Download

1 / 26
260 likes | 329 Views
指導教授:曾慶耀老師 學生:余政彥 學號: 19967005. 控制與原理專題報告 A PROGRANIMABLE ON-CHIP BP LEARNING NEURAL NETWORK WITH ENHANCED NEURON CHARACTERISTICS. ABSTRACT :.

E N D
指導教授:曾慶耀老師 學生:余政彥 學號:19967005 控制與原理專題報告A PROGRANIMABLE ON-CHIP BP LEARNING NEURALNETWORK WITH ENHANCED NEURONCHARACTERISTICS
ABSTRACT: • A circuit system of programmable on-chip BP(Back-Propagation) learning neural network with enhanced neuron characteristics is designed. The whole system comprises feed-forward network,error back-propagation network and weight updating circuit. • Ithas the merits of simplicity, programmability, speediness, Lowpower consumption and high density. • A novel neuron circuitwith programmable parameters is proposed. It generates not onlythe sigmoidal function but also its derivative.
The non-linear partition and functionfitness hardware simulations are done to the whole system. • Bothexperiments verify the superior performance of this BP neuralnetwork with on-chip learning.
INTRODUCTION: • Hardwareimplementation of BP neural networks can be trained in severalways including off-chip learning, chip-in-the-loop learning andon-chip learning. • off-chip learning: The off-chip learning performs all computation off the chip. Once the solution weight state has been found. The weights are downloaded to the chip.
chip-in-the-loop learning: In the chip-in-the-loopsituation. the errors are calculated with the output of the chip. Butthe weight updates are calculated and performed off the chip. • on-chip learning: In the case of on-chip learning. the weight updates are calculated and applied on the chip.
On-chip learning is imperative when the system needs to meet the following requirements : 1) high speed. 2) autonomous operation in unknown and changing environment. 3) small volume. 4)reduced weight.
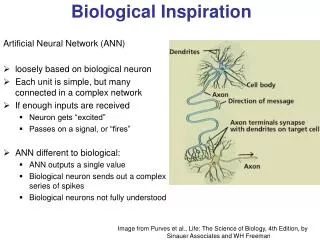
In the on-chip back-propagation learning, both a non-linear function and its derivative are required. A simple neuron circuit realizing both a neuron activation function and its derivative is proposed in this paper.
The transfer function of eachneuron is always sigmoid function expressed by equation 1. where α is the gain factor and s is the sum of the weighted inputs.
The circuit system is designed according to the algorithm above. • It comprises feed-forward network. error back-propagation network and weight updating circuit. • In the feed-forward network. the synapse is realized by the Gilbert multiplier.
The nonlinear I-V transfer function is accomplished by the neuron. Using the forward difference method. the neuron generates the sigmoidal function and its derivative. • The latter is used in the error back-propagation network, which also includes multipliers.
The weight unit (WU) implements the weight update operations,whose diagram is shown in figure . A 7-bit ADC is used to convert the analog weight change signal to digital form. which is added to the 12-bit weight. The new weight is converted to analog signal by a DAC for the next feed-forward calculation and stored in the RAM for the next weight updating.
Assuming that M3. M4 are operating in saturation and follow an ideal square law. the drain current of transistor M3 can be expressed as • with the input differential voltage Vd ( Vd = VB –Vref2 ) in a finite region of
Here β is the transconductance parameter for transistors M3 and M4. • Assuning that Vout = Vout (Iin )is the generated neuron activation function, using the forward difference method, the approximate derivative voltage Vderiv is achieved by subtracting Vout2 from V0ut1 as follows
The dash dot line and the dash line in figure show the simulated neuron activation function and its fitted sigmoid function respectively. • Their relative error is less than 3%. The solid line and the dot line in figure 5 show the derivative found by simulation of the circuitry in figure 4 and the derivative of the simulated neuron activation function respectively. The relative error between them is less than 5%.
The great power of an artificial neural network derives from its ability to be adapted to the unknown and changing environment.Therefore, good programmability is of fundamental importance.Different application may need different gain factor α and threshold vector θ. This call be realized by varying Iref,VN andVp.
CONCLUSIONS: • The threshold and the gain factor of the neuron can be easily programmable according to different requirements. The nonlinear partition and function fitness hardware simulations are done to the whole system. Both experiments verify the superior performance of this BP neural network with on-chip learning.
REFERENCES: • Berg Y. et al. "An analog feed-forward neural network with on-chip learning". Analog Integrated Circuits arid Signal Processing. 9: 65-751. 1996. • Morie T.. Amemiya Y. "An all-analog expandable neural-network LSI with on-chip back-propagation learning". IEEE Journal of Solid State Circuits. 29(9): 1086- 1093.1994. • Cauwenberghs G. "An analog VLSI recurrent neural network learning a continuous-time trajectory". IEEE Trans. Neural Networks. 7(2): 346-361. 1996. • Valle M. et al. "An analog VLSI neural network with on-chip back propagation learning". Analog Integrated Circuits and Signal Processing. 9: 23 1-245. 1996. • Dolenko B. K.. Card H. C. "Tolerance to analog hardwar of on-chip learning in back-propagation networks". IEEE Trans. Neirral Nefivor4s. 6(5): 1045- 1052. 1995. • Lu C.. Shi B. "Circuit design of an adjustable neuron activation function and its derivative". Electronics Letters. 36(6): 553-555. 2000. • Lee S.T. and Lau K.T. "Low power building block for artificial neural networks". Electronics Letters. 3 1 : 161 8-1619. 1995.