Download
1 / 22
220 likes | 324 Views
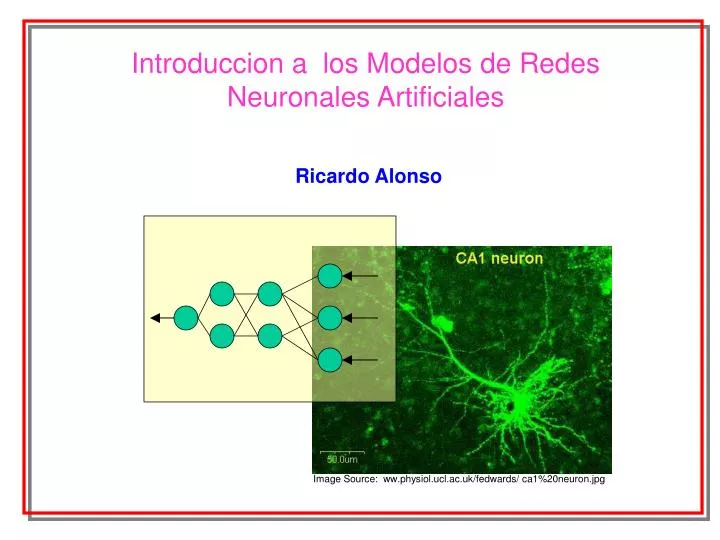
Image Source: ww.physiol.ucl.ac.uk/fedwards/ ca1%20neuron.jpg. Introduccion a los Modelos de Redes Neuronales Artificiales. Ricardo Alonso. Definicion. Redes Neurales Una amplia calse de modelos que reproducen el funcionamiento del tejido Neural del Cerebro.

E N D
Image Source: ww.physiol.ucl.ac.uk/fedwards/ ca1%20neuron.jpg Introduccion a los Modelos de Redes Neuronales Artificiales Ricardo Alonso
Definicion Redes Neurales Una amplia calse de modelos que reproducen el funcionamiento del tejido Neural del Cerebro • Existen varias clases de modelos NN. • Ellos son diferentes entre si, dependiendo de : • Tipo de problemas asociados: Prediccion, Clasificacion , Aglomeracion • Estructura del modelo • Algoritmo de construccion del modelo Para esta charla, nos vamos a enfocar en Redes Neuronales de propagacion hacia adelante (usados en los problemas de clasificacion y prediccion)
Dendritas Cuerpo celular Axón Sinapsis Un poco de Biologia . . . La unidad funcional mas importante del Cerebro – una celula llamada – NEURONA Celula Neuronal Fuente: heart.cbl.utoronto.ca/ ~berj/projects.html Esquema • Dendritas – Reciben información • Cuerpo celular – Procesa información • Axón – Transporta informacion procesada a otras Neuronas • Sinapsis – Union Axón – Dendritas de otras Neuronas
f Una Neurona Artificial Dendritas Cuerpo Celula Axón X1 Dirección flujo informació w1 w2 X2 V = f(I) I . . . I = w1X1 +w2X2 +w3X3 +… + wpXp wp Xp • Recibe entradas X1 X2 …Xp de otras Neuronas o el ambiente. • Entradas se alimentan a traves de conexiones con peso. • Entrada Total = Suma ponderada de las entradas de otras fuentes. • Funcion de transferencia (funcion Activacion) convierte entradas a • en salidas. • La salida va a las entradas de otras Neuronas.
1 1 0.5 0 -1 Funciones de Transferencia Hay varios tipos de opciones para seleccionar la funcion de transferencia o funcion de activación 1 0 Logistic f(x) = ex / (1 + ex) Threshold 0 if x< 0 f(x) = 1 if x >= 1 Tanh f(x) = (ex – e-x) / (ex + e-x)
X1 X2 X3 X4 Dirección de flujo información y1 y2 ANN – Red Neuronal con alimentacion hacia adelante Una coleccion de Neuronas conforma una ‘ Capa’ Capa de Conección - Cada Neurona adquiere SOLO una entrada directamente del medio Capa de Entrada / Intermedia - Conecta la capa de Coneccion con las unidades de procesamiento Capa de Salida - La salida de cada Neurona va directamente hacia afuera de la Neurona.
