Download

1 / 58
650 likes | 977 Views
Organisation 1 - Notions fondamentales de théorie de l’information (7h) • Définitions de base • Application aux sources d’information discrète • Application aux sources d’information continue 2 - Codage pour le contrôle d’erreur (7h) • Codes en blocs linéaires • Codes cycliques

E N D
Organisation 1 - Notions fondamentales de théorie de l’information (7h) • Définitions de base • Application aux sources d’information discrète • Application aux sources d’information continue 2 - Codage pour le contrôle d’erreur (7h) • Codes en blocs linéaires • Codes cycliques • Codes convolutifs • Algorithme de Viterbi • Turbo-codes Théorie de l’Information et Codage
S. Haykin, Communication Systems, Wiley & Sons, 1994. A.J. Viterbi, K.J. Omura, Principes des communications numériques, Coll. CNET/ENST, Dunod Edt. A. Poli, L. Huguet, Codes correcteurs, Coll. LMI, Masson. H. P. Hsu, Communications analogiques et numériques, Série Schaum. Théorie de l’Information et Codage Références
1-1 Introduction 1-2 Incertitude, Information et Entropie 1-3 Théorème du codage de source 1-4 Compression de données 1-5 Canaux discrets sans mémoire 1-6 Information mutuelle 1-7 Capacité d’un canal 1-8 Théorème du codage de canal 1-9 Extension aux signaux continus 1-10 Théorème de la capacité d’information 1-11 Distorsion de l’information 1-12 Compression d’information Chapitre 1Notions fondamentales de théorie de l’information
L’objectif d’un système de transmission est de porter une information en bande de base d’un point à un autre via un canal de communication. 1948 : Shannon introduit la théorie de l’information. Dans le contexte des communications, la théorie de l’information s’attache à la modélisation mathématique et l’analyse des systèmes de communication. 1-1 Introduction
La théorie de l’information donne des réponses à deux questions : quelle est la complexité limite d’un signal ? notion d’entropie : nombre minimum d’e.b. par symbole pour représenter une source. quelle est le débit limite pour une communication fiable sur un canal bruité ? notion de capacité de canal : débit maximum qui peut être adopté pour un canal. 1-1 Introduction
Définitions Source discrète : système émettant régulièrement des symboles issus d’un alphabet fini. Alphabet : ensemble fini des symboles de la source. Source aléatoire : les symboles sont émis aléatoirement suivant les probabilités : Source sans mémoire : source aléatoire dont les symboles émis sont statistiquement indépendants. 1-2 Incertitude, Information et Entropie
Peut-on trouver une mesure de l’information produite par une source ? La notion d’information est liée à la notion de surprise et d’incertitude : avant l’évènement S = sk, il existe une certaine quantité d’incertitude sur cet évènement, quand cet évènement se réalise, il existe une certaine quantité de “surprise”, après la réalisation de l’évènement, il existe un gain en quantité d’information sur cet évènement, cette quantité d’information correspond à la “résolution” de l’incertitude de départ. la quantité d’information ne doit dépendre que de la statistique de la source. 1-2 Incertitude, Information et Entropie
Définition : la quantité d’information gagnée à l’observation de l’évènement S = sk , de probabilité pk, est définie par : I (sk) = – log pk Propriétés : I (sk) = 0 pour pk= 1 ; I (sk) >= 0 pour 0 <= pk <= 1 ; I (sk) > I (si) pour pk < pi ; I (sk sl) = I (sk) + I (sl) si sk et sl sont statistiquement indépendants. 1-2 Incertitude, Information et Entropie
Remarques : La base du logarithme dans cette définition est arbitraire ; On utilise par convention la base 2. L’unité correspondante est le bit (pour binary unit). Dans ces conditions : I (sk) = – log2pk Si pk = 1/2, alors I (sk) = 1 bit. > Un bit est la quantité d’information gagnée quand un parmi deux évènements équiprobables apparaît. En fonction de la base du logarithme, on définit d’autres unités de quantité d’information : base 10 : hartley base e : neper, nat 1-2 Incertitude, Information et Entropie
La quantité d’information produite par une source dépend du symbole émis à un instant significatif donné ; Or la source émet une séquence aléatoire de symboles ; La quantité d’information à un instant donné est donc une variable aléatoire discrète, prenant les valeurs I(s0), I(s1), ... , I(sK–1) avec les probabilités p0, p1, ... , pK–1. 1-2 Incertitude, Information et Entropie
