно търсене.Във всеки момент най-много 1 торба може да е запълнена до ½, тъй като ако са 2, то съдържанието им може да се постави в 1. Значи най-много 2М спрямо оптимумът от М торби.
Best FitВместо да поставяме нов елемент в първа възможна торба, го поставяме там където е възможно , но и има най-малко свободно място.Ето резултата 0.3 0.1 0.5 0.7 0.8 0.2 0.4B1 B2 B3 B4Елемент с тегло 0.3 е поставен в В3, а не в В2. Има подобрение, но не и за лошите поредици. Затова ограниченията остават същите – 1.7 от оптимума
Off-line алгоритмиСега можем да аналзираме цялата поредица, преди да подреждаме.Големият проблем на on-line алгоритмите е че не пакетират добре големи ел. когато те идват към края. Добре би било големите да ги сортираме отпред.Това е алгоритъмът firstfitdecreasing: 0.2 0.3 0.1 0.4 0.8 0.7 0.5B1 B2 B3В случая това е и оптималното решение. Не винаги е така.Значи считаме, всички ел. са вече подредени намаляващо.Ще докажем, че ако оптимално пакетиране изисква М торби, сега са нужни не-повече от (4М + 1)/3 торби.
Лема 1Нека N ел. (сортирани намаляващо) с размери s1…sN могат да се подредят оптимално в М торби.Тогава всички ел., които firstfitdecreasing поставя в допълнителни торби (над М) имат размер най-много 1/3.Док.Нека елемент i е първия в торба М+1. Да докажем si <=1/3. Предполагаме обратното:si >1/3. Следва, че s1,…si-1 >1/3 (иначе лемата е доказана). Търсим къде може да има разхищение в нашия алгоритъм?В торби В1….ВМ има най-много 2 елемента ( нали са >1/3).Тогава в първите няколко торби може да има по 1 (голям) ел. а в оставащите до М по 2 ел.Нека приемем обратното: в торба Вx има 2 ел., а в торба By 1 el. и 1<= x < y <= M. Некаx1 и x2 са елементите в Вx и y1 е елементът в By, x1>=y1, а също и x2 >=si. Тогава:x1 +x2 >= y1 +siЗначи,ако в началните торби имаше по 2 елемента, то и този с siможе да се пъхне в By,заедно с y1, макарда е >1/3. Но това не беше възможно по предположението.# Следователно:ако si>1/3, в момента, когато го обработваме,алгоритъмът е поставил в първите j торби по 1 ел. а в оставащите M-j по 2 ел.
Сега да покажем че няма начин всички елементи да се сложат в М торби(щом първият оставащ след началното заемане на М торби е >1/3)За първите j ел. няма алгоритъм 2 да се сложат в 1 торба (ако можеше, first fit също щеше да го е направил ). Също така никой елемент до si не може да се пъхне в първите торби. Значи j торби са по 1 ел. и елементите с размери sj+1,s j+2…. S i-1 са в следващите М-j торби, по 2. Общият брой ел. в тях е 2(М – j)(ако някъде бяха по 3, лемата вече е доказана)Следователно, елемент si( който предположхме е >1/3) няма начин да се вкара в първите М торби :- няма алгоритъм, който да го вкара в първите j торби, защото ако можеше First fit алгоритъмът щеше да го е направил. - Не може и в оставащите M-j торби, защото в тях трябва да се появят 2(M-j) +1 елемента. Това означава в някоя торба следва да има по 3 ел (а всеки беше >1/3). Но след като има алгоритъм, който би направил пакетиране в М торби, то очевидно допускането че Si >=1/3 е грешно.Очевидно предвиждането в началото беше грешно и si <=1/3
Лема 2Броят ел. поставени в допълнителните торби е най-много М-1Док:Приемаме обратното: в допълнителните торби има най-малко М ел.Знаем:Nsi <= M (общият обем при оптим. подреждане= М торби * размер 1 торба, който сме приели за 1)i=1Нека торба Bj е поела общо тегло Wj (1<= j <= M)Нека първите М ел. в допълнителни торби са с размер x1…xM. Тъй като елементите в първите М торби + елементите в първите М допълнителни са част от всички то:N M M M si >= Wj + xj >=(Wj +xj)i=1 j=1 j=1 j=1Wj +xj >1 защото иначе xj щеше да се вкара в Bj. Тогава:N M si > 1 > Mi=1 j=1Това е невъзможно, тъй като тези N ел. могат да се пакетират в М торби. Следователно допълнителните торби са най-много М-1