ANN – Red Neuronal con alimentacion hacia adelante El numero de capas ocultas puede ser Muchas Ninguna Una
X1 X2 X3 X4 y1 y2 ANN – Red Neuronal con alimentacion hacia adelante Un par de cosas que se debe decir • Dentro de la Red, las Neuronas no estan interconectadas una con otra. • Las Neuronas de una capa solamente se conectan con las de la capa superior. (Feed-forward) • No se permite el salto de Neuronas.
Un modelo de ANN en particular Que queremos decir con un model particular de ANN? Entradas: X1 X2 X3 Salidas: Y Modelo: Y = f(X1 X2 X3) Para una ANN : La forma algebraica de f es muy complicada para ser escrita. • Sin embargo, esta caracterizadas por : • # Neuronas de entrada y coneccion • # Capas ocultas o intermedias • # Neuronas en cada cada oculta • # Neuronas de salidas • PESOS de cada coneccion Ajuste de un model ANN = Especificar los valores de estos parametros
X2 X3 X1 -0.2 0.6 -0.1 0.1 0.7 0.5 0.1 -0.2 Y Decidido por la estructura del problema # de variables # de salidas Parametos libres Un modelo en particular – un ejemplo Modelo: Y = f(X1 X2 X3) Entradas: X1 X2 X3 Salidas: Y Parametros Ejemplo # Neuronas entrada 3 # Capas ocultas 1 # Neuronas CO 3 # Neuronas sal. 3 Pesos Especificados
X1 =1 X2=-1 X3 =2 0.2 = 0.5 * 1 –0.1*(-1) –0.2 * 2 f(x) = ex / (1 + ex) f(0.2) = e0.2 / (1 + e0.2) = 0.55 0.2 0.9 Y predicha = 0.478 f (0.9) = 0.71 f (0.2) = 0.55 0.55 0.71 -0.087 f (-0.087) = 0.478 0.478 Prediccion usando un modelo ANN en particular Entradas: X1 X2 X3 Salidas: Y Modelo: Y = f(X1 X2 X3) -0.2 0.6 -0.1 0.1 0.7 0.5 0.1 -0.2 Suponga que en realidad Y = 2 Entronces Error prediccion = (2-0.478) =1.522
# capas ocultas = ??? Use 1 # N. capa oculta = ???Use 2 No hay estrategia fija. Solo ensayo y error Building ANN Model Como se construye el modelo ? Entradas: X1 X2 X3 Salidas: Y Modelo: Y = f(X1 X2 X3) # N. entrada = # entradas = 3 # N. Salida = # Salidas = 1 La arquitectura esta definida … Como se obtienen los pesos??? Hay 8 pesos que estimar. W = (W1, W2, …, W8) Data de adiestramiento: (Yi , X1i, X2i, …, Xpi ) i= 1,2,…,n Dada una eleccion particular de W, obtendremos las Y predichas( V1,V2,…,Vn) Ellas son función de W. Elegimos W tal que el error de prediccion E sea minimo E = (Yi – Vi) 2
Back Propagation Feed forward Entrenamiento del modelo Como adiestrar el modelo ? • Empiece con un conjunto aleatorio de pesos. • Calculo los valores estimados de la salida y obtenga • V1 en funcion del patron X1; Error = (Y1 – V1) • Ajuste los pesos a fin de reducir el error • ( la red ajusta el primer patron de datos ). • Haga lo mismo con el segundo patron de datos • Prosiga hasta el ultimo patron de datos. • Con esto se finaliza un ciclo. • Repita otro ciclo, una y otra vez hasta que el error • Total obtenido para cada patron ( E ) sea minimo E = (Yi – Vi) 2
Retropropagacion Unos detalles adicionales respecto a la retropropagacion Cada peso tiene su parte de culpa con respecto al mayor o menor error de prediccion ( E). El mecanismo de Retropropagacion decide cuales de los pesos tiene mayor culpa al respecto. Poca culpa, representa poco ajuste. Mucha culp, mucho ajuste. E = (Yi – Vi) 2
Ajuste de pesos durante la Retropropagacion Formula de ajuste de W en la Retropropagacion Vi – la prediccion de la I-esima observacion – Es una funcion de W= ( W1, W2,….) Por consiguiente, E, el error total de la prediccion es funcion de W E( W) = [ Yi – Vi( W ) ] 2 Metodo de descenso por gradiente : Para cada peso individual Wi, la formula de ajuste es : Wnew = Wold + * ( E / W) |Wold = parametro de aprendizaje (entre 0 and 1) A veces se utiliza otra variacion leve W(t+1) = W(t) + * ( E / W) |W(t) + * (W(t) - W(t-1) ) = Momentum (entre 0 and 1)
w1 w2 Interpretacion Geometrica del Ajuste de Pesos Considere una Red simple de 2 entradas y 1 salida. No hay capas ocultas. Solo hay dos pesos, los cuales deben ser calculados. E( w1, w2) = [ Yi – Vi(w1, w2 ) ] 2 • El par ( w1, w2 ) es un punto en un plano 2-D. • Para cada par, se asocia un valor de E. • Ploteemos E vs ( w1, w2 ) – una superficie 3-D – • llamada ‘Superficie de Error’ • La meta es identificar que par de valores minimiza E • Eso quiere decir, que punto de W minimiza la altura de • la funcion E • Algoritmo de Descenso en Gradiente • Comience con un punto al azar ( w1, w2 ) • Muevase a un punto mejor ( w’1, w’2 ) como mejor se entiende un punto de • menor valor E. • Muevase hasta lograr un punto el cual no pueda ser mejorado.
