Download
1 / 1
10 likes | 98 Views
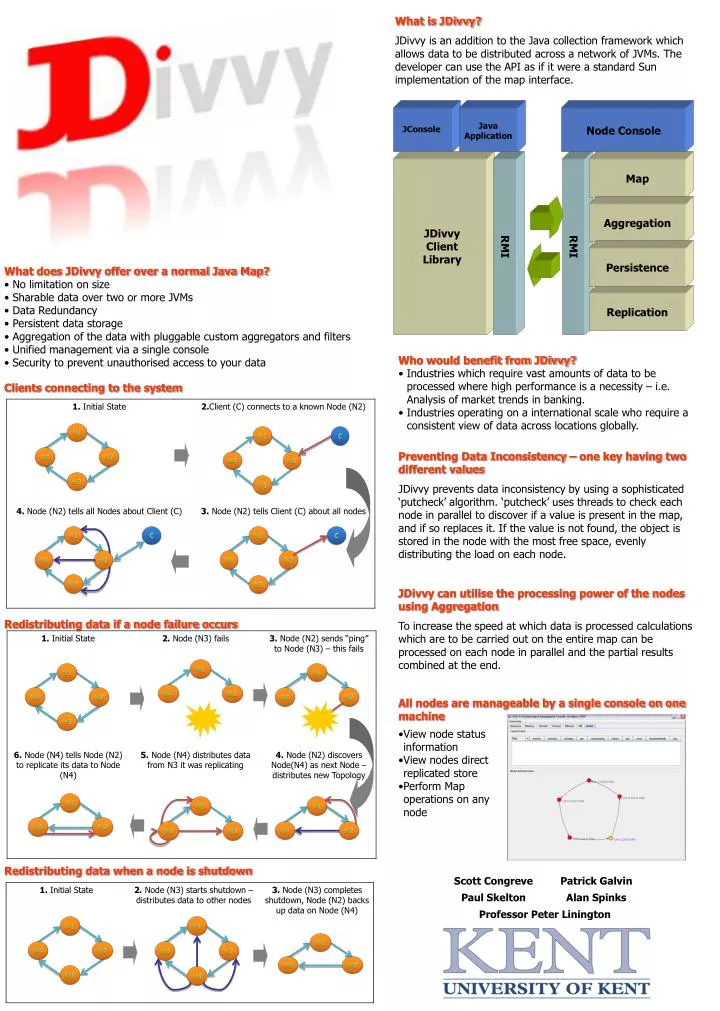
Java Application. JConsole. Node Console. RMI. RMI. Map. Aggregation. JDivvy Client Library. Persistence. Replication. What is JDivvy?

E N D
Java Application JConsole Node Console RMI RMI Map Aggregation JDivvy Client Library Persistence Replication What is JDivvy? JDivvy is an addition to the Java collection framework which allows data to be distributed across a network of JVMs. The developer can use the API as if it were a standard Sun implementation of the map interface. • What does JDivvy offer over a normal Java Map? • No limitation on size • Sharable data over two or more JVMs • Data Redundancy • Persistent data storage • Aggregation of the data with pluggable custom aggregators and filters • Unified management via a single console • Security to prevent unauthorised access to your data • Who would benefit from JDivvy? • Industries which require vast amounts of data to be • processed where high performance is a necessity – i.e. • Analysis of market trends in banking. • Industries operating on a international scale who require a • consistent view of data across locations globally. Clients connecting to the system Preventing Data Inconsistency – one key having two different values JDivvy prevents data inconsistency by using a sophisticated ‘putcheck’ algorithm. ‘putcheck’ uses threads to check each node in parallel to discover if a value is present in the map, and if so replaces it. If the value is not found, the object is stored in the node with the most free space, evenly distributing the load on each node. JDivvy can utilise the processing power of the nodes using Aggregation To increase the speed at which data is processed calculations which are to be carried out on the entire map can be processed on each node in parallel and the partial results combined at the end. Redistributing data if a node failure occurs All nodes are manageable by a single console on one machine • View node status • information • View nodes direct • replicated store • Perform Map • operations on any • node Redistributing data when a node is shutdown