ТеоремаНека М е оптималният брой торби за i елемента. FirstFitdecreasing никога не използва повече от (4М+1)/3 торби.Имаме М-1 допълнителни ел. с размер най-много 1/3.Значи допълнителните торби са най-много (М-1)/3.Общият брой торби използвани в метода е :М + ( М -1 )/ 3 == (4М –1) /3 <= (4М +1)3First Fit decreasing е добър и бърз подход
Разделяй и владейтрябва да има поне две рекурсивни обръщения в програмата2.1 Анализ на времето на изпълнениевреме за изпълнение на частите + константно време на излъчване крайния резултат:T(N)= 2T(N/2) +O(N), знаем с оценка:О(NlogN)Теорема кРешението на у-нието T(N) =aT(N/b) + O(N )при а>=1; в >1 е: (а–броят на задачите; в–частите, k: t обед.,около logb a)log a b kO(N )зaa>b k kT(N) = O(NlogN) за а = b //най-често k kO(N ) за a<b
Док: m m-1 k m k mk kmНека N = b (най-често). Тогава N/b = b и N = (b ) = b = b k m =(b ) .Aко T(1) =1, то имаме:m m-1 k mT(b ) = aT(b ) +(b )делим на a ^m :m m m-1 m-1 k m T((b ) / a = T(b )/a +{ b /a }ако продължим за останалите m:m-1 m-1 m-2 m-2 k m-1T(b )/a =T(b )/a +{b /a} m-2 m-2 m-3 m-3 k m-2T(b )/a = T(b )/a +{b /a }…. … 1 1 0 0 k 1 T(b )/a = T(b )/a + {b /a}сумираме отляво и отдясно:m m m k i m k i T(b )/a = 1 + {b /a}= {b /a } i=1 i=0
следователно:m m m k ikT(N) = T(b ) =a {b /a}aко а>b ,i=0то сумата е геом. намаляваща серия . Сумата й води към конст.: m log b N log b aT(N ) =O(a ) =O(a) =O(N )//увеличили сме3 2//основата, намалили сме степента, напр 2 < 3k kако а = в, всеки член =1.Членовете са 1 + log b N (=m) на брой и a =b log ba = k: m log b a k kT(N) = O(alog bN) = O(NlogbN) = O(Nlog bN) = O(Nlog b N) kи ако а< b , то членовете са геом. серия в която всеки е >1 и като вземем предвид формулата от първата лекция за редици: N I N+1A =(A - 1)/ (A-1) i=0то получаваме за случая: m k m+1 k m k m k m kT(N)= a ((b /a ) -1) / ((b /a) –1) = O(a (b /a) ) = O((b ) )= O(N )
Това са и 3 случая на рекурентно разбиване на задача на подзадачи.*Напр. сортировка чрез разделяне и сливане : a=b=2; k=1. Имаме втория случай и отговор: O(NlogN)*Ако имаме 3 проблемаи всеки е над половината данни и комбинирането за краен резултат изисква O(N) време, то a=3,b=2, k=1. log 2 3 1.59 Имаме случай 1 и O(N)= O(N ) 2*Ако в горния пример времето за обединяване на резултата беше O(N ), то сме във случай 3 и: 2 O(N )
2.2 Прoблемът “най-близкостоящи точки”Имаме Р точки в равнината, p1=(x1,y1)…..Разстоянието м/ду тях : 2 2 1/2 [(x1 –x2) + (y1-y2) ]Търсим най-близкостоящите 2 точки. 2Имаме N(N-1)/2 разстояния. Пълен тест: O(N )Друг подход: Нека точките са сортирани по x координатата си. Ако не са, допълнително време O(NlogN):
Разделяме ги по вертикала на 2 равни части P LP R: dc d L d R Най-късото разстояние е или вляво, или в дясно или частично в ляво и частично в дясно (показани са 3-те възможности)
dl и dr могат да се изчислят рекурсивно ( O(NlogN) . Остава да изчислим dc за O(N) време и да постигнем:O(NlogN) +O(N)Нека б=min(dl,dr). Ще изчисляваме dc само ако подобрява б. P1 p2 dL p3 p4p3 p5 p6б бПри равн. разпред.,точките в лентата са малко: една по една ( O(N) )://за точките от лентатаfor(I=0;i< numPoinsInStrip; I++) for (j=i+1; j<numPoinsInStrip;j++) if(dist(pi,pj) <б)б = dist(pi,pj);ако точките в лентата са много (почти всички), горния подход е слаб.
