Download

1 / 1
10 likes | 173 Views
Identifying Similar People in Professional Social Networks with Discriminative Probabilistic Models. Suleyman Cetintas 1 , Monica Rogati 2 , Luo Si 1 , Yi Fang 1. LinkedIn Corp. 2 Mountain View, CA, 95054, USA. Department of Computer Sciences 1

E N D
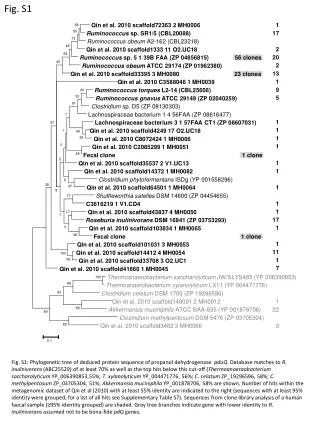
Identifying Similar People in Professional Social Networks with Discriminative Probabilistic Models Suleyman Cetintas1, Monica Rogati2, Luo Si1, Yi Fang1 LinkedIn Corp.2 Mountain View, CA, 95054, USA Department of Computer Sciences1 Purdue University, West Lafayette, IN, 47907, USA • Given the similarity features fv, fv={cv,gv,uv}: the proposed model can be constructed as follows: ▫ where sv in {1,-1} indicates whether the vth pair is similar or not, P(z|cv) and P(t|gv) denote the probability of choosing the latent classes z and t given cv and gv. Nz and Nt are the number of latent content and graph classes that are chosen to be 3 and 2 respectively by AIC. • P(sv|z,t, fv) can be modeled with by logistic function as where λzti is the weight for the ith feature fiv under the latent classes z and t. P(z|cv,α) can be modeled by a soft-max function where Zcv is the normalization factor. P(t|, gv, β) can be modeled similarly. • Parameters of P(sv=1|fv) can be learned by the EM Algo.: ▫ E-step: Compute P(z, t|fv) ▫ M-step: The following M-step update rules are derived. The update rule for β can be achieved similarly with the update rule for α . • Professional Social Networks (PSNs): ▫ Business oriented social networks with core services such as recruiting, job seeking, expert/profile search, item recommendation, ad-targeting, etc. ▫ Information about users can be obtained from heterogeneous sources such as i) profile content, ii) social graph, and iii) user activities on the website. • Challenge: Identify similar professionals in PSNs ▫ All of the above core services rely on successful identification of similar people ▫ No prior work. Related work on identifying similar users in social networks or matching people i) use information from a single source (user profile), or ii) did not differentiate the information from different sources in a principled way • Key Fact: Different sources provide different insights on user similarity ▫ Propose a novel discriminative probabilistic model that i) identifies latent content and social graph classes for people with similar profile content and social graph similarity patterns ii) learns a specialized similarity model for each latent class • Proposed model (referred as Latent_CG_Mod) is compared to: ▫ i) a model that only models latent content classes (referred as Latent_C_Mod) ▫ ii) a model that only models latent social graph classes (referred as Latent_G_Mod) ▫ iii) a model that does not consider any latent classes –corresponding to Logistic Regression (referred as LogReg_Mod) • Evaluation Metric (F1) ▫ The models are evaluated by the common F1 measure as precision and recall are both important. ▫ The “*” symbol indicates statistical significance level with p-value < 0.1 (paired t-tests). • Results ▫ Both Latent_G_Mod and Latent_C_Mod achieve improvements over LogReg_Mod, and are comparable to each other. This shows that by having higher flexibility via introducing a latent class and allowing the combination weights vary accordingly, improvements can be achieved. ▫ Latent_CG_Mod achieves the best performance by modeling the latent content and graph classes that provide more flexibility than Latent_C_Mod and Latent_G_Mod, and much more flexibility than the LogReg_Mod. ▫ It is shown that differentiating pairs with different profile content and social graph similarity patterns, and specializing the similarity model for different pairs of people that share similar similarity patterns is important for achieving higher similarity accuracy. Introduction and Motivation Discriminative Probabilistic Model Experiments and Results • Experiments conducted on a proprietary dataset from LinkedIn, that is constructed via the following steps: ▫ A set of 2200 “key profiles” are selected from the intersection of a) profiles popular among recruiters & b) profiles popular within general users (sets identified by mining the large scale recruiter/user activity logs of 6 months). ▫ Using Lucene, public profiles in the PSN are indexed, and each key profile is used as a structured query to retrieve top 100 “candidate profiles”. From those 100, 10 candidate profiles are selected under 3 strategies: i) top 10, ii) bottom 10, iii) sampled 10 (ranks 1-10, 91-100, and randomly). ▫ A total of 22000 profile pairs are identified for annotation. Each profile pair is annotated by 3 annotators from CrowdFlower from 1 to 4 (most similar). Final rating for each pair is calculated by the average raring weighted by annotator trust. ▫ Pairs with similarity rating > 2.5 are regarded as similar people (4633 pairs). Pairs with rating < 2 (2419 pairs) combined with another set of 2373 (less similar) pairs randomly selected from public member profiles, as the negative set. Out of the total 9425 pairs, two-thirds is used for training, one-third is used for testing. ▫ For each profile pair v, 5 content similarity features cv(comparing users' titles, industries, skills, specialties, associations), 3 social graph features gv(utilizing users' common connections, common groups, and whether their profiles are co-viewed or not), and 5 website usage features uv(utilizing the similarity in profile, search, inbox, news/sharing, accounts/settings page usage patterns) are extracted, and used as the set of features fv={cv,gv,uv}. Dataset • Identifying similar people is an important task for professional social networks. • Different people pairs have different profile content and social graph similarity patterns, and it is important to learn specialized similarity models for people with different similarity patterns. • Novel discriminative probabilistic model that identifies latent content and social graph classes for people with similar content and social graph similarity patterns, and learns a specialized similarity model for each latent class. • Experiments on real world data from LinkedIn show the effectiveness of the proposed discriminative model. Conclusion Acknowledgements: This research was partially supported by the following grants IIS-0746830, CNS-1012208, IIS-1017837. Any opinions, findings, conclusions expressed in this paper are the authors', and do not necessarily reflect those of the sponsors.