Download

1 / 22
220 likes | 350 Views
A Hybrid Multicast-Unicast Infrastructure for Efficient Publish-Subscribe in Enterprise Networks. Danny Bickson, Ezra N. Hoch, Nir Naaman and Yoav Tock IBM Haifa Research Lab, Israel. Outline. Motivation The channelization problem Our hybrid approach Experimental results Conclusions.

E N D
A Hybrid Multicast-Unicast Infrastructure for Efficient Publish-Subscribe in Enterprise Networks Danny Bickson, Ezra N. Hoch, Nir Naaman and Yoav Tock IBM Haifa Research Lab, Israel
Outline • Motivation • The channelization problem • Our hybrid approach • Experimental results • Conclusions
Motivation: large scale publish subscribe application Data Vendor WAN Subscribers Publisher Enterprise LAN Multiple information flows (Topics) Large number of information flows (topics) and subscribers Each flow must be delivered to a subset of interested subscribers Example: financial market data dissemination • Publisher divides data feed into a large number information flows, (~100K) e.g. stock symbols, futures, commodities • Many stand-alone subscribers (~1K) • Subscribers display interest heterogeneity - are interested in different yet overlapping subsets of the topics • Any single topic may be delivered to a large number of subscribers (hot / cold topics)
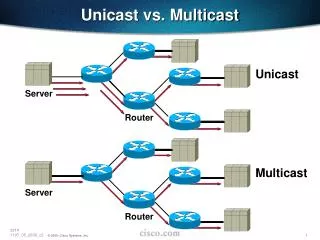
Common approaches Use unicast (point-to-point) connections • Limitations: poor utilization of network resources (duplicate transmissions) Use broadcast (single multicast channel) • Limitations: receivers filter unwanted content Utilize multicast to transmit data • Topics are mapped into multicast groups. Each user joins the groups that cover his topic-interest. • Reduces receiver filtering • Limitations: limited amount of multicast addresses • Network element state problem • Receiver resources (NICs)
Our novel contribution Create a hybrid approach that combines both multicast and unicast • Flexible allocation of transmissions • Topics with high interest enjoy efficiency of multicast • Topics with low interest are transmitted in unicast Formalize as an optimization problem • Propose a two step alternating method for computing the resource allocation
The Channelization Problem n flows Flow rates λ k multicast groups m users Interest matrix W The task: find mapping matrices X,Y that minimizes the communication cost The cost of transmission – take into account transmission to multiple groups The cost of reception – minimize excess filtering
The Hybrid Channelization Problem Flows Multicast Groups G1 X – flow to group map Y – user subscription map G2 Users InterestExtraction (W) Gk F1 U1 F1 F2 F2 U2 F1 F2 F8 F3 U3 F3 F4 F6 F4 Fn Um F1 Fn T – unicast transmission map
The Hybrid Channelization Problem Cost of multicast reception Cost of multicast transmission Cost of unicast reception & transmission Modified cost function Problem objective is
Proposed Solution Unfortunately the hybrid problem is NP-hard We propose a two step heuristic solution • First step: solve the channelization problem (multicast mapping) • Second step: • Choose flow-user pairs for unicast, • Remove redundant assignments from multicast mapping • Recalculate the cost • Iterate until convergence, or unicast BW limit exceeded
First step: channelization problem solution We have experimented with the following algorithms K-Means (2005) performs best
R1 R2 … RK K-Means Mapping Algorithm Interest Matrix = Topics v x x x x • Input • Interest matrix, topic rate vector • Basic insight • Put “similar” topics in the same group • “Similar” topics have a similar audience - causes less filtering • Take the rate into account v v x x x Users v v v x x User’s Interest Vector Topic’sAudience Vector Rate Vector = T1 T2 • Iterative Clustering Algorithm (K-means) • Init: Topics are assigned into a fixed number of groups • Move: In each step, remove a single topic, and move it to the bestgroup – the one producing the lowest cost • Cost: After each epoch, compute total filtering cost • Stop: cost doesn’t improve | time elapsed | max # iter. ? T3 T4 T5 T6 T5 T7 ? T8 T9 ?