Нека точките са сортирани в лентата по у коорд. Интересуват ни точки с у координати, различаващи се най-много с б. Ако коорд. На pi и pj се разл. с повече от б, можем да преминем към p i+1 (Ускорен вариант ):for(I=0; I<numPoinsInStrip; I++) for( j=I+1; j< numPointsInStrip; j++) if(pi and pj’coordinates differ by more than б) break; // next pi. else if(dist(pi,pj)<б) б = dist(pi,pj);Тогава виждаме (спрямо p3)само p4 и p5 се разглеждат:dL p1 p2 p3 p4б dR p5 p6 p7 б б
Всъщност, за всяка т. pi, най-много 7 т. могат да се разглеждат в правоъгълната област б *2б:pL1 pL2 pR1 pR2б х б б х бpL3 pL4 pR3 pR4Времето за търсене на dc , което да е < б е O(N). Имаме О(NlogN) от рекурсивните повиквания отляво и отдясно + O(N).За сортирането по у е нужно още O(NlogN) за всяко рекурсивно2 2повикване или общо O(NlogN). (пълно претърсване: O(N ).Mожем още да ускорим като предварително сортираме и по x и по у и изработим 2 списъка с точки (сортирани по x и по y). ( O(NlogN) време в началото ). После претърсваме списъка по x и махаме всички точки с коорд. > б. Автоматично остават само тези в линията и то сортирани по у. Това изисква O(N). общо време O(NlogN) +O(N)
2.3 Теоретични подобрения с аритметични задачи* Умножение на цели числа- За малки ч-ла - линейно време. - За големи, времето става квадратично.Нека имаме N р-дни ч-ла X и Y. Знакът определяме лесно. 2По класически алгоритъм O(N ) : всяка цифра на X се умножава по всяка на Y.Нека: X= 61,438,521 Y=94,736,407 XY=5,820,464,730,934,047Разбиваме X и Y: Xl= 6,143 Xr= 8,521Yl= Yr=4 4X=Xl*10+Xr; Y=Yl*10+Yr8 4XY=Xl Yl 10 +(Xl Yr + Xr Yl)* 10 +Xr YrИмаме 4 умножения с N/2 цифри:T(N)= 4T(N/2) + O(N)според теоремата в началото на лекцията, това е:2O(N ) - нямаме подобрене.Трябва да намалим броя умножения. Разбиваме:
XlYr + XrYl= (Xl– Xr)(Yr – Yl) +XlYl +XrYr1 умножение + 2 умножения – но вече изчислени.Функция стойност сложност при изчисл.Xl 6,143 дадениXR,YL,YR8,521,… дадениD1 = XL – XR -2,378 O(N)D2 = YR – YL -3,066 O(N)XL*YL … T(N/2)XR*YR … T(N/2)D1*D2 ….. T(N/2)D3 = D1D2 + XLYL + XRYR .. O(N)XR*YR …… вече изчисленоD3*10^4 …. O(N)XLYL*10^8 …. O(N)XLYL10^8 + D310^4 + XRYR .. O(N) log 2 3 1.59T(N)= 3T(N/2) +O(N) = O(N ) =O(N )Пoдобрение!
** Умножение на матрици 3Ето стандартен алгоритъм с O(N )време.Matrix<int> operator*( const matrix<int> &a, const matrix<int> &b ){ int n = a.numrows(); matrix<int> c( n, n); int I; for( I = 0; I < n; i++ ) for( int j = 0; j < n; j++ ) c[ I ][ j ] = 0; // инициализация for( I = 0; I < n; i++ ) for( int j = 0; j < n; j++ ) for( int k = 0; k < n; k++ )c[ I ][ j ] += a[ I ] [ k ] * b[ k ] [ j ]; return c;}През 60 години Strassen подобрява това време. Основната идея е разбиване на матриците на 4 квадранта:
A11 A12 B11 B12 C11 C12A21 A22 * B21 B22 = C21 C22Тогава:C11 = A11B11 + A12B21C12 = A11B12 + A12B22C21 = A21B11 + A22B21C22 = A21B12 + A22B22Пример: 3,4,1,6 5,6,9,3АВ= 1,2,5,7 4,5,3,1 5,1,2,9 1,1,8,4 4,3,5,6 3,1,4,1разбиваме:A11= 3,4 A1,2 = 1,6 B11 = 5,6 B12 = 9,3 1,2 5,7 4,5 3,1A21= 5,1 A2,2= 2,9 B21= 1,1 B2,2= 8,4 4,3 5,6 3,1 4,1
8 N/2 на N/2 матрични умножения + 4 N/2 на N/2 матричнисъбирания2Събирането: O(N ).Ако матр. умножения се изпълнят в рекурсия:2T(N) = 8T(N/2) +O(N ) 3От базовата теорема в началото се вижда че това е T(N) =O(N ). няма подобрениеТрябва да намалим подзадачите под 8, (подобно на алгор. с умноженията).Strassen дава divide &conquer алгоритъм ( с разбиване, подобно на алгор с умножения) с използване на 7рекурсивни повиквания :M1=(A12-A22)(B21+B22)M2=(A11+A22)(B11+B22)M3=(A11-A21)(B11+B12)M4=(A11+A12)B22M5=A11(B12-B22)M6=A22(B21-B11)M7= (A21+A22)B11 Резултатът :C11=M1+M2-M4+M6C12=M4+M5C21=M6+M7C22=M2-M3+M5-M7log 2 7 2.81T(N) = 7T(N/2) +O(N ^2 ) = O(N ) = O( N ) Добър за големи N; Не се паралелизира лесно; Не е оптимизиран ако има 0; Въпреки това – подобрение!
