Download
1 / 28
460 likes | 815 Views
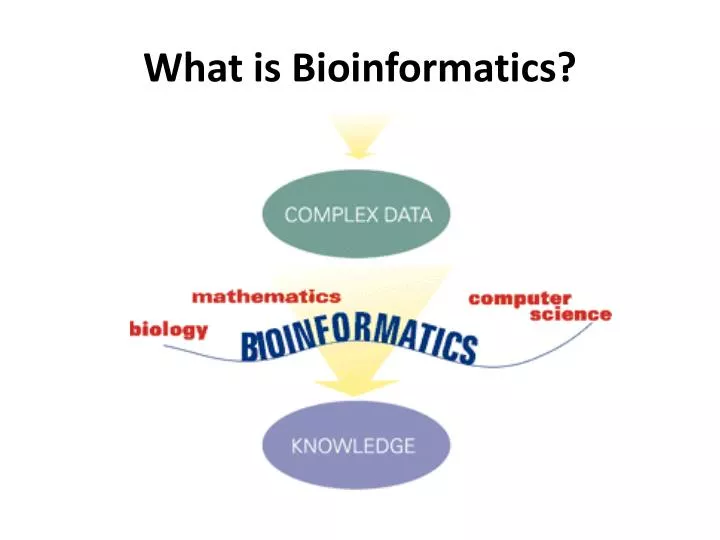
What is Bioinformatics?. What is Bioinformatics?. Conceptualizing biology in terms of molecules and then applying “informatics” techniques from math, computer science, and statistics to understand and organize the information associated with these molecules on a large scale. Focus.

E N D
What is Bioinformatics? Conceptualizing biology in terms of molecules and then applying “informatics” techniques from math, computer science, and statistics to understand and organize the information associated with these molecules on a large scale
Profile of a bioinformatician • (General) knowledge of biology and genome sciences • Translation biology <-> informatics • Knowledge of Unix-based operating systems • Programming skills (Java, Python, Shell/Perl scripting, R) • (Parallel) computing environments • Data storage and database technology • Statistics • Mathematics Freely adapted from Richter et al (2009) PLoS computational biology
How do we use Bioinformatics? • Store/retrieve biological information (databases) • Retrieve/compare gene sequences • Predict function of unknown genes/proteins • Search for previously known functions of a gene • Compare data with other researchers • Compile/distribute data for other researchers
Other bioinformatics organisations • European Bioinformatics Institute (EBI) • http://www.ebi.ac.uk/ • National Center for Biotechnology Information (NCBI) • http://www.ncbi.nlm.nih.gov/ • EMBnet • http://www.embnet.org/ • International Society for Computational Biology (ISCB) • http://www.iscb.org/
1965 Margaret Dayhoff's Atlas of Protein Sequences 1970 Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987 Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990 The HTTP 1.0 specification is published. First HTML document. 1990 Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995 Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 e-Science was introduced by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001Genetical Genomics (Ritsert Jansen) 2002BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways History of bioinformatics
1965 Margaret Dayhoff's Atlas of Protein Sequences 1970 Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987 Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990 The HTTP 1.0 specification is published. First HTML document. 1990 Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995 Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 e-Science was introduced by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001Genetical Genomics (Ritsert Jansen) 2002BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways
1965 Margaret Dayhoff's Atlas of Protein Sequences 1970Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987 Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990 The HTTP 1.0 specification is published. First HTML document. 1990 Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995 Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 e-Science was introduced by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001Genetical Genomics (Ritsert Jansen) 2002BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways
Global alignment (toy example) CATGATGA CTGAGAT Can you “align” these two sequences introduce “gaps” in these two sequences such that you maximize the number of matching nucleotides
Global alignment (toy example) CATGATGA CTGAGAT CATGATGA- C-TGA-GAT Helps us to understand the function of ‘new’DNA Dynamic programming gives optimalsolution… … but is slow. Oftenheuristicmethods are used (BLAST, BLAT)
1978 PaulienHogeweg (1943) Dutch theoretical biologist and complex systems researcher studying biological systems as dynamic information processing systems at many interconnected levels. Together with Ben Hesper she coined the term Bioinformatics in 1978 as the study of informatic processes in biotic systems Hogeweg, P. (1978). Simulating the growth of cellular forms. Simulation 31, 90-96; Hogeweg, P. and Hesper, B. (1978) Interactive instruction on population interactions. ComputBiol Med 8:319-27.
