Download

1 / 10
100 likes | 277 Views
BIRN Uniform Web Services. Rationale, desiderata/scope, and benefits Activities to date existing external APIs (ABA, MAGE/FUGE, Gene Network…) services in BIRN Data modeling for several initial data types Development steps, and resource implications. BIRN Uniform Web Services.

E N D
BIRN Uniform Web Services • Rationale, desiderata/scope, and benefits • Activities to date • existing external APIs (ABA, MAGE/FUGE, Gene Network…) • services in BIRN • Data modeling for several initial data types • Development steps, and resource implications
BIRN Uniform Web Services Service Oriented Architecture is the backbone of CI projects n many domains • Cross-platform • Functionality well-defined and described in a standard manner - scalable • Organized in simple, sufficiently granular but self-contained modules • Loosely coupled, and can be organized into workflows as needed • A public face of the project; encourages third-party development (esp. client applications), and makes the infrastructure self-growing, easy to contribute to • Can be called from many standard COTS applications • Compatible with approaches for architecting client applications (e.g. plugin) Charge of the BIRN WS API effort: We have several data types accessed by atlases and other applications: microarray data, 2D images, 3D volumes, surfaces, segmentations, annotations, phenotype/behavioral data, FMRI, time series, etc. Some of them have common representation models (e.g. MAGE), but the models are typically large and exist in multiple incarnations. Their complexity and provided level of detail are often a barrier for adoption – and also not needed for data discovery and common data access and integration tasks. So it would be useful to envelope such data in a common set of services to expose the most essential data characteristics and support the common denominator queries across datasets (e.g. getDatasetInfo, getSubjects…) and against each particular data type (e.g. getGenes, getProbes, getStructures...). Such services would support multiple clients, including atlases, BDR interface, mediator, etc.
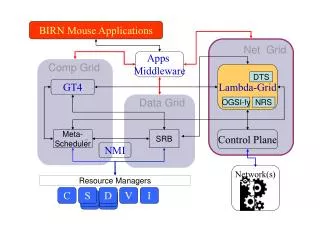
Architecture; data types and interfaces MBAT WOMBAT Other clients DataRegistrationPortlets publication Discovery, Retrieval, Analysis, Viz, Integration APIs Mediator Catalog wrappers, following uniform web service APIs Catalogs and indexes Spatial Registry BIRNLex, etc. CCDB Publication Gene Expression 2D Images 2D vector segmentations 3D Volumes SRB, other sources Surfaces Phenotype / behavioral 4+D Volumes (FMRI) Time Series Source wrappers, following uniform web service APIs Sources Sources Sources
Existing APIs • XCEDE (common schema for BIRN imaging databases) – web service wrappers are being developed (get/put projects, subjects, studies, visits, series, data…) • MAGE-ML, MAGE/FUGE: from Microarray Gene Expression Object Model (MAGE-OM), used to describe microarray designs, manufacturing information, experiment setup and execution information, gene expression data and data analysis results • Mediator services: ExecuteQuery, fetchResults… • BIRN MA module: getProbes, getMyProbes… • Gensat: getGene, get2Dimage… • GeneNetwork: by species, tissue, symbol, probe, function… • ABA: ImageSeries, Expression Energy Volumes, Genes, GetImage, ImageProperties… • Spatial Registry and ArcIMS image services: ImageMetadataForROI, ImageQueryService… : Many similar service signatures…
Simple model and services for gene expression data, as of 5/29/08 Species Geneticmanipulations (biowarehouse) Subjects (Stage|age, sex) Strains (genetic manipulations CCDB getSpecies, getSpeciesInfo getSubjects, .. getGenes({probeseries}) ,..getGenes({tissue}) getProbes({Genes}) getProbeTissues getGE ({probeTissues}) Tissues (incl. pointer totissue vocabulary) Probes (resolution, failed or not) Genes (from a masterlist) Probe-tissue Catalog GE values (categorical ornumeric) Manufacturer/ provenance Info normalization, Units, etc. Discovery stage: ultimately through GetProbeTissues call DataRetrieval: getGE
API issues • What are use cases? • What is the information model, and how a catalog is organized? • API for discovery… • E.g. images: by ROI, by labeled regions, by spatial relations, also, getImageInfo, getImageSeriesInfo • API for retrieval (e.g. getImage, getImageStack)
Issues/steps (for MA and 2Dimages) • Develop use cases prioritize data types, and for each type – data sources to expose as services (need input from ExCom) • Develop a common information model, and see if the sources can be mapped to it without significant losses (for each data type) • E.g. compare search requests and outputs as implemented in MBAT (http://www.loni.ucla.edu/twiki/bin/view/MouseBIRN/WebServices), MA module in BIRN (http://microarray.nbirn.net/), and GN (http://www.genenetwork.org/CGIDoc.html) • Examine MAGE and see how the same MA requests and output can be expressed in MAGE. • In parallel, review the schema used in the MA module, for whether it sufficiently reflects information model for GE data, and update as necessary • Identify additional sources or databases to be wrapped in the same API (GN, Gensat, ABA, BIRN MA + GEO +UCSC (VISIGENE) – for MA data; CCDB, ABA, ArcIMS, spatial registry, Gensat – for 2D). Then finalize the signatures. • Make sure terms used in queries and in the output, are tagged with BIRNLex terms (e.g. develop controlled vocabularies for each term) • Implement web services for the GN and MA module (incl testing/deployment) • Develop a joint catalog of gene expression data, make sure it is in sync with sources, and sufficient for data discovery • Update data publication tools (i.e. software for loading data from common CSV and text files into the MA module), make sure controlled vocabularies are enforced; • Make sure CCDB-based wrapper (XCEDE?) supports the services as well(?). • Publish and document web services; develop a series of examples of how they can be called from various programming environments and applications • GEO API: connect the region names with MBAT: need semantic registration;possibly scrape the GEO catalog, reconcile labels with MBAT semantics, and have a service wrapper into GEO data,
Deliverables • Use cases, information models and web service signatures for priority data types • Web service registries and cross-source data catalogs, to support data discovery • Catalog: schema, discovery interfaces, maintenance and syncing, service registry and registration interface • Web service wrappers for retrieving data from registered sources Can only be successful if it is a community development process: design participation and feedback, testing, demo implementations, clients…
Resource Implications • Resources inadequate so far (limited to reviews, information model design); • better resource requirements after cross-testbed meeting (this afternoon) • Needed expertise in both neuroscience data modeling, and services • Expertise is in BIRN CC, and spread across test beds • Preliminary: • A core development group (2-3 people) • Verifying that the proposed information models adequately describe sources (test beds) • Writing source wrappers and data publication tools • Creating data catalogs and service registries • Standard governance • Testing, documentation, deployment, marketing, tutorials • Encouraging community development