3. Динамично програмиранеРекурсията не е оптималната техника в ред случаи рек. алгоритъм следва а се пренапише в нерекурсивен вариан със запомняне межд. резултати в таблица. Една техника за това е “динамичното програмиране”.3.1 таблици вместо рекурсияЕто неефективен вариант за изчисляване ч-лата на Фибоначи:int fib( in n) { if( n <= 1 ) return 1; else return fib( n – 1 ) + fib( n – 2 ); }T(N) >= T(N-1) +T(N-2)Вече изследвана в курса сложност: експоненциална
Можем, обаче, да съхраним изчислените вече Fn-1; Fn-2. :int fibonacci( int n ) { if( n <= 1 ) return 1; int last = 1; int nextTolast = 1; int answer = 1; for( int i = 2; i <= n; i++ ) { answer = last + nextTolast; nextTolast = last; last = answer; } return answer; }Имаме O(N).Ако горната модификация не е направена, за изчисление на Fn вика рекурсивно Fn-1 и Fn-2…..
Eто трасировка на рекурсиите. F6 F5 F4 F4 F3 F3F2F3F2 F2 F1 F2 F1 F1 F0F2 F1 F1 F0 F1 F0 F1 F0F1 F0Виждаме FN-3 се вика 3 пъти, FN-4 – 5 и т.н. Експлозивно нарастват сметките
3.2 oптимално бинарно търсене в дървоИмаме списък думи w1……wn с вероятности на появяване: p1…..pnИскаме да подредим думите в бинарно дърво, така че общото време за намиране на дума да min.В бинарно д-во за да стигнем до ел. с дълбочина d, правим d+1 сравнения. Така че, ако wi е на дълбочина di, ние искаме да минимизираме Npi (1+di ).I = 1дума вероятностifа 0.22 am 0.18 a twoand 0.20egg 0.05 and theif 0.25the 0.02 am eggtwo 0.08 egg and am the a ifa and if two am egg two the Greedy strategy; ^ вероатност най-горе Друга подредба: балансирано, бинарно д-во Оптимално, но неинтуитивно д-во
първото използва greedy стратегия. Най-вероятната дума е най-горе.Второто е балансирано searchtree (в дясно с по-ниско pi).Третото е оптималното – виж таблицата:вход дърво 1 дърво2 дърво3дума вероятност цена цена цена дълбоч дълб дълбочa 0.22 2 0.44 3 0.66 2 0.44am 0.18 4 0.72 2 0.36 3 0.54and 0.20 3 0.60 3 0.60 1 0.20egg 0.05 4 0.20 1 0.05 3 0.15if 0.25 1 0.25 3 0.75 2 0.50the 0.02 3 0.06 2 0.04 4 0.08two 0.08 2 0.16 3 0.24 3 0.24общо 1.00 2.43 2.70 2.15сравнение на 3 дървета с бинарно търсене
При optimalbinarysearchtree(строен по алгор. подобен на този на Hofman) данните не са само в листата (Hofman) и следва да удовлетворяваме критерий за binarysearchtree.Поставяме сортирани според някакъв критерий думи wleft, wleft+1,….wright-1, wright в бинарно дърво. Нека сме постигнали оптималното бинарно дърво в което имаме корен wiи поддървета за които : Left <= i <- RightТогава лявото поддърво съдържа елементите wleft, …wi-1,а дясното – wi+1,……wright (критерий за binary search tree ).Поддърветата също правим оптимални. Тогава можем да напишем формулата за цената Cleft,right на оптимално binary search tree. Лявото поддърво има цена Cleft,I-1, дясното – Ci+1,rightспрямо корена си.
