Download

1 / 47
480 likes | 684 Views
Input Queue Switch Technologies. Speaker : Kuo-Cheng Lu N300/CCL/ITRI. Outline. Overview of switching fabric technologies Input queue scheduling algorithms Scheduling for quality of service Multicast scheduling Tiny Tera project PRIZMA project Conclusion. Evolution of Router/Switch.

E N D
Input Queue Switch Technologies Speaker : Kuo-Cheng Lu N300/CCL/ITRI
Outline • Overview of switching fabric technologies • Input queue scheduling algorithms • Scheduling for quality of service • Multicast scheduling • Tiny Tera project • PRIZMA project • Conclusion
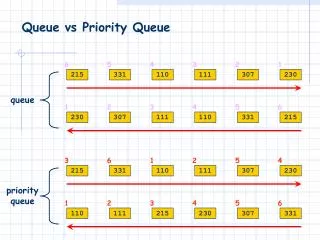
Why input queue switch is less efficient ? • Head of Line Blocking (limited throughput) • Input contention (difficult to control cell delay)
Solve the HOL blocking by VOQ • Virtual Output Queuing to archive 100% throughput with suitable scheduling algorithm
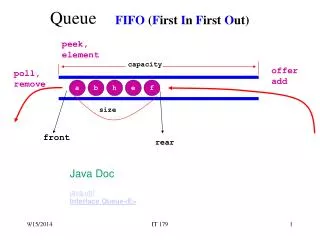
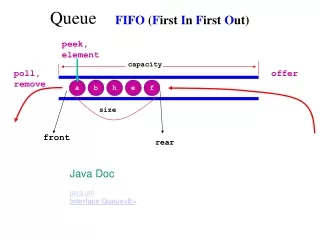
Control cell delay by speedup • Moderate speedup with suitable scheduling algorithm to control cell delay • Need output buffer • CIOQ (combine input output queue) switch
Remark • VOQ can avoid HOL blocking and provide 100% throughput but need a complex scheduling algorithm • m-time speedup (m<N) can reduce HOL blocking and input/output contention by using a suitable scheduling algorithm to approach the performance of output queuing switch • n-time speedup (n=2) with VOQ can emulate output queuing (Nick McKeown)
Input Queue Scheduling Algorithms • First Goal : 100% throughput under admissible input traffic • Second Goal : Control cell transfer delay • Methods : find a matching for • maximum matching • maximal matching • maximum/maximal weight • stable matchingusing VOQ and/or moderate speedup! • *Admissible : Sum(Lamda(I,J)) <1 for all input I, and Sum(Lamda(I,J)) <1 for all output J • *Stable : Q(I,J) < infinit =>(define) 100% throughput
Maximum or Maximal matching • Maximum matching • Maximizes instantaneous throughput • Starvation • Time complexity is very high • Maximal matching • Can’t add any connection on the current match without alert existing connections • More practical (e.g. WFA, PIM, iSLIP, DRR,RRM)
1 1 1 1 2 2 2 2 #1 1 1 3 3 3 3 2 2 4 4 4 4 Grant Accept/Match 3 3 1 1 1 1 1 1 4 4 2 2 2 2 2 2 #2 3 3 3 3 3 3 4 4 4 4 4 4 Parallel Iterative Matching Random Selection Random Selection Requests
iSLIP Properties • De-synchronization is the key to archive high throughput • Random under low load • TDM under high load • Lowest priority to MRU • 1 iteration: fair to outputs • Converges in at most N iterations. On average <= log2N • Implementation: N priority encoders • Up to 100% throughput for uniform traffic in one iteration(c.f. PIM can only archive 63% throughput in one iteration)
iSLIP Implementation Programmable Priority Encoder 1 State 1 log2N Decision N Grant Accept 2 2 N Grant Accept log2N N N Grant Accept log2N N
Wrap Wave Front Arbiter N steps instead of 2N-1 Match Requests
Wave Front Arbiter Requests Match 1 1 1 1 2 2 2 2 3 3 3 3 4 4 4 4
WFA-Implementation 2x2 WFA
Maximum/Maximal Weight Matching • 100% throughput for admissible traffic (uniform or non-uniform) • Maximum Weight Matching • OCF (Oldest Cell First): w=cell waiting time • LQF (Longest Queue First):w=input queue occupancy • LPF (Longest Port First):w=QL of the source port + Sum of QL form the source port to the destination port • Maximal Weight Matching (practical algorithms) • iOCF • iLQF • iLPF (comparators in the critical path of iLQF are removed )
iLPF - Implementation *10ns arbitration time for a 32x32 switch using 0.25 CMOS process (Nick McKeown, IEEE Infocom 1998)
Scheduling for QoS • WPIM (Weighted PIM) • Prioritized iSLIP • FARR (Fair Access Round Robin) • a kind of maximal weight matching • US Patent#5517495 • Output Queue Emulation(Nick McKeown, IEEE JSAC 1999) • Speedup of 2 - 1/N is necessary and sufficient for OQ emulation • using CCF algorithm(Critical Cell First) • Rate Controller Approach(Anna Charny, IWQOS’98) • putting rate controllers at the input and output channels and using OCF arbitration policy can provide deterministic delay guarantee for speedup >2 (delay is function of leaky bucket parameters of a flow, the speedup, and N) • incorporating the rate-controllers into the arbiter with speedup >= 6 can approach OQ delay performance
WPIM • Each Iteration consists of four stages : • Request : every unmatched port sends a request to the destination of each active VOQ • Mask : output create a mask (for per input)to indicate if the input has transmitted as many cell as their credit to the output in the current frame • Grant : from the requests that remain from the masking stage, the output port selects one randomly and sends a grant signal to its originating input port • Accept : every unmatched input port that receives one or more grants selects one with equal probability and notifies the corresponding output port • Modification : • allowing each output port to clear all its mask bits when all of its incoming requests are masked and the output port remains unmatched
