Download
1 / 1
10 likes | 105 Views
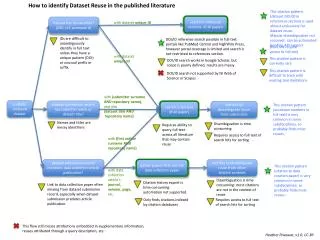
How to identify Dataset Reuse in the published literature. This citation pattern (dataset DOI/ID in references section) is used almost exclusively for dataset reuse. Manual disambiguation not required: can be automated pending API support. search in reference sections of all papers.

E N D
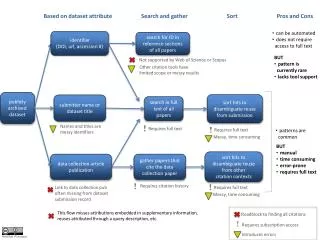
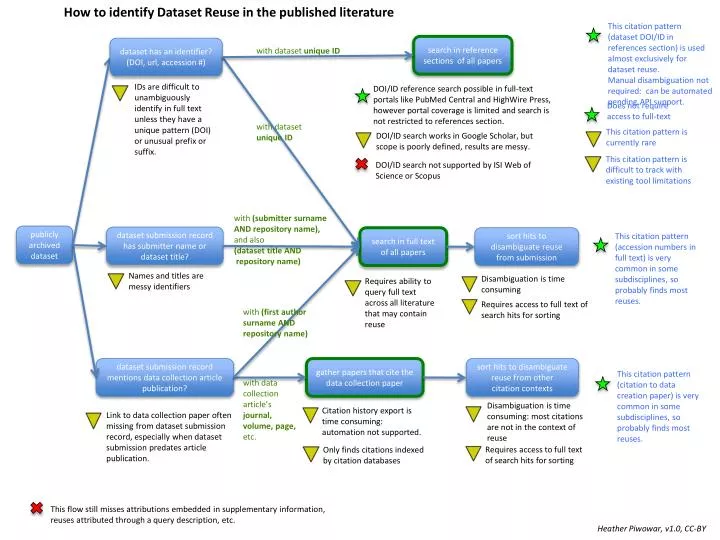
How to identify Dataset Reuse in the published literature This citation pattern (dataset DOI/ID in references section) is used almost exclusively for dataset reuse. Manual disambiguation not required: can be automated pending API support. search in reference sections of all papers dataset has an identifier? (DOI, url, accession #) with dataset unique ID IDs are difficult to unambiguously identify in full text unless they have a unique pattern (DOI) or unusual prefix or suffix. DOI/ID reference search possible in full-text portals like PubMed Central and HighWire Press, however portal coverage is limited and search is not restricted to references section. Does not require access to full-text with dataset unique ID This citation pattern is currently rare DOI/ID search works in Google Scholar, but scope is poorly defined, results are messy. This citation pattern is difficult to track with existing tool limitations DOI/ID search not supported by ISI Web of Science or Scopus with (submitter surname AND repository name), and also (dataset title AND repository name) publicly archived dataset dataset submission record has submitter name or dataset title? This citation pattern (accession numbers in full text) is very common in some subdisciplines, so probably finds most reuses. search in full text of all papers sort hits to disambiguate reuse from submission Names and titles are messy identifiers Disambiguation is time consuming Requires ability to query full text across all literature that may contain reuse Requires access to full text of search hits for sorting with (first author surname AND repository name) gather papers that cite the data collection paper sort hits to disambiguate reuse from other citation contexts dataset submission record mentions data collection article publication? This citation pattern (citation to data creation paper) is very common in some subdisciplines, so probably finds most reuses. with data collection article’s journal, volume, page, etc. Disambiguation is time consuming: most citations are not in the context of reuse Citation history export is time consuming: automation not supported. Link to data collection paper often missing from dataset submission record, especially when dataset submission predates article publication. Requires access to full text of search hits for sorting Only finds citations indexed by citation databases This flow still misses attributions embedded in supplementary information, reuses attributed through a query description, etc. Heather Piwowar, v1.0, CC-BY