Download
1 / 3
30 likes | 136 Views
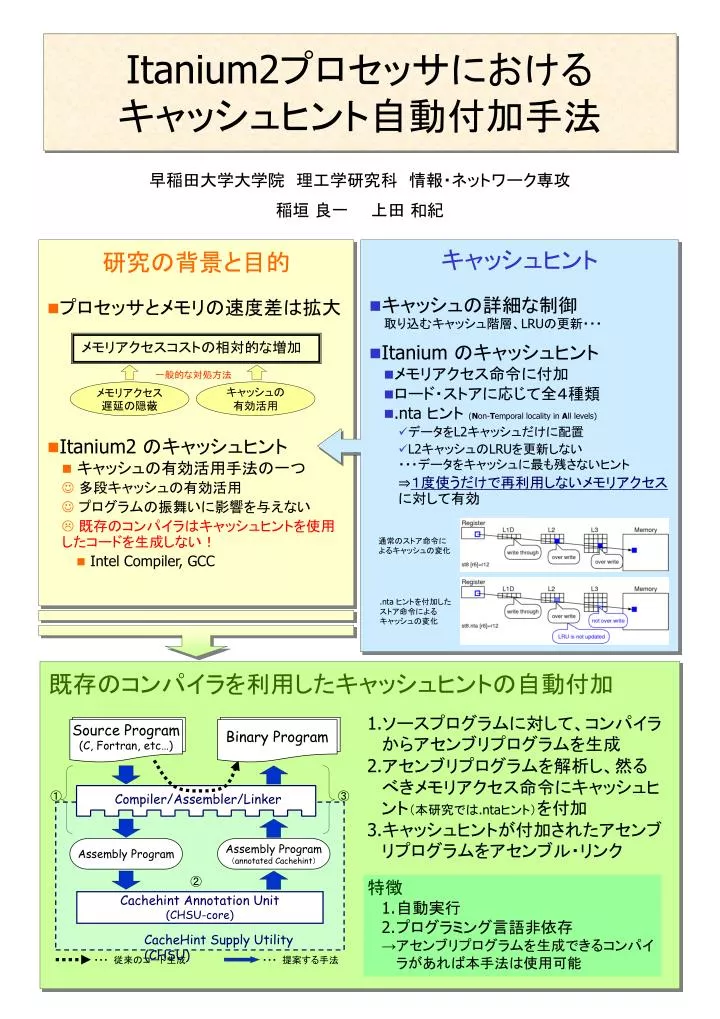
早稲田大学大学院 理工学研究科 情報・ネットワーク専攻. 稲垣 良一 上田 和紀. メモリアクセスコストの相対的な増加. 一般的な対処方法. メモリアクセス遅延の隠蔽. キャッシュの 有効活用. 通常のストア命令によるキャッシュの変化. . nta ヒントを付加したストア命令によるキャッシュの変化. Binary Program. Source Program ( C, Fortran, etc…). Binary Program. ①. ③. Compiler/Assembler/Linker. Assembly Program.

E N D
早稲田大学大学院 理工学研究科 情報・ネットワーク専攻早稲田大学大学院 理工学研究科 情報・ネットワーク専攻 稲垣 良一 上田 和紀 メモリアクセスコストの相対的な増加 一般的な対処方法 メモリアクセス遅延の隠蔽 キャッシュの 有効活用 通常のストア命令によるキャッシュの変化 .nta ヒントを付加したストア命令によるキャッシュの変化 Binary Program Source Program (C, Fortran, etc…) Binary Program ① ③ Compiler/Assembler/Linker Assembly Program Assembly Program (annotated Cachehint) Cachehint Annotation Unit (CHSU-core) CacheHint Supply Utility (CHSU) ・・・ 提案する手法 ・・・ 従来のコード生成 Itanium2プロセッサにおける キャッシュヒント自動付加手法 • 研究の背景と目的 • プロセッサとメモリの速度差は拡大 • Itanium2のキャッシュヒント • キャッシュの有効活用手法の一つ • 多段キャッシュの有効活用 • プログラムの振舞いに影響を与えない • 既存のコンパイラはキャッシュヒントを使用したコードを生成しない! • Intel Compiler, GCC • キャッシュヒント • キャッシュの詳細な制御 取り込むキャッシュ階層、LRUの更新・・・ • Itanium のキャッシュヒント • メモリアクセス命令に付加 • ロード・ストアに応じて全4種類 • .nta ヒント (Non-Temporal locality in All levels) • データをL2キャッシュだけに配置 • L2キャッシュのLRUを更新しない ・・・データをキャッシュに最も残さないヒント ⇒1度使うだけで再利用しないメモリアクセスに対して有効 既存のコンパイラを利用したキャッシュヒントの自動付加 • ソースプログラムに対して、コンパイラからアセンブリプログラムを生成 • アセンブリプログラムを解析し、然るべきメモリアクセス命令にキャッシュヒント(本研究では.ntaヒント)を付加 • キャッシュヒントが付加されたアセンブリプログラムをアセンブル・リンク • 特徴 • 自動実行 • プログラミング言語非依存 • →アセンブリプログラムを生成できるコンパイラがあれば本手法は使用可能 ②
… br.ret L10: … br L10: Program Block Procedure Block Block Block Block Block Procedure Block Block Block CHSUの設計 • アセンブリプログラムの解析 • 3階層のデータ構造に分類 • Program–プログラム全体 • Procedure–プロシージャ(関数) • Block–アセンブリプログラム中のラベルで 区切られるプログラム部分 • Procedure 外のディレクティブなどは