wi w Left wi-1 w i+1 wRightСтруктура на оптимално за претърсване бинарно дървоТогава търсим минимизация за цената на цялото дърво (т.е. спрямо кое i): i-1 RightCleft,Right = min pi + CLeft,i-1 + Ci+1,Right + pj + pjLeft <= I <= Right j = Left j=i+1 Right = min CLeft,i-1 + Ci+1,Right + pjLeft <= i <= Right j=Left Спрямо това i За да отчетем Че всеки възел В тези поддървета Е 1 ниво по-дълбоко Спрямо общия корен
На основата на тази формула се гради алгоритъмът за цена на оптималното дърво.Търсим i, така че да се минимизира C Left,Right.Таблицата е резулатът от работата на алгоритъма:a..a am..am and..and egg..egg if..if the..the two..two.22 a .18 am .20 and .05 egg 025 if .02 the .08 twoa.am am..and and..egg egg..if if..the the..two.58 a .56 and .30 and .35 if .29 if .12 twoa.. and am..eggand..if egg..the if..two1.02 am .66 and .80 if .39 if .47 ifa..egg am.. if and..the egg..two1.17am 1.21 and .84 if .57 ifa.. if am.. the and..two1.83 and 1.27 and 1.02 ifa.. the am..two1.89 and 1.53 anda.. two2.15 and цена Корен на оптималното (до момента ) бинарно д-во Определянето на цената ( за подредица от am до if) е показано на следващ слайд Цена / корен на оптимално д-во, съдържащо всички думи (третият граф)
за всяка подредица от думи се пази и цена ( в случая вероятност) и корен на оптималното (до момента) binarysearchtree.Най-долу се получава цена и корен за оптималното дърво, съдържащо всички думи (това е и оптималното дърво, показано трето в графите).Как са изчислени стойностите за всички възможни корени до откриване на оптимално дърво за подмножество от думи am..if : am and NULL and..if am..am egg..if 0 + 0.80 + 0.68 = 1.48 0.18 + 0.35 + 0.68 = 1.21 egg if am..and if..if am..egg NULL 0.56 + 0.25 + 0.68 = 1.49 0.66 + 0 + 0.68 = 1.34
Последователно се поставят за корени am, and, egg, if и се изчислява цена и оттам минималната цена.Например, когато and е корен, лявото поддърво am…am има цена 0,18 (вече определена), дясното – egg-if с цена0.35 и pam+pand+pegg+pif = 0.68.Тогава общата цена е 1,21 3Времето е O(N ) защото имаме тройно вложен цикъл
3.3 Най-къс път м/ду всички двойки точки в графИмаме насочен граф G=(V.E). Алгоритъмът на Dijkstra намиращ най-къси пътища от произволен връх до всички останали (O( V ^2 ) работеше на етапи: започваме от връх s; всеки връх (v) се селектира като междинен.За всеки връх w-дестинация, дистанцията d се изчислява така: dw= min (dw,dv+cvw)Сега селектираме върхове последователно. Нека Dk,I,j е теглото на най-късия път от vi до vj през v1,v2…vk (к междинни върха) .Т.е.: D0,i,j = ci,j или безкрайност ако няма ребро.DV ,i,j е най-къс път от vi до vj из целия граф.Когато к>0, можем да напишем оптимизирана програма за най-къс път D k,i,j.Най-късият път е или този който изобщо не минава през v1,v2…vk междинно, или получен от сливане на 2 пътя: vivk; vkvj, всеки минаващ през първите k-1 междинни върхове .
for (int k=0;k<n; k++) // нека всеки връх разгледаме като междинен for (int I=0;I < n; I++) for(int j=0; j < n; j++) if(d[ i ][ k ] +d[ k ][ j ] < d[ i ][ j ]; { // нов най-къс пътd[ i ] [ j ] = d[ i ][ k ] + d[ k ][ j ]; path[ i ][j] = k; }или формулата:Dk,I,j = min{Dk-1,i,j, Dk-1,i,k + Dk-1,k,j}3Времето отново е O( V )Освен това алгоритъмтът е отличен за разпаралеляване.
4. Алгоритми с backtrackingДостига до добри решения , но е непредвидимо бавен, поради връщаниятаПример: подреждане на мебели в къща.спира се на различни етапи и се кара до изчерпване.4.1Проблемът – реконструиране (приложение Физика, мол. Биология..)Нека имам N точки: p1,p2…pN подредени по оста x.Дадени разстоянията N(N – 1) / 2.Нека x1 = 0Ако имахме дадени координатите, лесно можем да изчислим 2разстоянията. O(N )Нека дистанциите с дадени сортирано. Задачата е: да се реконструират координатите на точките от дистанциите.