Download
1 / 1
10 likes | 54 Views
Risk modeling of colorectal cancer using machine learning algorithms on a hybridized genealogical and clinical dataset.

E N D
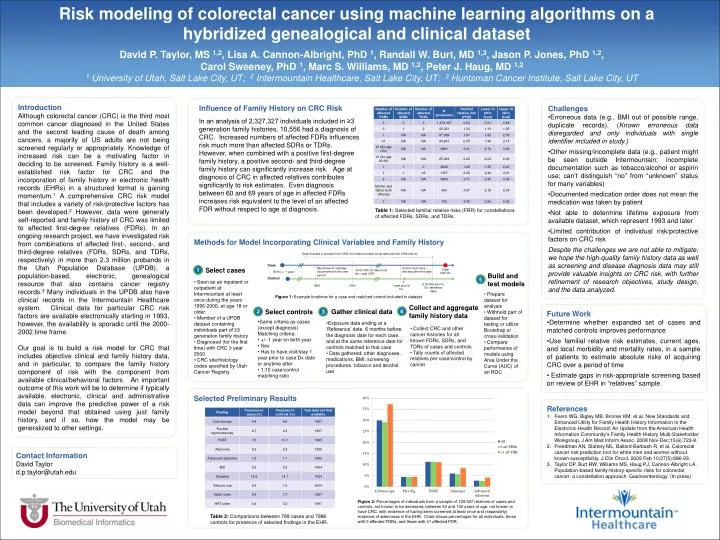
Risk modeling of colorectal cancer using machine learning algorithms on a hybridized genealogical and clinical dataset • David P. Taylor, MS 1,2, Lisa A. Cannon-Albright, PhD 1, Randall W. Burt, MD 1,3, Jason P. Jones, PhD 1,2, Carol Sweeney, PhD 1, Marc S. Williams, MD 1,2, Peter J. Haug, MD 1,2 • 1 University of Utah, Salt Lake City, UT; 2 Intermountain Healthcare, Salt Lake City, UT; 3 Huntsman Cancer Institute, Salt Lake City, UT Introduction Although colorectal cancer (CRC) is the third most common cancer diagnosed in the United States and the second leading cause of death among cancers, a majority of US adults are not being screened regularly or appropriately. Knowledge of increased risk can be a motivating factor in deciding to be screened. Family history is a well-established risk factor for CRC and the incorporation of family history in electronic health records (EHRs) in a structured format is gaining momentum.1 A comprehensive CRC risk model that includes a variety of risk/protective factors has been developed.2 However, data were generally self-reported and family history of CRC was limited to affected first-degree relatives (FDRs). In an ongoing research project, we have investigated risk from combinations of affected first-, second-, and third-degree relatives (FDRs, SDRs, and TDRs, respectively) in more than 2.3 million probands in the Utah Population Database (UPDB), a population-based, electronic, genealogical resource that also contains cancer registry records.3 Many individuals in the UPDB also have clinical records in the Intermountain Healthcare system. Clinical data for particular CRC risk factors are available electronically starting in 1993, however, the availability is sporadic until the 2000-2002 time frame. Our goal is to build a risk model for CRC that includes objective clinical and family history data, and in particular, to compare the family history component of risk with the component from available clinical/behavioral factors. An important outcome of this work will be to determine if typically available, electronic, clinical and administrative data can improve the predictive power of a risk model beyond that obtained using just family history, and if so, how the model may be generalized to other settings. Influence of Family History on CRC Risk • Challenges • Erroneous data (e.g., BMI out of possible range, duplicate records). (Known erroneous data disregarded and only individuals with single identifier included in study.) • Other missing/incomplete data (e.g., patient might be seen outside Intermountain; incomplete documentation such as tobacco/alcohol or aspirin use; can’t distinguish “no” from “unknown” status for many variables) • Documented medication order does not mean the medication was taken by patient • Not able to determine lifetime exposure from available dataset, which represent 1993 and later • Limited contribution of individual risk/protective factors on CRC risk • Despite the challenges we are not able to mitigate, we hope the high-quality family history data as well as screening and disease diagnosis data may still provide valuable insights on CRC risk, with further refinement of research objectives, study design, and the data analyzed. In an analysis of 2,327,327 individuals included in ≥3 generation family histories, 10,556 had a diagnosis of CRC. Increased numbers of affected FDRs influences risk much more than affected SDRs or TDRs. However, when combined with a positive first-degree family history, a positive second- and third-degree family