Download

1 / 17
170 likes | 177 Views
This article discusses the Euler tour technique for fast and optimal processing of tree data in computer engineering. It covers the Euler circuit of a directed graph, the representation of a rooted tree by its Euler circuit, and computing the depth of nodes in a binary tree. The article also explores parallel algorithms and the concept of broadcasting on a PRAM.

E N D
PRAM ALGORITHMS-3 Computer Engg, IIT(BHU)
Euler Tours Technique for fast optimal processing of tree data Euler circuit of directed graph: directed cycle that traverses each edge exactly once Represent (rooted) tree by Euler circuit of its directed version
Trees (Balance Parentheses) Key property: The parenthesis subsequence corresponding to a subtree is balanced. ((()( ) )( ) (( ) ( ) ( ) ))
Computing the Depth Problem definition Given a binary tree with n nodes, compute the depth of each node Serial algorithm takes O(n) time A simple parallel algorithm Starting from root, compute the depths level by level Still O(n) because the height of the tree could be as high as n Euler tour algorithm Uses parallel prefix computation
Computing the Depth Euler tour: A cycle that traverses each edge exactly once in a graph It is a directed version of a tree Regard an undirected edge into two directed edges Any directed version of a tree has an Euler tour by traversing the tree in a DFS way forming a linked list. Employ 3*n processors Each node i has fields i.parent, i.left, i.right Each node i has three processors, i.A, i.B, and i.C.
Computing the Depth Three processors in each node of the tree are linked as follows i.A = i.left.A if i.left != nil i.B if i.left = nil i.B = i.right.A if i.right != nil i.C if i.right = nil i.C = i.parent.B if i is the left child i.parent.C if i is the right child nil if i.parent = nil
Computing the Depth Algorithm Construct the Euler tour for the tree – O(1) time Assign 1 to all A processors, 0 to B processors, -1 to C processors Perform a parallel prefix computation The depth of each node resides in its C processor O(log n) Actually log 3n EREW because no concurrent read or write Speedup S = n/log n
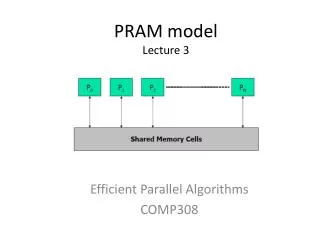
Broadcasting on a PRAM “Broadcast” can be done on CREW PRAM in O(1) steps: Broadcaster sends value to shared memory Processors read from shared memory Requires lg(P) steps on EREW PRAM. M B P P P P P P P P
Concurrent Write - Finding Max Finding max problem Given an array of n elements, find the maximum(s) sequential algorithm is O(n) Data structure for parallel algorithm Array A[1..n] Array m[1..n]. m[i] is true if A[i] is the maximum Use n2 processors
Concurrent Write - Finding Max Fast_max(A, n) for i = 1 to n do, in parallel m[i] = true // A[i] is potentially maximum for i = 1 to n, j = 1 to n do, in parallel if A[i] < A[j] then m[i] = false for i = 1 to n do, in parallel if m[i] = true then max = A[i] return max Time complexity: O(1)
Concurrent Write - Finding Max Concurrent-write In step 4 and 5, processors with A[i] < A[j] write the same value ‘false’ into the same location m[i] This actually implements m[i] = (A[i] A[1]) … (A[i] A[n]) Is this work efficient? No, n2 processors in O(1) O(n2) work vs. sequential algorithm is O(n)
Concurrent Write - Finding Max What is the time complexity for the Exclusive-write? Initially elements “think” that they might be the maximum First iteration: For n/2 pairs, compare. n/2 elements might be the maximum. Second iteration: n/4 elements might be the maximum. log n th iteration: one element is the maximum. So Fast_max with Exclusive-write takes O(log n). O(1) (CRCW) vs. O(log n) (EREW)
Simulating CRCW with EREW CRCW algorithms are faster than EREW algorithms How much fast? Theorem A p-processor CRCW algorithm can be no more than O(log p) times faster than the best p-processor EREW algorithm
Simulating CRCW with EREW Proof by simulating CRCW steps with EREW steps Assumption: A parallel sorting takes O(log n) time with n processors When CRCW processor pi write a datum xi into a location li, EREW pi writes the pair (li, xi) into a separate location A[i] Note EREW write is exclusive, while CRCW may be concurrent Sort A by li O(log p) time by assumption Compare adjacent elements in A For each group of the same elements, only one processor, say first, write xi into the global memory li. Note this is also exclusive. Total time complexity: O(log p)
CRCW vs. EREW CRCW Hardware implementations are expensive Used infrequently Easier to program, runs faster, more powerful. Implemented hardware is slower than that of EREW In reality one cannot find maximum in O(1) time EREW Programming model is too restrictive Cannot implement powerful algorithms