Download

1 / 27
270 likes | 512 Views
XML. Document Object Model. ¿Qué es DOM?. DOM (Document Object Model) Serie de recomendaciones W3C API que define objetos presentes en documentos XML Inicialmente (DOM nivel 0) La forma que implementaron navegadores de manipular las páginas Javascript

E N D
XML Document Object Model
¿Qué es DOM? • DOM (Document Object Model) • Serie de recomendaciones W3C • API que define objetos presentes en documentos XML • Inicialmente (DOM nivel 0) • La forma que implementaron navegadores de manipular las páginas Javascript • Actualmente DOM nivel 3. Sólo algunas son ya recomendaciones • DOM Level 3 Core, DOM Level 3 Validation
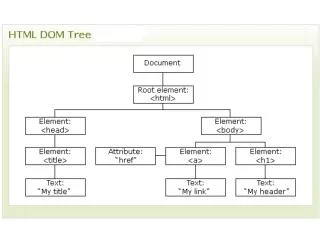
DOM como estructura • Un Document DOM es un árbol de nodos • Jerarquía contiene nodos que representan nodos XML (raíz, elemento, comentario, …) • SAX era una API muy simple • El programador debe implementar toda la lógica • No hay estado • No se puede modificar fichero • DOM abstrae al programador de la representación del árbol • Simplemente se carga el fichero y se obtiene un objeto Document con toda la estructura en memoria representada en base a objetos • Permite editar, copiar, eliminar nodos/ramas del árbol
Evolución de la API • DOM Level 1 • Soporte XML 1.0 y HTML • Cada elemento HTML representado mediante una interfaz • DOM Level 2 • Incluye soporte para namespaces • También incorpora soporte para CSS, y eventos • DOM Level 3 • Mejor soporte para crear objeto Document • Mejor soporte namespaces • Soporte para XPath
Soporte para el futuro • A través de la interfaz DOMImplementation de la API podemos determinar si la implementación que estamos usando soporta una característica ... DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder docb = dbf.newDocumentBuilder(); DOMImplementation domImpl = docb.getDOMImplementation(); if (domImpl.hasFeature("StyleSheets", "2.0")) { System.out.println(“Version 2.0 de hojas de estilo soportadas."); } else { System.out.println(“Hojas de estilo no soportadas."); } ...
Repaso a tipos de nodos XML (II) • Nodo DOM • Documento Padre de todos (nodo raíz) • Nodos básicos • Elemento, atributo, texto • Un nodo atributo contiene info sobre elemento pero no se considera realmente hijo del elemento (como en XPath) • Otros nodos • CDATA (puede contener etiquetas que no se procesan) • Comentarios (habitualmente ignorados por la aplicación) • PI • Fragmentos de documento • Un documento debe tener elemento raíz • Un fragmento no tiene por qué • Entidades, notations, …
Procesado documento XML • Cargar e interpretar un documento XML en memoria con DOM sólo se requieren tres pasos: • Crear una factoría DocumentBuilderFactory • A partir de ésta obtener un DocumentBuilder • El objeto DocumentBuilder es el que lee el fichero XML y crea el objeto Document • De forma similar a los ejemplos creados para SAX, vamos a crear una aplicación basada en DOM que imprima información sobre documentos XML.
Leyendo documentos • Creamos un nuevo proyecto y añadimos una clase EjemploDOM: import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import java.io.File; import org.w3c.dom.Document; public class EjemploDOM { public static void main(String args[]) { for (int i = 0; i < args.length; i++) { System.out.println("Procesando fichero " + args[i] + "..."); File file = new File(args[i]); Document doc = null; try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(file); } catch (Exception e) { System.out.print("Error procesando fichero: "+e.getMessage()); } } } }
Leyendo documentos (II) • Esta clase simplemente carga en memoria uno a uno los ficheros XML que se especifiquen en la línea de comandos • JAXP dispone de un parser DOM por defecto • Podemos igualmente escoger otro con: java -Djavax.xml.parsers.DocumentBuilderFactory= \ org.apache.xerces.jaxp.DocumentBuilderFactoryImpl \ -jar Programa.jar
Opciones de la factoría • Existen multitud de opciones que le podemos habilitar al parser a través de funciones que aceptan valores true/false. Algunas son: • setCoalescing(): Si se fija junta secciones CDATA con texto que lo. Falso por defecto • setExpandEntityReferences(): Determina si se expanden ENTITIES externas. True por defecto • setIgnoringComments(): Si se habilita se ignoran comentarios. False por defecto • setIgnoringElementContentWhitespace(): Si se habilita se eliminan espacios extras (como en HTML). Falso por defecto. • setNamespaceAware(): Si se habilita se presta atención a los namespaces. Falso por defecto • setValidating(): Se valida el documento contra DTD/Schema (si lo soporta el parser) especificado. Falso por defecto.