Définition : l’entropie d’une source sans mémoire, d’alphabet A, est l’espérance mathématique de la quantité d’information prise comme variable aléatoire. Remarques : L’entropie est une mesure de l’information moyenne par symbole issu de la source. l’unité de l’entropie est le bit/symbole. 1-2 Incertitude, Information et Entropie
Propriétés : Pour une source discrète sans mémoire, l’entropieest bornée : 1. H(A) = 0 ssi pk = 1 pour un k donné, les autres probabilités étant nulles. => aucune incertitude 2. H(A) = log2K ssi pk = 1/K pour tout k . => incertitude maximale Démonstration : Exemples : 1-2 Incertitude, Information et Entropie
Un problème important en communication est celui de la représentation efficace des données engendrées par une source discrète. Ce processus est appelé codage de source (source encoding), et le dispositif correspondant un codeur de source (source encoder). L’efficacité du codage de source repose sur la connaissance de la statistique de la source. Application : si quelques symboles sont plus probables que d’autres, on peut leur assigner des mots-code “courts” (code à longueur variable ; ex : code Morse). 1-3 Théorème du codage de source
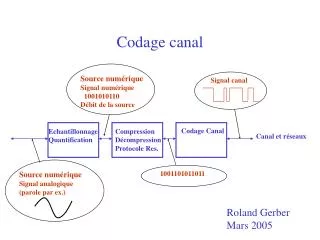
Problème : Développer un codeur de source efficace satisfaisant aux contraintes suivantes : les mots-code sont sous la forme de données binaires ; les mots-code doivent être décodés de manière unique, i.e. la séquence émise par la source doit être parfaitement reconstruite à partir de la séquence des mots-code. 1-3 Théorème du codage de source Source discrète sans mémoire sk bk Codeur de source Séquence binaire Fig 1-1
1-3 Théorème du codage de source • Définitions : • Longueur moyenne d’un code : • A chaque skde probabilité pk—> bkde longueur lke.b. • Alors • représente le nombre moyen d’e.b. par symbole. • Efficacité d’un code : • Si Lmin est la plus petite valeur possible de , on définit : • Un codeur est dit efficace si .
Problème : Comment déterminer Lmin ? Solution : Théorème du codage de source (premier théorème de Shannon) Soit une source discrète sans mémoire d’entropie H(A). La longueur moyenne des mots-code pour tout codage sans perte est bornée par : L’entropie représente donc une limite fondamentale sur le nombre d’e.b. par symbole-source nécessaire pour représenter une source sans mémoire. L’efficacité s’écrit alors : 1-3 Théorème du codage de source
Les signaux engendrés par des processus physiques contiennent généralement une certaine quantité d’information redondante, et qui peut gaspiller les ressources de communication. Pour obtenir une communication efficace, il faut supprimer cette redondance avant transmission. Cette opération est la compression de données sans perte. Propriétés : optimale au sens du nombre moyen d’e.b. par symbole, les données originales peuvent être reconstruites sans perte d’information. Principe : affecter des mots-code courts aux symboles fréquents, affecter des mots-code longs aux symboles “rares”. 1-4 Compression de données
1-4-1 Codage préfixe 1-4-2 Codage de Huffman 1-4-3 Codage de Lempel-Ziv pour sources discrètes à mémoire 1-4 Compression de données
Définition : un canal discret sans mémoire est un modèle statistique comportant une entrée X (v.a.) et une sortie Y (v.a.) qui est une version bruitée de X. A chaque unité de temps, la source émet un symbole issu de l’alphabet A. la sortie du canal discret sans mémoire est un symbole issu de l’alphabet B. Le canal est aussi caractérisé par des probabilités de transition : 1-5 Canaux discrets sans mémoire
1-5 Canaux discrets sans mémoire X Y Fig. 1-2 Canal discret sans mémoire Définition : Matrice du canal
Chaque ligne de P correspond à une entrée fixée du canal ; Chaque colonne correspond à une sortie fixée du canal ; La somme des éléments d’une ligne vaut 1 Supposons que les entrées suivent une distribution de probabilité (distribution a priori) distribution jointe distribution marginale Exemple : Canal Binaire Symétrique (CBS). 1-5 Canaux discrets sans mémoire
Problème :Y étant une version bruitée de X, et H(A)mesurant l’incertitude a priori sur X, comment mesurer l’incertitude sur X après avoir observé Y ? Définition : l’entropie conditionnelle (à l’observation de Y) de X, sachant vaut : H(A | B) représente la quantité d’incertitude restante sur l’entrée après que la sortie a été observée. 1-6 Information mutuelle
H(A) est l’incertitude sur l’entrée avant l’observation de la sortie ; H(A | B) est l’incertitude sur l’entrée après l’observation de la sortie ; H(A) – H(A | B) représente l’incertitude sur l’entrée résolue par l’observation de la sortie ; Définition :H(A) – H(A | B) est appelée information mutuelle du canal : 1-6 Information mutuelle