1965 Margaret Dayhoff's Atlas of Protein Sequences 1967 Scientific director of NBIC was born 1970 Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982 GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987 Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988 EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990 The HTTP 1.0 specification is published. First HTML document. 1990 Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995 Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 e-Science was introduced by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001 Genetical Genomics (Ritsert Jansen) 2002 BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways
1965 Margaret Dayhoff's Atlas of Protein Sequences 1967 Scientific director of NBIC was born 1970 Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982 GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987 Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988 EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990 The HTTP 1.0 specification is published. First HTML document. 1990 Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995 Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 e-Science was introduced by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001 Genetical Genomics (Ritsert Jansen) 2002 BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways
1965 Margaret Dayhoff's Atlas of Protein Sequences 1967 Scientific director of NBIC was born 1970 Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982 GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988 EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990The HTTP 1.0 specification is published. First HTML document. 1990Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 e-Science was introduced by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001 Genetical Genomics (Ritsert Jansen) 2002 BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways
1965 Margaret Dayhoff's Atlas of Protein Sequences 1967 Scientific director of NBIC was born 1970 Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987 Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990 The HTTP 1.0 specification is published. First HTML document. 1990 Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995 Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 e-Science was introduced by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001Genetical Genomics (Ritsert Jansen) 2002BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways
1965 Margaret Dayhoff's Atlas of Protein Sequences 1967 Scientific director of NBIC was born 1970 Needleman-Wunsch algorithm (global alignment) 1977 DNA sequencing and software to analyze it (Staden) 1981 Smith-Waterman algorithm developed (local sequence alignment) 1981 The concept of a sequence motif (Doolittle) 1982 GenBank made public 1983 Sequence database searching algorithm (Wilbur-Lipman) 1987 Perl (Practical Extraction Report Language) is released by Larry Wall. 1988 National Center for Biotechnology Information (NCBI) created at NIH/NLM 1988 EMBnet network for database distribution 1990 BLAST: fast sequence similarity searching 1990 The HTTP 1.0 specification is published. First HTML document. 1990 Grid computing as a metaphor for making computer power as easy to access as an electric power grid. 1994 EMBL European Bioinformatics Institute (EBI), Hinxton, UK 1995 Microsoft version 1.0 of IE. Sun version 1.0 of Java. Version 1.0 of Apache. 1997 PSI-BLAST 1997 International Society for Computational Biology was founded 1998 Worm (multicellular) genome completely sequenced 1999 The term e-Science was created by John Taylor, the Director General of the United Kingdom's Office of Science and Technology 2000 Gene Ontology (GO) 2001 The human genome (3 Giga base pairs) is published. 2001 Minimum information about a microarray experiment (MIAME; Brazma). 2001 Genetical Genomics (Ritsert Jansen, Jan Peter Nap) 2002 BioMoby. Web-service repository 2003 myGrid: personalised bioinformatics on the information grid (e.g, Taverna). 2004 Bioconductor: open software development for computational biology and bioinformatics 2005 Reactome: knowledge base of biological pathways
Bioinformatics in the Netherlands 1976 Pauline Hogeweg (theoretical biology) 1979GertVriend (proteins) 1985Computer Assisted Organic Synthesis/Computer Assisted Molecular Modelling Centre (CAOS/CAMM) was founded (Nijmegen, Jan Noordik) 1989 Jack Leunissen (first Dutch researcher with PhD in Bioinformatics) 90 ‘s Driving forces: Herman Berendsen, Charles Buys, Jacob de Vlieg 1999 CAOS/CAMM was reorganized; GertVriend becomes director of CMBI. 1999 KNAW committee(chaired by Berendsen) wrote the report ‘Bioexact’ in which strong stimulation of bioinformatics was recommended. 2000 KNCV working group bioinformatics 2000 NWO-BMI (Biomolecular informatics); program committee chaired by De Vlieg 2001 NWO/KNAW workshop ‘The future of bioinformatics in the Netherlands’ 2002 Position paper ‘De toekomst van de bioinformatica in Nederland’ representing the vision of the NWO/KNAW 2003 NBIC was founded 2003 First BioRange proposal (Vriend, Berendsen, Hertzberger, Tellegen) 2005 Start of BioRange (NBIC-I) 2008 ……………
Publication history http://dan.corlan.net/medline-trend.html
Bioinformatics tools and databases • Many different bioinformatic tools are freely available • BLAST, EMBOSS, EnsEMBL, GenScan, BioConductor,........ • Many different biological databases are freely available • GenBank, UniProtKB, KEGG,........ • Manypublications in open access journals • BMC bioinformatics • PLoScomputationalbiology • Also many commercial software packages available • Spotfire, Rosetta Resolver, Genelogic, ...... • Bioinformaticians write their own tools for specialized tasks
Sequence retrieval: National Center for Biotechnology Information GenBank and other genome databases Sequence comparison programs: BLAST GCG MacVector Protein Structure: 3D modeling programs – RasMol, Protein Explorer
Similarity Search: BLAST A tool for searching gene or protein sequence databases for related genes of interest Alignments between the query sequence and any given database sequence, allowing for mismatches and gaps, indicate their degree of similarity The structure, function, and evolution of a gene may be determined by such comparisons http://www.ncbi.nlm.nih.gov/BLAST/
70% MRCKTETGAR 90% MRCGTETGAR % identity CATTATGATA GTTTATGATT
Strengths: Accessibility Growing rapidly User friendly Weaknesses: Sometimes not up-to-date Limited possibilities Limited comparisons and information Not accurate
Need for improved Bioinformatics Genomics: Human Genome Project Gene array technology Comparative genomics Functional genomics Proteomics: Global view of protein function/interactions Protein motifs Structural databases
Data Mining Handling enormous amounts of data Sort through what is important and what is not Manipulate and analyze data to find patterns and variations that correlate with biological function
educators students bioinformatics researchers institutions





















