Download
1 / 2
20 likes | 138 Views
C. E 2. E k. …. E 1. X. X. X. X. X. W. W. W. W. W. Y. Y. Y. Y. Y. Z. Z. Z. Z. Z. Q. Q. Q. Q. Q. + 3 T … 0 + 0 F … -1 - 4 F … 0.2 … - -2 T … -3. + + - … -. Structure Extension to Logistic Regression:

E N D
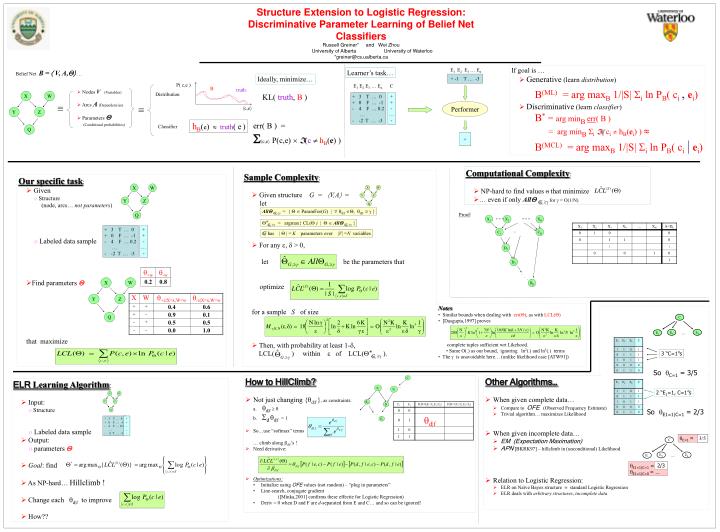
C E2 Ek … E1 X X X X X W W W W W Y Y Y Y Y Z Z Z Z Z Q Q Q Q Q + 3 T … 0 + 0 F … -1 - 4 F … 0.2 … - -2 T … -3 + + - … - Structure Extension to Logistic Regression: Discriminative Parameter Learning of Belief Net Classifiers Russell Greiner* and Wei Zhou University of Alberta University of Waterloo *greiner@cs.ualberta.ca • If goal is … • Generative (learn distribution) B(ML) = arg maxB 1/|S| i ln PB( ci ,ei) • Discriminative (learn classifier) B*=arg minB err( B ) = arg minB i( ci hB(ei) ) B(MCL) = arg maxB 1/|S| i ln PB( ci|ei) E1 E2 E3 … En Learner’s task… Belief Net B = V, A, … Ideally, minimize… + -1 T … -3 P( c,e ) E1 E2 E3 … En C B truth • Nodes V (Variables) • Arcs A (Dependencies) • Parameters (Conditional probabilities) Distribution KL( truth, B ) + + - … - + 3 T … 0 + 0 F … -1 - 4 F … 0.2 … - -2 T … -3 Performer ≡ ≡ c,e hB(e) truth( e) err( B ) = c,eP(c,e) (c hB(e) ) Classifier + • Computational Complexity: • NP-hard to find values that minimize • … even if only AllG, for = O(1/N) • Sample Complexity: • Given structure G = V,A = let • For any , > 0, let be the parameters that optimizefor a sample S of size • Then, with probability at least 1-, LCL( ) within of LCL(*G, ). • Our specific task: • Given • Structure (node, arcs… not parameters) • Labeled data sample • Find parameters that maximize AllG, = { ParamFor(G) | d|f , d|f } … … Proof: X1 X2 XN *G, = argmax{ CL() | AllG, } + + - … - + 3 T … 0 + 0 F … -1 - 4 F … 0.2 … - -2 T … -3 … C1 CR Ghas | | =K parameters over |V| =N variables D2 D3 . . . DK • Notes: • Similar bounds when dealing with err(), as with LCL() • [Dasgupta,1997] proves complete tuples sufficient wrt Likehood. • Same O(.) as our bound, ignoring ln2(.) and ln3(.) terms • The is unavoidable here… (unlike likelihood case [ATW91]) C E2 Ek … E1 3 “C=1”s So C=1 = 3/5 • Other Algorithms… • When given complete data… • Compare to OFE (Observed Frequency Estimate) • Trivial algorithm… maximizes Likelihood • When given incomplete data… • EM (Expectation Maximation) • APN [BKRK97] – hillclimb in (unconditional) Likelihood • Relation to Logistic Regression: • ELR on Naïve Bayes structure standard Logistic Regression • ELR deals with arbitrary structures, incomplete data • How to HillClimb? • Not just changing {d|f}, as constraints: • a. d|f 0 • b. dd|f = 1 • So…use “softmax” terms… climb along d|f’s ! • Need derivative: • Optimizations: • Initialize using OFE values (not random) – “plug in parameters” • Line-search, conjugate gradient ([Minka,2001] confirms these effectie for Logistic Regression) • Deriv = 0 when D and F are d-separated from E and C… and so can be ignored! C • ELR Learning Algorithm: • Input: • Structure • Labeled data sample • Output: • parameters • Goal: find • As NP-hard… Hillclimb ! • Change each d|fto improve • How?? … F1 F2 2 “E1=1, C=1”s E2 D So E1=1|C=1 = 2/3 … E1 C=1 = 3/5 E1=1|C=1 = 2/3 E1=1|C=0 = … 2/3
C Ek E1 E2 Ek E7 C … E2 Ek E1 This work was partially funded by NSERC and by Syncrude. NaïveBayes Structure TAN Structure Empirical Results C • NaïveBayes Structure • Attributes independent, given Class • Complete Data • Every attribute of every instance specified • 25 Datasets • 23 from UCI, continuous + discrete • 2 from SelectiveNB study • (used by [FGG’96]) E2 Ek … E1 • TAN structure: • Link from Class node to each attribute • Tree-structure connecting attributes • Permits dependencies between attributes • Efficient Learning alg; Classification alg • Works well in practice… [FGG’97] • TAN can deal with depend attributes,NB cannot • … but ELR is designed to help classifyOFE is not • NB does poorly on CORRAL • artificial