Download

1 / 38
380 likes | 440 Views
COMP541 Multicycle MIPS. Montek Singh Apr 4, 2012. Topics. Issue w/ single cycle Multicycle MIPS State elements Now add registers between stages How to control Performance. Multicycle MIPS Processor. Single-cycle microarchitecture: + simple

E N D
COMP541Multicycle MIPS Montek Singh Apr 4, 2012
Topics • Issue w/ single cycle • Multicycle MIPS • State elements • Now add registers between stages • How to control • Performance
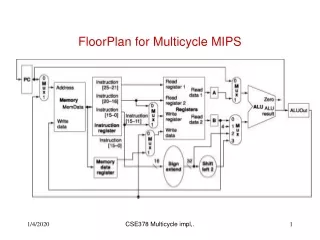
Multicycle MIPS Processor • Single-cycle microarchitecture: + simple • cycle time limited by longest instruction (lw) • two adders/ALUs and two memories • Multicycle microarchitecture: + higher clock speed + simpler instructions run faster + reuse expensive hardware on multiple cycles - sequencing overhead paid many times • Same design steps: datapath & control
Multicycle State Elements • Replace Instruction and Data memories with a single unified memory • More realistic
Multicycle Datapath: lw instr fetch • First consider executing lw • STEP 1: Fetch instruction
Multicycle Datapath: increment PC Now using main ALU when it’s not busy (instead of dedicated adder)
Multicycle Datapath: sw • Compared to lw • addr generated as for lw • write data in rt to memory
Multicycle Datapath: R-type Instrs. • Read from rs and rt • Write ALUResult to register file • Write to rd (instead of rt)
Multicycle Datapath: beq • 2 tasks • Determine whether values in rs and rt are equal • Calculate branch target address: • BTA = (sign-extended immediate << 2) + (PC+4) • ALU reused!
Main Controller FSM: Fetch • Fetch instruction • Also increment PC (because ALU not in use) Note: signals only shown when needed and enables only when asserted.
Main Controller FSM: Decode • No signals needed for decode • Register values also fetched • Perhaps will not be used
Main Controller FSM: Address Calculation • Now change states depending on instr
Main Controller FSM: Address Calculation • For lw or sw, need to compute addr
Main Controller FSM: lw • For lw now need to read from memory • Then write to register
Main Controller FSM: sw • sw just writes to memory • One step shorter
Main Controller FSM: R-Type • The r-type instructions have two steps: compute result in ALU and write to reg
Main Controller FSM: beq • beq needs to use ALU twice, so consumes two cycles • One to compute addr • Another to decide on eq • Can take advantage of decode when ALU not used to compute BTA • (no harm if BTA not used)
Main Controller FSM: addi • Similar to r-type • Add • Write back
Multicycle Performance • Instructions take different number of cycles: • 3 cycles: beq, j • 4 cycles: R-Type, sw, addi • 5 cycles: lw • CPI is weighted average • SPECINT2000 benchmark: • 25% loads • 10% stores • 11% branches • 2% jumps • 52% R-type • Average CPI = (0.11 + 0.2)(3) + (0.52 + 0.10)(4) + (0.25)(5) = 4.12
Multicycle Performance • Multicycle critical path: • Tc = tpcq + tmux + max(tALU + tmux, tmem) + tsetup
Multicycle Performance Example Tc = tpcq_PC + tmux + max(tALU + tmux, tmem) + tsetup = tpcq_PC + tmux + tmem + tsetup = [30 + 25 + 250 + 20] ps = 325 ps
Multicycle Performance Example • For a program with 100 billion instructions executing on a multicycle MIPS processor • CPI = 4.12 • Tc = 325 ps • Execution Time = (# instructions) × CPI × Tc = (100 × 109)(4.12)(325 × 10-12) = 133.9 seconds • This is slower than the single-cycle processor (92.5 seconds). Why? • Not all steps the same length • Sequencing overhead for each step (tpcq + tsetup= 50 ps)
Next Time • Next class: • We’ll look at pipelined MIPS • Improving throughput (and adding complexity!) by trying to use all hardware every cycle • Next lab (Lab 10) • See website • A full mini MIPS processor