Download
1 / 7
70 likes | 82 Views
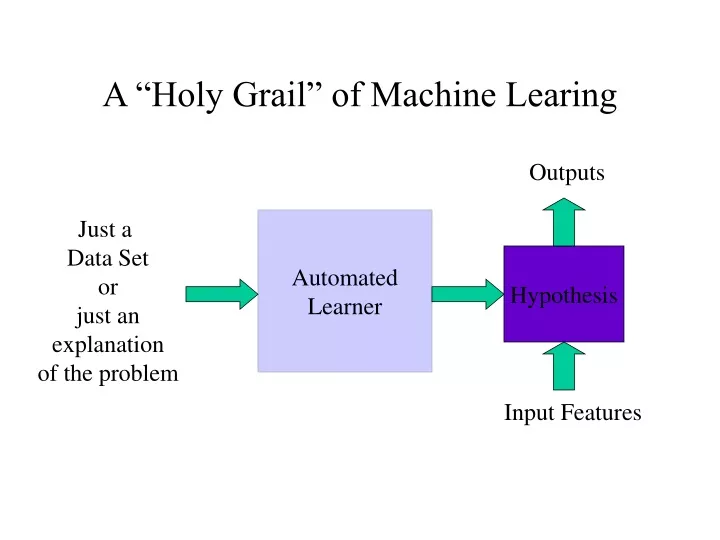
A “Holy Grail” of Machine Learing. Outputs. Just a Data Set or just an explanation of the problem. Automated Learner. Hypothesis. Input Features. Ensembles. Multiple diverse models (Inductive Biases) are trained on the same problem and then their outputs are combined

E N D
A “Holy Grail” of Machine Learing Outputs Just a Data Set or just an explanation of the problem Automated Learner Hypothesis Input Features
Ensembles • Multiple diverse models (Inductive Biases) are trained on the same problem and then their outputs are combined • The specific overfit of each learning model is averaged out • If models are diverse (uncorrelated errors) then even if the individual models are weak generalizers, the ensemble can be very accurate • Many different Ensemble approaches • Stacking, Gating/Mixture of Experts, Bagging, Boosting, Wagging, Mimicking, Combinations Combining Technique M1 M2 M3 Mn
Bias vs. Variance • Multiple trained models can average out the variance • Leaving just the Bias • Weak learners?
Bagging • Bootstrap aggregating (Bagging) • Each TS chosen uniformly at random with replacement from the original data set • All hypotheses have an equal vote • Bagging mostly focused on getting rid of variance • Consistent strong empirical improvement • Does not overfit (whereas boosting may), but may be more conservative overall on accuracy improvements • Often used with the same learning algorithms and thus best for those which tend to give more diverse hypotheses based on initial random conditions
Boosting • Many variations • Boosting more aggressive on accuracy but in some cases could overfit and do worse – can theoretically converge to training set – similar to a constructive neural network (DMP) • Boosting by resampling - (Each TS chosen randomly with distribution Di with replacement from the original data set. Typically the same size as the original data set.) • Some learning algorithms can handle the weighted samples directly • Potential to overfit, but empirically quite good
Ensemble Creation Approaches • Goal is to get less correlated errors • Injecting randomness – initial weights, different learning parameters, etc. • Different Training sets – Bagging, Boosting, different features, etc. • Forcing differences – different objective functions, auxiliary tasks • Different machine learning models
Ensemble Combining Approaches • Stacking • Unweighted Voting • Weighted voting – learned (single layer), based on accuracy, training set, • Gating function – The gating function uses the input features to decide which combination (weights) of expert voting to use