Download

1 / 1
10 likes | 73 Views
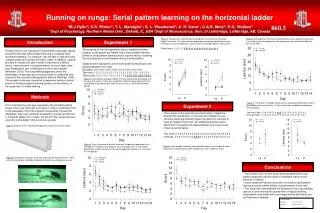
A). T 0 = 19 ms. uniform ISI “linear mode”. T L = 4 T 0. B). LDNL. 2. CEOAEs in Normal Ears

E N D
A) T0 = 19 ms uniform ISI “linear mode” TL = 4 T0 B) LDNL 2. CEOAEs in Normal Ears As in the cavity, the recordings in ears (Fig. 3) show a considerably greater stimulus artefact in LDNL, than in the RDNL or DE paradigms. The average size of the artefact and the SNR in each paradigm is compared in Fig. 4. A TD = 3 T0 B C) Fig 3: Artefacts in Normal Ears (80 dB clicks) A. Detail of example waveform. B. Full example waveform C. rms in a 1-ms sliding window, average of 19 ears. C DE TR 38 T0 Stim Artefact The artefact was characterised by the rms from 0-1 ms, relative to the rms from 2-17 ms. Both DE and RDNL performed better on artefact rejection than LDNL, by 18 dB and 15 dB resp (with 80 dB clicks). DE performed poorly on SNR. Earphone 1 Earphone 2 D) A RDNL 32 standard rate clicks (uniform ISI) Fig 4: Performance of the three nonlinear paradigmsPerformance calculated for 70-dB and 80-dB click levels. Mean and standard error over 19 ears are shown. A. Signal-to-Artefact Ratio (i.e., rms 2-17 ms / rms 0-1 ms) B. Signal-to-Noise Ratio (2-17 ms, estimated from two replicates) MLS (256 clicks) B Reducing stimulus artefacts in click-evoked otoacoustic emissionsusing maximum length sequences Ben Lineton1, Steven Haywood1 and A. Roger D. Thornton2 1ISVR, University of Southampton, UK2MRC Institute of Hearing Research, Royal South Hants Hospital, Southampton, UK Aims and Objectives Three different stimulus paradigms were assessed on their ability to remove the stimulus artefact from click-evoked otoacoustic emissions (CEOAEs), and on the signal-to-noise ratio (SNR) that they achieved. The three paradigms were: 1. Level derived non-linear (LDNL): this is the current clinical standard, and uses two different click levels. 2. Double evoked (DE): proposed by Keefe [1], this paradigm uses two separate earphones to create acoustic clicks at two different levels. 3. Rate derived non-linear (RDNL): this uses non-linear “rate-suppression” arising from maximum length sequence (MLS) stimulation.[2,3] 1. Results in Test Cavity The cavity recording (Fig. 2A) show a considerably greater stimulus artefact in LDNL, than in the RDNL or DE paradigms. This can be seen more clearly by calculating the rms in a 1-ms sliding window (Fig 2B). Fig 2: Artefacts in Cavity A. Early part of the waveform. B. rms in a 1-ms sliding window. Background: Stimulus Artefacts in CEOAEs Recordings of CEOAEs can be contaminated by the click artefact at latencies typically < 3 ms. Current clinical recordings reduce the artefact using a derived level non-linear (LDNL) paradigm[4], which uses two different click levels to separate non-linear from linear responses. Whilst this paradigm works well for CEOAE recordings below 5 kHz, it leaves a residual artefact at short latencies, making it unsuitable for measuring high-frequency CEOAE components with latencies of around 1 ms [1]. These could potentially be useful in the early detection of noise-induced hearing loss, or in monitoring ototoxic drugs[5]. Keefe[4] suggests that the main cause of the residual artefact is non-linearity in the earphone, and proposes the “double-evoked” (DE) paradigm to overcome this problem, which has been used to record high-frequency CEOAEs[5]. A third paradigm, the “rate derived non-linear paradigm” (RDNL) [2,3], has received little attention, and its potential advantages in artefact rejection have not hitherto been investigated. Methods Stimulus Paradigms Four paradigms were used: the “linear paradigm” and the three non-linear paradigms which make use of two or more different conditions, from which a linear response can be distinguished from any non-linear response (Fig. 1). The microphone signal is then processed to extract only the non-linear components. Fig 1: Stimulus Paradigms The electrical signal for a single stimulus epoch: A – “Linear mode” B – Level derived no-linear, C – Double-evoked D – Rate derived non-linear CEOAE recordings CEOAEs were measured using “linear mode” and the three non-linear stimulus paradigms in Fig 1 (B-D). An ILO DPOAE probe driven by an in-house adaptor box was used. CEOAEs were measured in a test-cavity (IEC 711 Ear simulator), and in 19 otologically normal ears. Two click stimulus levels (70 & 80 dB peSPL) were used. The same recording time (3 mins) was used for each of the three non-linear paradigms (Fig 1, B-D). The RDNL paradigm used an order 9 MLS which comprises 256 clicks, and 255 silences. The MLS click opportunity rate (= 1/minimim interclick interval) was 4900 clicks/sec. The MLS was designed to minimise higher-order kernel contamination of the 0-20 ms region.[6] • Conclusions • Artefact Rejection: Both the rate-derived nonlinear (RDNL) and the double-evoked (DE) paradigms performed much better than the standard level-derived nonlinear (LDNL) paradigm on artefact rejection, with improvements of 15 dB and 18 dB respectively, for an 80-dB click stimulus. • Signal-to-noise: The RDNL paradigm performed as well as the LDNL paradigm on SNR, whilst the DE paradigm implemented here performed worse than these, by 6 dB for an 80 dB click stimulus (though other implementations of the DE paradigm are expected to improve on this[5].) • Applications: The RDNL paradigm offers the possibility of recording CEOAEs with reduced stimulus artefacts, with possible applications to recording high-frequency CEOAE components. References [1] Keefe DH (1998), Double-evoked otoacoustic emissions. I. Measurement theory and nonlinear coherence, J Acoust Soc Am, 103, 3489-98. [2] Rasmussen AN, Osterhammel PA, Johannssen PT, Borgkvist B (1998), Neonatal hearing screening using otoacoustic emissions elicited by maximum length sequences, Br J Audiol, 32, 355-66. [3] Hine JE, Thornton ARD (2005) Transient evoked otoacoustic emissions recorded using maximum length sequences from patients with sensorineural hearing loss. Hear Res, 203, 122-33. [4] Kemp DT, Ryan S, Bray P (1990) A guide to the effective use of otoacoustic emissions. Ear Hear, 11, 93-105. [5] Goodman SS, Fitzpatrick DF, Ellison JC, Jesteadt W, Keefe DH. (2009) High-frequency click-evoked otoacoustic emissions and behavioral thresholds in humans. J Acoust Soc Am, 125, 1014-32. [6] Thornton ARD (1997) Maximum length sequences and Volterra series in the analysis of transient evoked otoacoustic emissions. Br J Audiol, 31, 493-8.