Download

1 / 1
10 likes | 95 Views
PMEM. DMEM. Energy Efficiency using Loop Buffer based Instruction Memory Organizations. Antonio Artes 1 2 1 Facultad de Informatica, Universidad Complutense de Madrid , Spain Email: a.artes@fdi.ucm.es 2 imec / Holst Centre, Eindhoven, the Netherlands Email: antonio.artes@imec-nl.nl.

E N D
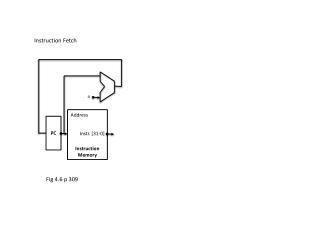
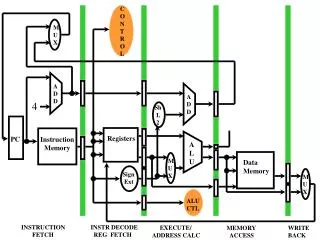
PMEM DMEM Energy Efficiency using Loop Buffer based Instruction Memory Organizations Antonio Artes1 2 1 Facultad de Informatica, Universidad Complutense de Madrid , Spain Email: a.artes@fdi.ucm.es 2 imec / Holst Centre, Eindhoven, the Netherlands Email: antonio.artes@imec-nl.nl Abstract Energy consumption in embedded systems is strongly influenced by the consumption of the instruction memory organization. Based on this, any architectural enhancement in this component of the system will cause a substantial reduction in the total energy consumption of the system. Loop buffering is an effective scheme to reduce energy consumption in the instruction memory organization. In this work, an energy design space exploration is performed focusing on different architecture variants based on the loop buffer concept. Their energy impacts on different application scenarios are also analyzed. Motivation Design space exploration • Biomedical wireless sensor nodes require sustained operation for long periods of time with minimal recharging of the battery. Therefore, a reduction in energy consumption and an increase in the lifetime reliability are required. • Memories are one of the most power consuming elements of the digital signal processing part of the sensor nodes. The architectural models mimic loops found in real embedded applications of different size and number of iterations [ DSP processor designed in Holst Centre to process ECG signals, 2009] Central loop buffer architecture for single processor organization Multiple loop buffer architecture with shared loop-nest organization Distribute loop buffer architecture with incompatible loop-nest organization Dynamic 9.2 mW Leakage 4.95 uW Loop buffer concept [Simulation methodology] Case studies Heart beat detection algorithm Y. H. Yassin, Ultra Low Power Application Specific Instruction-Set Processor design for a cardiac beat detector algorithm. Master thesis, Dept. of Electronics and Telecommunications, Norwegian University of Science and Technology and IMEC, 2009 Crypto (AES) algorithm I. Tsekoura, Design exploration of Application Specific Instruction-Set Cryptographic Processors for resources constrained systems. Master thesis, Dept. of Computer Eng. And Informatics, Univ. of Patras and IMEC, 2010 General-purpose design General-purpose design ASIP design ASIP design [PowerStone Benchmarks] • 77% of theexecution time of anapplicationisspent in loopswith 32 instructionorless. • 84% of theexecution time of anapplicationisspent in loopswith 32000 iterationorless. [Power consumption per access in 16-bit instruction word commercial 90nm SRAMs] • Conclusions • Energy savings due to the introduction of the central loop buffer architecture are directly related with the loop body size and the number of iterations. • Multiple loop buffer architectures achieve higher energy savings due to a better adaptation of the loop buffer sizes to the sizes of the loops that form the application. • There is not energy improvement using distributed loop buffer architectures with incompatible loop-nesting organization instead of multiple loop buffer architectures with shared loop-nesting organization. • A trade-off exists between the complexity of the loop buffer architecture and the energy saving. • Careful evaluation is needed when loops are not dominating the application execution time. References/ Acknowledgements [1] F. Catthoor, P. Raghavan, A. Lambrechts, M. Jayapala, A. Kritikakou, and J. Absar, Ultra-low power domain-specific instruction-set processors. Springer Publishing Company, Incorporated, 2010. [2] J. Villarreal, R. Lysecky, S. Cotterell, and F. Vahid, ¨A Study on the Loop Behavior of Embedded Programs¨, University of California, Riverside, Tech. Rep. UCR-CSE-01-03, December 2001. This research is carried out with support from Holst Centre / imec Netherlands, and partly carried out at Holst Centre. Thanks for their support to Filipa Duarte, Maryam Ashouei, Jos Huisken, José L. Ayala, David Atienza and Francky Catthoor.