Block として 保持するが、解析時は無視する Blockが保持する情報 ・ラベル名 ・アセンブリプログラム原文 ・Block 中で使用されている命令の種類、数 ・分岐命令の分岐先ラベル 解析後のアセンブリプログラムのデータ構造 • キャッシュヒント付加方針 方針:プログラムの時間局所性に注目 ①局所性が高い部分(例:forループ)のメモリアクセス命令について、次のように仮定 ②局所性が低い部分のメモリアクセス命令については再利用されないと仮定 • 以上の仮定より、プログラムの局所性と .ntaヒント付加の関係はストア・ロード命令でそれぞれ次のようになる ○・・・付加 ×・・・付加しない • .nta ヒントの付加 • Procedure 単位で処理 • 各 Block が保持している分岐命令の分岐先ラベルの情報を使用 • キャッシュヒントの付加は Block 単位 • プログラム中のループ構造から • 自Blockへの分岐を持つBlock ・ループ構造そのもの ・for文, while文がアセンブリプログラム になった形であると考えられる • Block の局所性が高いと判断 → ストア命令に .nta ヒント付加 • プロシージャ・リターン命令から • 最後に実行されるBlock • 繰り返し実行される可能性は 少なく、局所性が低いと判断 →ストア命令・ロード命令に .nta ヒント付加 { .mmi (p16) lfetch.nt1 [r34] (p18) stfd [r9]=f61,64 (p16) add r45=64,r46;; } { .mmi (p18) stfd [r8]=f68,64 (p18) stfd [r3]=f60,64 (p16) add r32=128,r34 } { .mmi (p16) lfetch.nt1 [r34] (p18) stfd.nta [r9]=f61,64 (p16) add r45=64,r46;; } { .mmi (p18) stfd.nta [r8]=f68,64 (p18) stfd.nta [r3]=f60,64 (p16) add r32=128,r34 } キャッシュヒント 付加の例
Itanium2 L3上限 実装と評価 FFTE 4.0 (Intel Compiler 8.1) • 実装・評価環境 • Java による実装 • J2SE SDK 1.4.2_06 • 評価環境・・・SGI Altix350 • Intel Itanium2 Processor 1.4GHz L1: 16K, L2: 256K, L3: 3M • SGI Advanced Linux Environment • Intel Compiler 8.1, GCC 3.2.3 アセンブリプログラム生成に使用したコンパイラ 1次元FFTを実行 • 付加するキャッシュヒント、データサイズを変化させて性能を測定 • キャッシュヒントが付加されてない場合のプログラムとの性能を比較 15%性能向上 FFTE 4.0 (GCC 3.2.3) 1次元FFTを実行 プロセッサイベントの計測 (pfmon) • L3 キャッシュヒット率の向上、IPC の向上 • Total stalls (全実行時間に占めるストール時間の割合) の減少 L3 キャッシュ ヒット率 15%向上 GCC を使用した場合でも性能向上 ⇒コンパイラに依存しない性能向上を実証 ATLAS 3.6.0 (Intel Compiler 8.1) • まとめ • 提案する手法により、既存のコンパイラを使用したキャッシュヒントの自動付加が可能になった • 汎用性の高い方法 • L3キャッシュのヒット率向上 今後の課題 • 性能評価の充実 • キャッシュヒント付加方針の検討 • バイナリプログラムへの直接適用 行列積関数 (dgemm) について計測 MFLOPS ベースで 1%~2%の性能向上