dataset, fn of 4 attribute • Gen’l: NB+ELR TAN+OFE • TAN+ELR did perfectly on CORRAL! • TAN+ELR NB+ELR • TAN+ELR > TAN+OFE(p<0.025) • Chess domain • ELR-OFE: • Initialize params using OFE values • Then run ELR All 25 Domains • Below y=x NB+ELR better than NB+OFE • Bars are 1 standard deviation ELR better than OFE ! (p<0.005) Complete data: Missing Data Correctness of Structure • Compare NB+ELR to NB+OFE wrt • increasingly “non-NB data” • So far, each dataset complete • includes value of • every attribute in each instance • Now… some omissions • Omit values of attributes • w/ prob = 0.25 • “Missing Completely at Random” • OFE works only with COMPLETE data • Given INCOMPLETE data: • EM (Expectation Maximization) • APN(Adaptive Probabilistic Networks [BKRK97] ) • Experiments using • NaïveBayes, TAN • Why does ELR work so well • vs OFE(complete data) • vs EM / APN(incomplete data) for fixed simple structure (NB, TAN) ? • “Generative” Learner (OFE/APN/EM) • very constrained by structure… • So if structure is wrong, cannot do well! • “Discriminative” Learner (ELR) • not as constrained! C C #0 C #1 #2 E1 E2 E3 E1 E2 E3 E4 E1 E2 E3 E4 E4 25% MCAR omissions: • P(C) = 0.9 P(Ei|C) = 0.2 P(Ei|~C) = 0.8 • … then P(Ei|E1)=1.0, P(Ei|~E1)=0.0 when “joined”for model#2, model#3, … • Measured Classification Error • k=5, 400 records, … • NB+ELRbetter thanNB+EM, NB+APN (p<0.025) • TAN+ELRTAN+EM TAN+APN • TAN algorithm problematic… • as incomplete data Summary of Results • Future work: • Now: assume fixed structure • Learn STRUCTURE as well… discriminately • NP-hard to learning LCL-optimal parameters … • arbitrary structure • incomplete data What is complexity if complete data? … simple structure? Other Studies Analysis • OFE guaranteed to find parameters • optimal wrt Likelihood • for structure G • If G incorrect… • optimal-for-G is bad wrt true distribution wrong answers to queries • … ELR not as constrained by G… • can do well, even when structure incorrect! • ELR useful, as structure often incorrect • to avoid overfitting • constrained set of structures (NB, TAN, …) • See Discriminative vs Generative learning… • Complete Data • Incomplete data Nearly correct structure • Given data: • Use PowerConstructor [CG02,CG99] to build structure • Use OFE vs ELR to find parameters • For Chess: TAN + ELR > TAN + OFE NB + ELR > NB + OFE Insert fig 2b from paper! Contributions: • Motivate/Describe • discriminative learning for BN-parameters • Complexity of task (NP-hard, poly sample size) • Algorithm for task, ELR • complete or incomplete data • arbitrary structures • soft-max version, optimizations, … • Empirical results showing ELR works + study to show why… • Clearly a good idea… • should be used for Classification Tasks! • ELR was relatively slow • 0.5 sec/iteration for small, … minutes for large data • much slower than OFE • APN/EM • … same alg for Complete/INcomplete data • … ELR used unoptimized JAVA code Correct structure, incomplete data • Consider Alarm [BSCC89] structure (+ param): • 36 nodes, 47 links, 505 params • Multiple queries • 8 vars as pool of query vars • 16 other vars as pool of evidence vars • Each query: 1 q.var; each evid var w/prob ½ … so expect 16/2 evidence • NOTE: different q.var for different queries! (Like multi-task learning) • Results: TradeOff • Most BN-learners • Spend LOTS of time learning structure • Little time learning parameters • Why not… • Use SIMPLE (quick-to-learn) structure • Focus computational effort on getting good parameters C Related Work … E2 Ek E1 • Lots of work on learning BNs… most Generative learning • Some discriminative learners but most… • learn STRUCTURE discriminatively • then parameters generatively ! • See also Logistic Learning • [GGS’97] learns params discriminatively but… • different queries, L2-norm (not LCL) • needed 2 types of data-samples, … C=1 Insert fig 6c from paper! E=1|C=1



