Superficie de Error Minimo local Minimo Global w* w0 Espacio de Pesos Reptando por la Superficien de Error
Do hasta que el criterio de convergencia no se cumpla For I = 1 to # Patrones adiestramiento Next I End Do Algoritmo de Entrenamiento Decida la Arquitectura de la Red (# Capas ocultas, #N. en cada capa). Decida los Parametros de momentum y adiestramientoarning parameter and Momentum. Inicializa los pesos con valores aleatorios. Feed forward el i-esima patron y calcule el error Back propagate el error y ajuste los pesos E = (Yi – Vi) 2 Verifique convergencia
Criterio de Convergencia Cuando parar el algoritmo ? Idealmente – cuando se alcance el minimo global ode la Superficie de Errores Como sabemos que hemos llegado a ese minimo ? ………….. No lo sabemos • Sugerencia: • Pare cuando el valor de E no disminuye significativamente. • Pare si los cambios globales en los pesos no son significativos. Problemas: El Error se mantiene decreciento. Obtenemos un buen ajuste en la data. PERO … la red obtenida tiene un ppobre poder de generalizacion ante data nueva. Este fenomeno se denomina - Over fitting de la data de adiestramiento. Se dice que la red Memoriza la data de adiestramiento. - Es por esto que al dar un valor de X conocido, la red reproduce el valor de Y asociado a la data. - La red, en realidad, no ha captado realmente la relacion entre X y Y .
Validacion Error Adiestramiento Ciclo Criterio de Convergencia Sugerencia modificada: Divida la data en dos subconjuntos conjunto de adiestramiento y conjunto de validacion. Use El conjunto de adiestramiento para construir la Red El conjunto de validacion para chequear el comportamiento de la Red Tipicamente, a medida que tenemos mas y mas ciclos de adiestamiento El error del conjunto de adiestramiento disminuye. El error del conjunto de validacion disminuye y luego se incrementa. Pare el adiestramiento cuando el error de validacion se incrementa
Eleccion de los Parametros de Adiestramiento Parametro de adiestramiento y momentum - debe ser suplido por el usuario. Esta en el rango 0 - 1 Cuales son sus valores optimos ? - No hay consenso en uan estrategia fija. - Sin embargo se ha estudiado el efecto de una mala eleccion. Parametro Adiestramiento Demasiado grande – grandes saltos en el espacion de pesos –riesgo de no detectar el minimo local. Muy pequeño – - Toma mucho tiempo en alcanzar el minimo global - Si cae en un minimo local, es imposible salir de el. Sugerencia Ensayo y Error – Ensaye varios valores de ambos parametros y vea cual es el mejor.
Repaso • Artificial Neural network (ANN) – Una clase de modelo basado en simil biologico con el sistema nervioso central. • Usados para varios tipos de modelos – Prediccion, Clasificacion, Aglomeracion, .. • Una clase particular de ANN – Red de propagacion hacia adelante • Organizado en capas. • Cada capa tiene un numero de Neuronas artificiales. • Las Neuronas en cada capa se conecta con las Neuronas de otras capas. • Las conecciones tienen pesos. • El ajuste de una Red consiste en buscar los pesos de estas conecciones. • Dados varios patrones adiestramiento – los pesos son estimados mediante el metodo de Retropropagacion el cual es una forma del metodo de Descenso por Gradiente – la cual es una tecnica popular de minimizacion. • La arquitectura de la Red asi como sus parametros de adiestramiento son seleccionados mediante ensayo y error.