Prioritized iSLIP • Request : • input I select the highest priority nonempty queue for output J, Lij • Grant : • output J find the highest level request L(j)=max(Lij), the output maintain a separate pointer for each level,for same level input, the arbiter use the pointer GjL(j) and normal iSLIP scheme to choose the input • Accept : • same as Grant
FARR • Each input selects HOL cell of the highest priority queue for each VOQ and sends the requests with the extended timestamps( a timestamp prepended with its priority) • Repeat the following steps for R times • (1)for each unmatched output, if it has any request from unmatched inputs, grants the request with smallest extended timestamp • (2)for each unmatched input, if it receives any grants, grants smallest extended timestamp • (3)any accepted grants are added into the match
Output Queue Emulation(1/2) TL(C)=3 OC(C)=2 IT(C)=1 L(C)=1 • Definitions • TL(C) : Time to Leave of cell C • OC(C) : Output Cushion of cell C • IT(C) : Input Thread of cell C • L(C) : Slackness of cell C. = OC(C)-IT(C) Sorting according to TL(C) PIAO(Push In Arbitrary Out) Queue
Output Queue Emulation (2/2) • Using PIAO as an input queue, CCF(Critical Cell First) as an input queue insertion policy and stable matching can mimic output queuing with speedup=2 • put the arriving cell at position OC(C)+1 of input PIAQ queue • Slackness always >= 0 • when a cell reaches its time to leave(I.e.OC(C)=0), this means • (1)the cell is already at its output and may depart on time or • (2)the cell is simultaneously at the head of its input priority list(because its input thread is zero) and at the head of its output priority list(because it has reached its time to leave
Remarks • iSLIP can get 100% throughput under uniform Bernoulli traffic (Nick McKeown IEEE Transactions on Networking, April 1999) • Any maximum weight matching(e.g. OCF,LQF) algorithm delivers 100% throughput under admissible traffic(Balaji Prabhakar, IEEE Infocom 2000) • Any maximal matching(e.g. PIM, iSLIP) with 2-time speedup delivers 100% throughput under admissible traffic • Speedup of 2 is sufficient for OQ emulation (Nick McKeown, IEEE JSAC 1999) • For bounded cell delay guarantee, exact OQ emulation may be too costly! Probabilistic or soft-emulation is more practical (Mounir Hamdi, IEEE Comm. Mag. 2000)
Multicast method #1 Copy network + unicast switching Copy networks Increased hardware, increased input contention
Multicast method #2 Use copying properties of crossbar fabric No fanout-splitting: Easy, but low throughput Fanout-splitting: higher throughput, but not as simple. Leaves “residue”.
The effect of fanout-splitting Performance of an 8x8 switch with and without fanout-splitting under uniform IID traffic
Placement of residue Key question: How should outputs grant requests? (and hence decide placement of residue)
Residue and throughput Result: Concentrating residue brings more new work forward. Hence leads to higher throughput. But, there are fairness problems to deal with. This and other problems can be looked at in a unified way by mapping the multicasting problem onto a variation of Tetris.
IBM’s PRIZMA Project • 16 input ports • 16 output ports • 1.6 - 1.8 Gbps per port • QoS: up to four priorities • Built-in support for modular growth in number of ports • Built-in support for modular growth in port speed • Built-in support for modular growth in aggregate throughput • Built-in support for automatic load-sharing • Self-routing switch element • Dynamically shared-output buffered element • Built-in multicast and broadcast • Aggregate data rate 28 Gbit/s per module • 3.8 Million transistors on chip • 624 I/O pins
Architecture Descriptions • A kind of CIOQ (VOQ+Output Queuing) • Schedulers are distributed with complexity of O(N) • The arbiters at the input side perform input contention resolution • The output-buffered switch element performs classical output contention resolution • By means of the flow-control/VOQ interaction b.t. switch element and input queues, the less expensive input-queue memory is used to cope with burst-ness
Core of PRIZMA • Conventional shared memory v.s PRIZMA
Performance of PRIZMA • 16x16 switch element (N=16) • Shared memory size M= 256 cells • *Delay-throughput performance improves notably as the degree of memory sharing is reduced • when VOQ is used, there is no HOL blocking, and the performance is determined only by the o/p queue space available for every output to resolve contention!