Download
1 / 1
10 likes | 105 Views
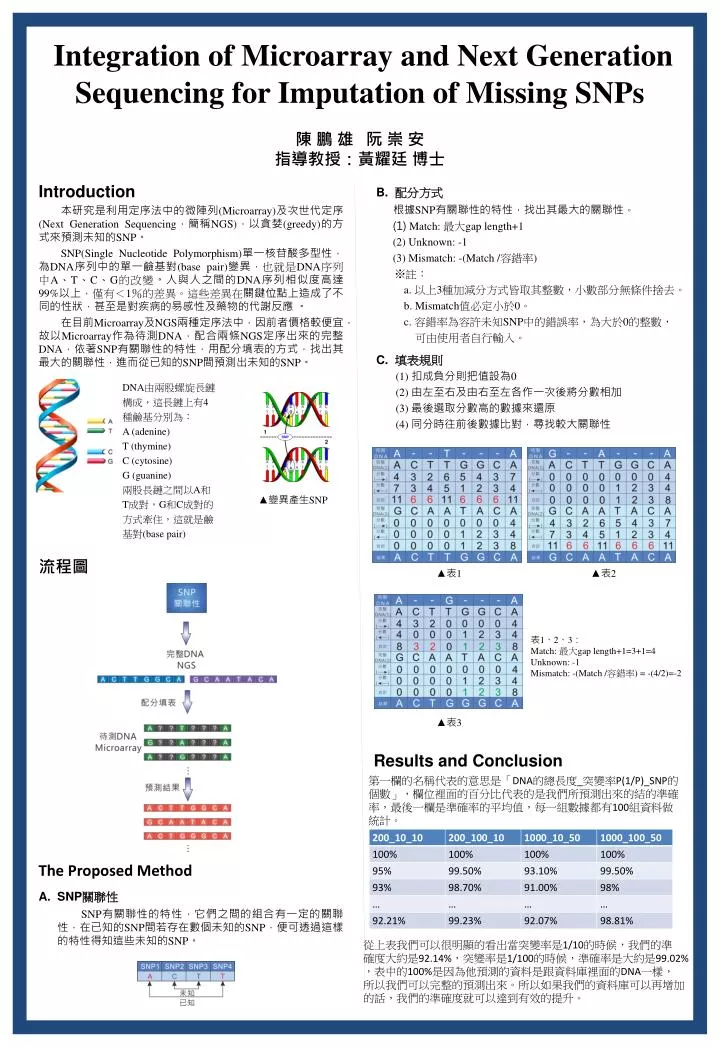
Integration of Microarray and Next Generation Sequencing for Imputation of Missing SNPs. 陳 鵬 雄 阮 崇 安 指導 教授 :黃耀廷 博士. Introduction 本 研究 是利用定序法中的微陣列 (Microarray) 及次世代定序 (Next Generation Sequencing ,簡稱 NGS) ,以貪婪 (greedy) 的方式來預測未知的 SNP 。

E N D
Integration of Microarray and Next Generation Sequencing for Imputation of Missing SNPs 陳 鵬 雄 阮 崇 安 指導教授:黃耀廷 博士 Introduction 本研究是利用定序法中的微陣列(Microarray)及次世代定序(Next Generation Sequencing,簡稱NGS),以貪婪(greedy)的方式來預測未知的SNP。 SNP(Single Nucleotide Polymorphism)單一核苷酸多型性,為DNA序列中的單一鹼基對(base pair)變異,也就是DNA序列中A、T、C、G的改變。人與人之間的DNA序列相似度高達99%以上,僅有<1%的差異。這些差異在關鍵位點上造成了不同的性狀,甚至是對疾病的易感性及藥物的代謝反應 。 在目前Microarray及NGS兩種定序法中,因前者價格較便宜,故以Microarray作為待測DNA,配合兩條NGS定序出來的完整DNA,依著SNP有關聯性的特性,用配分填表的方式,找出其最大的關聯性,進而從已知的SNP間預測出未知的SNP。 • 配分方式 • 根據SNP有關聯性的特性,找出其最大的關聯性。 • (1)Match: 最大gap length+1 • (2)Unknown: -1 • (3)Mismatch: -(Match /容錯率) • ※註: • a. 以上3種加減分方式皆取其整數,小數部分無條件捨去。 • b. Mismatch值必定小於0。 • c. 容錯率為容許未知SNP中的錯誤率,為大於0的整數, • 可由使用者自行輸入。 • 填表規則 • (1)扣成負分則把值設為0 • (2) 由左至右及由右至左各作一次後將分數相加 • (3) 最後選取分數高的數據來還原 • (4) 同分時往前後數據比對,尋找較大關聯性 • DNA由兩股螺旋長鏈 • 構成,這長鏈上有4 • 種鹼基分別為: • A(adenine) • T(thymine) • C(cytosine) • G(guanine) • 兩股長鏈之間以A和 • T成對,G和C成對的 • 方式牽住,這就是鹼 • 基對(base pair) ▲變異產生SNP 流程圖 ▲表1 ▲表2 • 表1、2、3: • Match: 最大gap length+1=3+1=4 • Unknown: -1 • Mismatch: -(Match /容錯率) = -(4/2)=-2 ▲表3 Results and Conclusion 第一欄的名稱代表的意思是「DNA的總長度_突變率P(1/P)_SNP的 個數」,欄位裡面的百分比代表的是我們所預測出來的結的準確 率,最後一欄是準確率的平均值,每一組數據都有100組資料做 統計。 The Proposed Method SNP關聯性 SNP有關聯性的特性,它們之間的組合有一定的關聯性,在已知的SNP間若存在數個未知的SNP,便可透過這樣的特性得知這些未知的SNP。 從上表我們可以很明顯的看出當突變率是1/10的時候,我們的準 確度大約是92.14%,突變率是1/100的時候,準確率是大約是99.02% ,表中的100%是因為他預測的資料是跟資料庫裡面的DNA一樣, 所以我們可以完整的預測出來。所以如果我們的資料庫可以再增加 的話,我們的準確度就可以達到有效的提升。