Download
1 / 1
10 likes | 95 Views
(0,0,1). (0,a,1). (a,0,1). (1,0,1). (0,0,a). (0,1,1). (1,a,1). (a,1,1). ( 0 ,0,0). (0,1,a). (1,0,a). (a,0,0). ( 1 , 1 , 1 ). ( 0 , a , 0 ). ( 1 , 1 , a ). (0,1,0). (a,1,0). (1,a,0). (1,1,0).

E N D
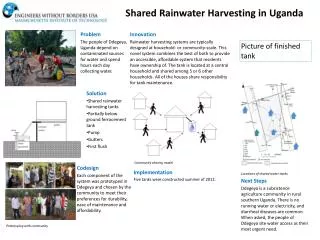
(0,0,1) (0,a,1) (a,0,1) (1,0,1) (0,0,a) (0,1,1) (1,a,1) (a,1,1) (0,0,0) (0,1,a) (1,0,a) (a,0,0) (1,1,1) (0,a,0) (1,1,a) (0,1,0) (a,1,0) (1,a,0) (1,1,0) Coloring black boxes: visualization of neural network decisionsWłodzisław DuchSchool of Computer Engineering, Nanyang Technological University, Singapore, Department of Informatics, Nicholaus Copernicus University, Torun, Poland. Problem Common belief: neural networks (NN) are black boxes, performing incomprehensible functions, they should not be used for safety-critical applications. Understanding of network decisions is possible using logical rules (Duch et al 2001}, but logical rules equivalent to NN functions severely distort original decision borders. Feature space is partitioned by rules into hypercuboids (for crisp logical rules) or ellipsoids (for typical triangular or Gaussian fuzzy membership functions). Typical NN software outputs: mean square error (MSE), classification error, sometimes estimation of the classification probability, sometimes ROC curves. But: perhaps errors are confined to a distant and localized region of the feature space? How to estimate confidence in predictions, distinguish easy/difficult cases? Well trained MLPs provide estimations of p(C|X) close to 0 and 1: they are overconfident in their predictions. 10 errors with p(C|X)1 are more dengerous than 20 with p(C|X)0.5. How to compare networks that have identical accuracy, but quite different weights and biases? Is the network hiding a quirky behavior that may lead to completely wrong results for new data? Is regularization improving the quality of NN? If I only could see it ... but how? Feature spaces are highly dimensional. Answer: look at mapping of the training data samples, their similarities! K classes => scatterogram in K-dimensional space. Dynamics of learning Left: with 3 neurons the network will always under-fit the data, unable to separate small classes. Right: even if 6 hidden neurons are used problems with convergence may arise in some runs. Recommendation: stop further learning, start from another initialization. Perfect solutions may be dangerous, to check for overfitting and see classification margins add some noise. RBF always provides soft decision borders and is more robust under perturbations (Wine data below). 5-class Satimage data. Left: images cluster around pentagon vertices; middle: adding noise with 0.01 variance shows which clusters have almost overlapping regions; right: this is even more evident using 5 Gaussian clusters. Two solutions after 100 iterations, SCG training, 8 hidden nodes, 164 and 197 errors. Projection of network outputs Map each N-dim training vector X to output vector o={oi(X)[0,1]}, i=1..K Similarity between X similarity between o(X), in respect to class membership and distance. Output classes may form continuum => smooth transition from o1(X)=1, o2(X)=0 to o1(X)=0, o2(X)=1 outputs. Sometimes softmax transformation is used to obtain probabilities oi(X)=p(Ci|X), but then information is lost, since p(Ci|X) sum to 1, eliminating answers “don’t know” or o1(X)=0, o2(X)=0, and “member of both classes”, or o1(X)=1, o2(X)=1. For K>3 use parallel coordinates, non-linear MDS or linear projections. Map outputs oi(X) to K corners of regular polygon in 2D. (0,0) vertex corresponds to (1,0,..,0) output, (0,1) vertex to (0,1,..,0), etc. Two very good converged solutions after 19 K and 22 K iterations, SCG training, 8 hidden nodes, 1 error, same MSE. Left: vectors similar to the green are half-way between green and blue; right – high chance of confusing some vectors from blue and red classes. Networks are over-confident and not stable, mapping to a single point. These networks are over-confident, weights are very large, sigmoids are step-like, decision borders are very sharp. Sometimes re-labeling the classes simplifies the picture. Higher number of classes: use parallel coordinates, MDS, several 2D scatterograms or linear projections. • Conclusions • Images of the training data vectors mapped by NN: • show the dynamics of learning, problems with convergence; • show overfitting and underfitting effects; • enable to compare different network solution with the same MSE/accuracy, compare training algorithms, inspect classification margins perturbing the input vectors; • display regions of the input space where potential problems may arise; • display effects of regularization, model selection, early stopping; • show stability of network classification under perturbation of original vectors; • enable quick identification of errors and outliers; • estimate confidence in classification of a given vector by placing it in relation to known data vectors. Vectors near the (1,1,1) corner have larger markers. Since outputs are in [0,1], projections lie within hexagon, corners correspond to binary (o1,o2,o3) values. Corners opposite to oi has inverted bits 1-oi. Points corresponding to vectors that weakly excite single output approach (0,0,0) point along the (a,0,0), (0,a,0) or (0,0,a) lines, while points in the overlapping region of class two and three approach the center along (a,1,1), (1,a,1) and (1,1,a) lines. Effect: poor generalization of the network, evident when training vectors are perturbed by adding noise. Adding regularization term to the error function makes sigmoids smoother. Left: solution with 12 hidden neurons and a=0.01 regularization coefficient, 2 errors; right – small variance (0.001) noise perturbation, 5 additional vector per one training vector added. The best network solutions show large clusters of points around vertices of the polygon, without overlaps with clusters and with no vectors close to the center of the projection. Scatterograms contain more information than ROC curves displaying detection rates for a given false alarm rate: images close to the polygon vertices correspond to the high probability assigned by the classifier, types of errors are evident, and potential errors may be noticed even before they occur. Goal of training: not zero error or zero MSE, but stable, separated images! References W. Duch, R. Adamczak and K. Grąbczewski, Methodology of extraction, optimization and application of crisp and fuzzy logical rules. IEEE Transactions on Neural Networks {\bf 12}: 277-306, 2001. I. Nabnay and C. Bishop, NETLAB software, Aston University, Birmingham, UK, 1997. Data 3-class data, from UCI: Hypothyroid, screening tests for thyroid problems. 3772 for training (first year), 3428 cases for test; about 92.5% normal (blue), about 5% with primary hypothyroid (red), and about 2.5% with compensated hypothyroid (green). 21 attributes, 15 binary and 6 continuous (age + level of five hormones). 5-class data, from UCI: Satimage data, six types of soil images from the Landsat satellite multi-spectral scanner. The 3x3 neighborhoods of a central pixels from 4 different spectra are provided as feature vectors (36 dimensions). The last, mixed soil class, has been removed to make small figures more legible, leaving 5 classes only, and 3397 training samples.