Download

1 / 31
310 likes | 453 Views
Chapter 4 Review: More About the Relationships between Two Variables. By: Ethan Jen, Ian Green, Stephen Lee, and Zack Flagel. Focuses. Transforming to achieve linearity Relationship between Categorical Variables Establishment and Causation. When W e U se This.

E N D
Chapter 4 Review: More About the Relationships between Two Variables By: Ethan Jen, Ian Green, Stephen Lee, and Zack Flagel
Focuses • Transforming to achieve linearity • Relationship between Categorical Variables • Establishment and Causation
When We Use This • We use this when we are trying to find a function that best fits the data (linear, exponential, ex…) • We use two tables to get an overview of the data and discover relationshipsand to find conditional distributions • In reality, we use Simpson’s paradox in some cases to explain skewed data and discrepancies • We closely examine the data to distinguish causation and correlation
Key Vocabulary Words • Transforming data • Applying a function such as the logarithm or square root to a quantitative variable to better fit the data • Linear growth • A fixed increment is added to the variable in each equal time period • Exponential growth model • An increase by a fixed percent of the total in each equal time period • Becomes linear when log y is plotted against x • Power model • Linear when we plot log y against log x
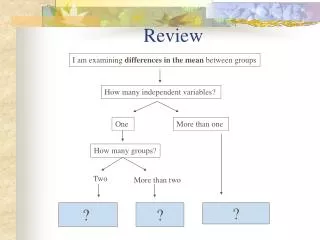
Key Vocabulary Words (continued) • Two way Table • Organizes data about two categorical variables • Has row variable and column variable • Margin of Distribution • Appear at bottom and right margins of two-way table • Tells us nothing about the relationship between variables • Conditional distribution • Comparing percentages • Reveals associations • Simpson’s Paradox • Association or comparison that holds for all of several groups can reverse direction when the fata are combined to form a single group • Can find the effect of lurking variables
Key Vocabulary Words (continued) • Common Response • One variable causes another variable • Confounding • Two variables are confounded when their effects on response variable cannot be distinguished from each other. These variables can be explanatory variable or lurking variables • Causation • cause and effect relationship • One cannot assume causation because of lurking variables
Key Topics • Transforming to Achieve Linearity • Nonlinear relationships between two quantitative variables can sometimes be changed into linear relationships by transforming one or both of the variables • The most common transformations belong to the family of power functions • Exponential model becomes linear when we plot log y against x • Power law model becomes linear when we plot log y against log x
Key Topics (continued) • Exponential to Linear y =abx log y = log(abx) = log a + log bx = log a + (log b)x
Key Topics (continued) • Power model to linear y = axp log y = log a + log xp log y = log a + plogx
Key Topics (continued) • Relationships between Categorical Variables • a two-way table of counts organizes data about two categorical • Row variables run across the table while column variables run down the table • The row totals and the column totals give the marginal distribution of the individual variables • To find conditional distribution of a specific row variable, look only at that one column in the table and find the percentage. • Comparing the conditional distributions is one way to describe association between the row and the column variables.
Key Topics (continued) • Bar graphs are a flexible means of presenting categorical data • A comparison between two variables that hold for each individual value of a third variable can be reversed when the data for all values of the third variable are combined is called the Simpson’s paradox • Simpson’s paradox is an example of the effect of lurking variables on an observed association (pg 300)
Key Topics (continued) • Don’t assume causation unless there are many experiments with the lurking variables controlled. One exception • Three types of association: Causation, common response, confounding
Key Topics (continued) • To determine causation without an experiment: • Strong association • Consistent association • Larger values of response variables are associated with stronger responses • Alleged cause precedes the effect in time • Alleged cause is plausible
Formulas • Linear: • Exponential: • Power: b
Formulas (continued) • When linearizing data: • Exponential: 𝑙𝑜𝑔𝑦 = 𝑎 + 𝑏𝑥 • Power: 𝑙𝑜𝑔𝑦 = 𝑎 + 𝑏𝑙𝑜𝑔𝑥
Calculator Key Strokes • Turn Stat plot and stat diagnostics on • Stat plot is 2ND Y= and stat diagnostics is under mode • To transform data from linear to exponential, use the x value log(x) and y-hat • Go to the list functions under Stat->Edit and change the lists to log(values) • To transform data to power regression model, change the x value to log(x) and log(y)
Calculator Key Strokes (continued) • Graphing • Turn Stat plot on • For residuals and the regression models, select the first graph among the choices • Make the X-list and Y-list the appropriate lists. This is also under stat plot
Practice Question A study covering many countries found a strong positive correlation between the life expectancy in a country and the percentage of households in the country with telephones. The best explanation of this observed correlation is that A. both life expectancy and telephone ownership are exhibiting a common response to the lurking variable of the country’s socioeconomic condition.B. telephone ownership and use is a major contributing cause of longer life.C. in countries where life expectancy is high, the rate of telephone ownership tends to be low, and in countries where life expectancy is low, the rate of telephone ownership tends to be high.
Helpful hints • Data Transformation/Linear Regression • Remember to keep Stat Plot and diagnostics on • Set the L1 and L2 to the appropriate settings • Evaluate r and r2 to help determine the correlation • Check the residual plot. A random residual plot with values relatively close to 0 is a good fit for the data • Define the variables x and y when writing an equation
Helpful Hints (continued) • Facts about “powers” • Graph of a linear function (power 1) is a line • Powers above 1 bend the graph upward with the steepness increasing as the power increases • Powers between 0 and 1 give graphs that bend downward • Powers less that 0 make the y-value decrease as x increases
Helpful Hints (continued) • Two-Way Tables • Don’t repeat when adding the marginal distributions for the total value • Correlation/Causation • CORRELATION DOES NOT MEAN CAUSATION • Look out for confounding variables or common response variables • Also look out for lurking variables
Worksheet Answers (1) • C. • States with high concentrations of industry, such as Rhode Island and New York, have environmental problems that contribute to the development of cancer that more rural states, such as South Carolina, Alabama, and Arkansas, do not possess. Any of these additional factors could be contributing to the higher death rates in the industrialized states, and it would be a mistake to attribute the higher death rates solely to beer consumption.
Worksheet Answers (2) • B. • There is a total of 33 + 40 + 23 + 20 = 116 individuals who describe themselves as moderates, and 315 students in all. The desired percentage is 116/315 = 0.368 or 36.8%. This is the marginal distribution of viewpoint for moderates.
Worksheet Answers (3) • A. • We desire the cell percentage for the cell “conservative and moderate.” There are 38 individuals in this cell, so the correct percentage is 38/315 = 0.121, or 12.1%.
Worksheet Answers (4) • B. • We want to find the conditional distribution of the major field category “humanities” among students describing themselves as liberals. There are 17 + 12 + 32 + 30 = 91 liberals, of whom 32 are humanities majors. The correct result is therefore 32/91 = 0.352 or 35.2%.
Worksheet Answers (5) • B. • The exponential model is y = 98.25(.91885)x, where x is measured in days. Converting 2 weeks to x = 14 days and substituting, we get y = 98.25(.91885)14 = 30.04 grams or approximately 30 grams.
Worksheet Answers (6) • C. • Transforming the data to obtain a power function model yields the model y= (0.29964)x?2.01616. Evaluating this function at x = 4 yields y = (0.29964)(4)?2.01616 = 0.018.