Habilitamos validación • Vamos a habilitar validación en nuestro ejemplo. Si el parser no la implementa saltará una excepción. … DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); dbf.setValidation(true); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(file); ...
Habilitamos validación • Vamos a habilitar validación en nuestro ejemplo. Si el parser no la implementa saltará una excepción. … DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); dbf.setValidation(true); DocumentBuilder db = dbf.newDocumentBuilder(); doc = db.parse(file); ...
Obteniendo el elemento raíz • Para obtener el elemento raíz de un documento utilizamos el método getDocumentElement(). • El objeto devuelto es org.w3c.dom.Element. ... //Paso 1: Obtener elemento raíz doc = db.parse(file); Element root = doc.getDocumentElement(); System.out.println("Elemento raíz: " + root.getNodeName()); ...
Obteniendo los nodos hijos • Partiendo del elemento raíz, podemos recuperar todos sus nodos hijos mediante el método del objeto ElementgetChildNodes(). ... //Paso 1: Obtener elemento raíz doc = db.parse(file); Element root = doc.getDocumentElement(); System.out.println("Elemento raíz: " + root.getNodeName()); //Paso 2: Nodos hijo del elemento raíz NodeList children = root.getChildNodes(); System.out.println("Hay "+children.getLength() +" nodos en el documento."); ...
Recorriendo el árbol • Todos los nodos disponen de métodos getFirstChild() y getNextSibling() que nos permiten recorrer el árbol. Vamos a crear una función recursiva que vaya recorriendo todo el árbol e imprimiendo los nombres y valores de los nodos. ... //Paso 3: Recorrido del árbol stepThrough(root,0); ... static void stepThrough(Node node,int level){ StringBuffer sb = new StringBuffer(); //Tantos caracteres por delante como nivel for(int i=0; i<level;i++) sb.append("-"); System.out.println(sb.toString() + node.getNodeName()+ "=“ + escapeString(node.getNodeValue())); for (Node child = node.getFirstChild(); child != null; child = child.getNextSibling()) { stepThrough(child, level+1); } }
Atributos • Los atributos no son visualizados porque no se consideran hijos de los elementos. Éstos han de recuperarse mediante getAttributes() static void stepThrough(Node node,int level){ StringBuffer sb = new StringBuffer(); //Tantos caracteres por delante como nivel for(int i=0; i<level;i++) sb.append("-"); System.out.println(sb.toString() + node.getNodeName()+ "=“ + escapeString(node.getNodeValue())); • if(node.getAttributes()!=null){ if(node.getAttributes()!=null){ NamedNodeMap atts = node.getAttributes(); for(int i=0;i< atts.getLength();i++ ){ System.out.println(sb.toString() +" Atributo: " + atts.item(i).getNodeName()+"="+ escapeString(atts.item(i).getNodeValue())); } } for (Node child = node.getFirstChild(); child != null; child = child.getNextSibling()) { stepThrough(child, level+1); } }
Ejemplo2: Manipulación de árboles • Vamos a crear otro ejemplo que demuestre que DOM no sólo permite recorre un árbol, sino también modificarlo y visualizarlo • Creamos un nuevo proyecto para EjemploDOM2 • Partimos del ejemplo anterior • El programa se alimentará con un fichero suma-entrada.xml <?xml version="1.0" encoding="utf-8"?> <suma> <sumando>1.4</sumando> <sumando>21.4</sumando> <sumando>31.24</sumando> <sumando>0.4</sumando> <sumando>2.15</sumando> <sumando>7</sumando> </suma> • El programa deberá procesar los elementos <sumando> y generar un elemento que insertará al final <resultado> con el resultado de la suma
Esqueleto • Ahora sólo vamos a procesar un único fichero de entrada import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import java.io.File; import org.w3c.dom.*; public class EjemploDOM2 { public static void main(String args[]) { if(args.length == 0){ System.err.println("No se ha especificado ningún fichero de entrada"); System.exit(1); } File file = new File(args[0]); } }