history can significantly increase risk. Age at diagnosis of CRC in affected relatives contributes significantly to risk estimates. Even diagnosis between 60 and 69 years of age in affected FDRs increases risk equivalent to the level of an affected FDR without respect to age at diagnosis. Select cases 1 2 4 5 3 Select controls Gather clinical data Table 1: Selected familial relative risks (FRR) for constellations of affected FDRs, SDRs, and TDRs. Collect and aggregate family history data Methods for Model Incorporating Clinical Variables and Family History Data included in analysis from 1993 until reference date (most data are from 1998 and on) Build and test models Case Must have ≥1 visit/stay documented in this time period Control must have visit/stay after this date Case CRC Dx • First CRC Dx date must be > year 2000 Birth (+/- 1 year) Control 6 months prior to Dx (reference date) 1996 2000 1 year prior to Dx • Seen as an inpatient or outpatient at Intermountain at least once during the years 1996-2000, at age 18 or older. • Member of a UPDB dataset containing individuals part of ≥3 generation family history • Diagnosed (for the first time) with CRC ≥ year 2000 • CRC site/histology codes specified by Utah Cancer Registry • Prepare dataset for analysis • Withhold part of dataset for testing or utilize Bootstrap or cross-validation • Compare performance of models using Area Under the Curve (AUC) of an ROC Figure 1: Example timelines for a case and matched control included in dataset • Future Work • Determine whether expanded set of cases and matched controls improves performance • Use familial relative risk estimates, current ages, and local morbidity and mortality rates, in a sample of patients to estimate absolute risks of acquiring CRC over a period of time • Estimate gaps in risk-appropriate screening based on review of EHR in “relatives” sample • Same criteria as cases (except diagnosis)Matching criteria: • +/- 1 year on birth year • Sex • Has to have visit/stay 1 year prior to case Dx date or anytime after • 1:10 case/control matching ratio • Exposure data ending at a ‘Reference’ date 6 months before the diagnosis date for each case, and at the same reference date for controls matched to that case • Data gathered: other diagnoses, medications, BMI, screening procedures, tobacco and alcohol use • Collect CRC and other cancer histories for all known FDRs, SDRs, and TDRs of cases and controls • Tally counts of affected relatives per case/control by cancer Selected Preliminary Results • References • Feero WG, Bigley MB, Brinner KM, et.al. New Standards and Enhanced Utility for Family Health History Information in the Electronic Health Record: An Update from the American Health Information Community's Family Health History Multi-Stakeholder Workgroup. J Am Med Inform Assoc. 2008 Nov-Dec;15(6):723-8. • Freedman AN, Slattery ML, Ballard-Barbash R, et al. Colorectal cancer risk prediction tool for white men and women without known susceptibility. J ClinOncol. 2009 Feb 10;27(5):686-93. • Taylor DP, Burt RW, Williams MS, Haug PJ, Cannon-Albright LA. Population-based family-history-specific risks for colorectal cancer: a constellation approach. Gastroenterology. (In press) Contact Information David Taylor d.p.taylor@utah.edu Figure 2: Percentages of individuals from a sample of 128,927 relatives of cases and controls, not known to be deceased, between 50 and 100 years of age, not known to have CRC, with evidence of having been screened at least once and (separately) evidence of adenomas in the EHR. Chart shows percentages for all individuals, those with 0 affected FDRs, and those with ≥1 affected FDR. Table 2: Comparisons between 789 cases and 7886 controls for presence of selected findings in the EHR.