Propriétés : symétrie on ne peut perdre d’information , avec 1-6 Information mutuelle
Interprétation graphique - Diagramme de Venn 1-6 Information mutuelle H(A,B) H(A | B) H(B | A) I(A, B)
Le calcul de l’information mutuelle I(A, B) nécessite la connaissance de la distribution a priori de X ; En conséquence, l’information mutuelle d’un canal dépend non seulement du canal mais également de la manière dont il est utilisé ; Or la distribution a priori est (évidemment) indépendante du canal ; On peut donc chercher à maximiser l’information mutuelle par rapport à . 1-7 Capacité d’un canal
Définition : la capacité d’un canal discret sans mémoire est le maximum de l’information mutuelle I(A, B) moyenne obtenu pour l’ensemble des symboles émis, la maximisation étant opérée sur toutes les distributions a priori possibles sur A.. C se mesure en bits par utilisation du canal (bits per channel use). Remarque :le calcul de C implique la maximisation sur J variables (les probabilités d’entrée) sous deux contraintes : 1-7 Capacité d’un canal
Exemple : Canal Binaire Symétrique 1-7 Capacité d’un canal Capacité du canal C Probabilité de transition p
La présence inévitable de bruit dans le canal cause des erreurs de transmission. Pour un canal très bruité, la probabilité d’erreur peut être aussi haute que 10–2 ... Mais il est préférable qu’elle soit plus faible que 10–6, voire 10–12 ! Pour atteindre cet objectif, on a recours au codage de canal (Chapitre 2). 1-8 Théorème du codage de canal
L’objectif du codage de canal est d’accroître la résistance d’un système de communication numérique au bruit. Le codage de canal consiste à affecter, à une séquence issue de la source, une autre séquence destinée à entrer dans le canal (mapping) ; à affecter, à une séquence issue du canal, une autre séquence pour utilisation (reverse mapping) ; de telle sorte que l’effet du bruit du canal soit minimisé. 1-8 Théorème du codage de canal Source discrète sans mémoire Canal discret sans mémoire Codeur de canal Décodeur de canal Utilisation Emetteur Récepteur bruit
L’approche générale du codage de canal consiste à introduire de la redondance dans la séquence émise, de manière à reconstruire la séquence originale le plus précisément possible. codage de source —> diminution de la redondance, ... codage de canal —> augmentation de la redondance ?! Les deux approches sont complémentaires. Les grandes approches du codage de canal seront vues au Chap. 2 (codes en bloc linéaires, codes cycliques ...). 1-8 Théorème du codage de canal
Considérons la classe des codes en blocs : la séquence originale à transmettre est segmentée en blocs de k e.b. chaque k-bloc se voit affecter en sortie du codeur de canal un n-bloc, avec n > k. r = k / n mesure le rendement du code. Problème : existe-t-il une stratégie de codage telle que la probabilité d’erreur soit inférieure à e donné, ... avec un rendement pas trop faible ? Réponse : OUI ! —> Second théorème de Shannon. 1-8 Théorème du codage de canal
Théorème (a) : Soit une source discrète sans mémoire, d’entropie H(A), produisant des symboles toutes les Ts secondes. Soit un canal discret sans mémoire de capacité C, utilisé toutes les Tc secondes. Alors, si , il existe une stratégie de codage pour laquelle la sortie de la source peut être transmise sur le canal et reconstruite avec une probabilité d’erreur arbitrairement petite. C / Tc est appelé débit critique. 1-8 Théorème du codage de canal
Théorème (b) : Si , alors il n’est pas possible de transmettre une information sur le canal et de la reconstruire avec une probabilité d’erreur arbitrairement faible. Remarques : La capacité d’un canal spécifie une limite fondamentale sur le débit maximum acceptable par un canal discret sans mémoire. Ce théorème n’indique en aucun cas la façon de construire la stratégie de codage. Il n’est qu’une preuve d’existence d’un code optimal. 1-8 Théorème du codage de canal
Application :Canal Binaire Symétrique Soit une source discrète sans mémoire émettant des symboles binaires (0/1) équiprobables toutes les Ts secondes. Le débit de la source vaut alors 1/Ts bits/seconde. L’entropie de la source vaut 1 bit/symbole. La séquence issue de la source est appliquée à un codeur de canal de rendement r. Le codeur de canal produit un symbole toutes les Tcsecondes. Le débit sur le canal est donc de 1/Tc symboles/seconde. C est la capacité du canal discret sans mémoire et dépend de la probabilité p de transition. La capacité du canal par unité de temps vaut donc C/Tc bits/seconde. 1-8 Théorème du codage de canal