Second step: choosing user-flow pairs for unicast Experimented with several heuristics • Heavy users - all transmission to a specific heavy user is sent using unicast • Lightweight flows - flows with low bandwidth are sent using unicast • Greedy flows - move to unicast the flow which best minimizes the total cost • Greedy users - move to unicast the user which best minimizes the total cost • An additional heuristic - Greedy user-flow pairs – move to unicast the user-flow pair which best minimizes the total cost - very slow, impractical run-time
Experimental results Construction of user-interest matrix W • Random, uniform • Market distribution – based on a model of NYSE stock volume • IBM WebSphere cell – a real system
Channelization algorithms K-Means (2005) performs best Takes rate into account Gradient decent on the true cost function
Effect of the interest matrix on channelization performance The interest and rate have a significant effect on channelization performance Some interests have patterns that are easy to “channelize” Interests with less entropy, more order, are easier
Hybrid Algorithm Heuristics Unicast BW limit – algorithm will use optimal amount up to the limit Market dist. - Greedy users Can use more unicast BW WebSphere dist. - Greedy flows Doesn’t need more than 20% unicast BW
Hybrid using greedy flow – unicast / multicast tradeoff • Every interest and rate distribution has an optimal amount of unicast BW it can use • The hybrid approach improves upon both unicast-only and multicat-only Unicast BW allocation – exact amount of unicast BW used
Conclusions ~ The End ~ We have presented a novel hybrid approach for publish subscribe We have shown using extensive and realistic simulation results that our approach reduces consumed network and host resources K-Means (2005) performs best for channelization, from the selection of algorithms we tested Greedy hybrid heuristics performed best in our tests Relative competitiveness of the greedy-flows & greedy-users heuristics depends on the structure of the interest matrix and rate
Real Life Messaging Load Model • Model based on statistical analysis of NYSE daily trade data • 20K Topics • 500 Subscribers • Avg. ~70 flows / user • Min 15 flows / user • Max 115 flows / user • Avg. message fan out ~10.1 clients • Multicast - message is transmitted once • Unicast transmitter data rate is x10 of multicast ! Backup – Model
Messaging Load Model – Based on Market Research • Financial front office • Hundreds of users, requiring stock quotes and financial information from several markets • Topic space structure • Within each market, symbol popularity and rate are exponentially distributed (NYSE market research) • Several different markets, with Avg. popularity and size prop. ~1/m (assumption). • 20K flows, 10 markets, 500 users • User interest • Each user: selects some markets, selects a percent of the symbols from each chosen market, according to the said distributions ~10% of Symbols~55% of trade Backup – Model
Mapping Algorithm Interest Matrix Topics • Input • interest matrix, topic rate vector • Basic insight • Put “similar” topics in the same group • “Similar” topics have a similar audience • A group with a homogenous audience causes less filtering • Take the rate into account • The cost of putting two topics in the same group • The cost of adding a new topic to a group of topics v x x x x x v v x x Users x x v v v Topics with identical audience Topics with similar audience Filtering Cost Topics 1 2 R2 v x 1 Users 0 v v 2 R1 x v 3 0 x x 4 R1+R2 Rk – the rate of topic k Backup – Algorithm
v v v v x v x v v v v v v v v x v v x x x x x v x x x x x x Iterative Clustering Algorithm (K-means) T1 T2 • Init: Topics are assigned into a fixed number of groups • Move: In each step, remove a single topic, and move it to the bestgroup – the one producing the lowest cost • Cost: After each epoch, compute total filtering cost • Stop: time elapsed | cost does not improve | exceeded max number of iterations ? T3 T4 T5 T6 T5 T7 ? T8 T9 ? The best group for topic K is the group with the lowest cost The cost of addingtopic 5 to topic group {1,2,3} Groupaudience vector Candidatetopic 5 Topic group 1 2 3 0 0 0 Users R5 R1+R2+R3 0 R1+R2+R3+R5 Backup – Algorithm