Lectura del fichero • Igual que antes hay que leer el fichero Document doc = null; try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); dbf.setValidating(true); doc = db.parse(file); //Paso 1: Obtener elemento raíz Element root = doc.getDocumentElement(); } catch (Exception e) { System.out.print("Error procesando fichero: "+e.getMessage()); e.printStackTrace(); }
Procesado del documento • El segundo paso va a ser leer el que realice los cálculos. Llamaremos a una función computeAdition: … //Paso 1: Obtener elemento raíz Element root = doc.getDocumentElement(); //Paso 2: Realizamos los cálculos double suma = computeAdition(root); …
Procesado del documento (II) • Función computeAdition: static double computeAdition(Element root) throws Exception { double suma = 0; if(!root.getNodeName().equals("suma")){ throw new Exception("El elemento raíz debe ser <suma>"); } if(root.hasChildNodes()){ NodeList children = root.getChildNodes(); for(int i=0; i<children.getLength();i++){ if(children.item(i).getNodeType()!=Node.ELEMENT_NODE) continue; if(!children.item(i).getNodeName().equals("sumando")){ throw new Exception("Elemento no soportado (debe ser <sumando>): " + children.item(i).getNodeName()); } Node sumando = children.item(i).getFirstChild(); if(sumando == null || sumando.getNodeType() != sumando.TEXT_NODE) throw new Exception("Sumando con contenido incorrecto"); try{ suma += Double.parseDouble(sumando.getNodeValue()); }catch(NumberFormatException e){ throw new Exception("Valor de sumando inválido"); } } } return suma; }
Modificación del árbol • Para modificar el árbol hemos de crear primeramente los nodos a través de las fuciones de DocumentcreateNode() o createXXXNode() • Después se insertan los nodos mediante funciones appendChild() ó insertBefore() ... //Paso 2: Realizamos los cálculos double suma = computeAdition(root); //Paso 3: Insertamos nuevos nodos insertResult(doc, root, suma); ... static void insertResult(Document doc, Element root, double result){ Node texto = doc.createTextNode("" + result); Node elemento = doc.createElement("resultado"); elemento.appendChild(texto); root.appendChild(elemento); }
Imprimir árbol • Para imprimir la salida del árbol a un documento XML hay varias alternativas • La más sencilla Ir imprimendo el código XML en base a la información del árbol if(node.getNodeType()==Node.ELEMENT_NODE) System.out.println(“<“+node.getNodeName()+”>); • Utilizar una transformación de identidad. Se trata de una transformación XSLT (API javax.xml.transform) sin aplicar ninguna plantilla.
Imprimir árbol (II) • Ejemplo impresión por transformación: ... import javax.xml.transform.TransformerFactory; import javax.xml.transform.Transformer; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import java.io.FileOutputStream; ... try { DOMSource source = new DOMSource(newdoc); StreamResult result = new StreamResult(new FileOutputStream("processed.xml")); TransformerFactory transFactory = TransformerFactory.newInstance(); Transformer transformer = transFactory.newTransformer(); transformer.transform(source, result); } catch (Exception e){ e.printStackTrace(); }
Imprimir árbol (III) • La tercera alternativa es utilizar un XMLSerializer de la API de Apache, que permite dar formato a la salida, como los espacios de indentación, si se imprimirá la cabecera xml, etc. ... // Para serializar import org.apache.xml.serialize.OutputFormat; import org.apache.xml.serialize.XMLSerializer; import org.apache.xml.serialize.DOMSerializer; import java.io.StringWriter; ... //Paso 3: Insertamos nuevos nodos insertResult(doc, root, suma); ... static void printDocument(Document doc) throws Exception { OutputFormat outputOptions = new OutputFormat(); outputOptions.setOmitXMLDeclaration(true); outputOptions.setIndent( 4 ); outputOptions.setMethod( "xml" ); StringWriter output = new StringWriter(); DOMSerializer serializer = new XMLSerializer(output, outputOptions); serializer.serialize(doc); System.out.print(output.getBuffer()); }
Ejercicios • Se puede profundizar más en la práctica • Insertando el resultado en otra parte del documento • Computando datos desde atributos • Insertando atributos en vez de elementos