Application :Canal Binaire Symétrique (Théorème a) => Si , on peut trouver un codage de canal donnant une probabilité d’erreur arbitrairement petite. Or , et finalement la condition précédente devient : 1-8 Théorème du codage de canal
Pour l’instant, nous avons traité le cas de v.a. discrètes ; On examine ici l’extension des principes précédents aux v.a. continues. Motivation : préparer le terrain pour le théorème de la capacité d’ information, qui définit une nouvelle limite fondamentale dans la théorie de l’information. 1-9 Extension aux signaux continus
Entropie différentielle Soit X une v.a. continue de fonction de densité de probabilité . L’entropie différentielle de X par la quantité : Remarques On utilise l’entropie différentielle car l’entropie absolue H(X) est infinie, mais également du fait que l’on manipule par la suite des différences d’entropie. Pour un vecteur aléatoire X = [X1X2 ... Xn ], on définit : 1-9 Extension aux signaux continus
Exemples Distribution uniforme ; Distribution gaussienne ; 1-9 Extension aux signaux continus
Information mutuelle Soient X et Y deux v.a. continues. Par analogie avec la définition dans le cas discret, on définit l’information mutuelle entre X et Y par : où est la fonction de densité de probabilité jointe de X et Y et est la densité conditionnelle de X sachant Y = y. 1-9 Extension aux signaux continus
Propriétés Symétrie Non-négativité où est appelée entropie différentielle conditionnelle de X sachant Y. 1-9 Extension aux signaux continus
On se place ici dans le cas de canaux de transmission : à bande limitée, à puissance limitée, à distribution gaussienne. On considère un processus aléatoire stationnaire à moyenne nulle et à spectre limité dans une bande B Hz ; Ce signal est échantillonné uniformément à la fréquence de Nyquist (2B échantillons / sec.) ; Ces échantillons sont transmis en T secondes sur un canal gaussien de moyenne nulle et de densité spectrale (bilatérale) , lui aussi limité à une bande B Hz. Le nombre d’échantillons est donc K = 2BT. 1-10 Théorème de la capacité d’information
On pose un échantillon du signal transmis, et l’échantillon reçu ; On a pour k = 1, 2, ... , K, avec On suppose que les sont indépendants. On suppose l’émetteur limité en puissance : où P est la puissance moyenne transmise. Remarque : Le canal gaussien limité en bande et en puissance n’est pas seulement un modèle théorique ; il est d’une grande importance dans beaucoup de structures de communication (liaisons radio, satellite ...). 1-10 Théorème de la capacité d’information
Définition La capacité d’information du canal est la quantité : Or Et est indépendant de Or Donc gaussiennes => gaussienne Et finalement 1-10 Théorème de la capacité d’information
Evaluation de C variance de : entropie différentielle : variance de : entropie différentielle : Et finalement bits par transmission, 1-10 Théorème de la capacité d’information
Théorème de la capacité d’information (3ème théorème de Shannon) La capacité d’information d’un canal continu de bande passante B Hz perturbé par un bruit blanc gaussien additif de densité spectrale de puissance et également limité à la bande passante B, est donnée par : où P est la puissance moyenne de transmission. 1-10 Théorème de la capacité d’information
Conséquences Pour P, B, et N0 fixés, on peut transmettre une information avec un débit de C bits par seconde avec une probabilité d’erreur arbitrairement petite, en employant un système de codage suffisamment complexe. Il n’est pas possible de transmettre à un débit supérieur à C bits par seconde sans entraîner une probabilité d’erreur définie. Le théorème de la capacité d’information définit donc une autre limite fondamentale sur le débit d’une transmission sans erreur. Pour approcher cette limite, toutefois, le signal transmis doit avoir des propriétés statistiques approchant celles du bruit gaussien. 1-10 Théorème de la capacité d’information
Implications du théorème Pour avoir une idée des performances d’un système de communication, il faut définir une base de comparaison sous la forme d’un système idéal : Transmission de débit R = C ; P = Eb.C , où Eb est l’énergie transmise par e.b. Le système idéal est défini par la relation De manière équivalente C/B efficacité en bande 1-10 Théorème de la capacité d’information