Download
1 / 22
220 likes | 357 Views
10GbE WAN Data Transfers for Science High Energy/Nuclear Physics (HENP) SIG Fall 2004 Internet2 Member Meeting. Yang Xia, HEP, Caltech yxia@caltech.edu September 28, 2004 8:00 AM – 10:00 AM. Agenda. Introduction 10GE NIC comparisons & contrasts Overview of LHCnet

E N D
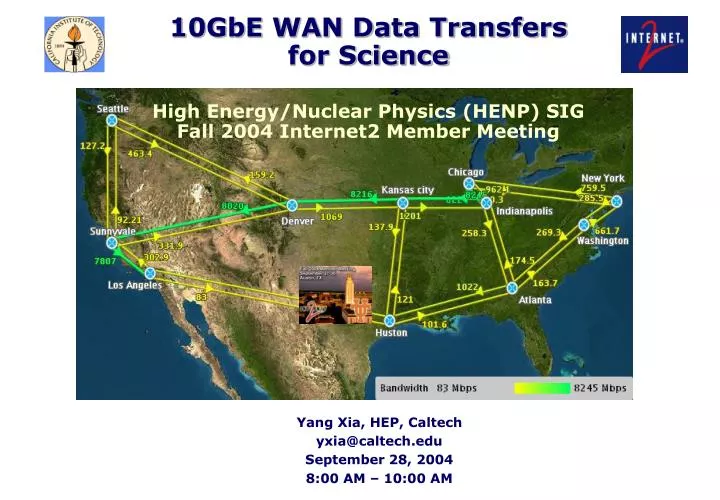
10GbE WAN Data Transfers for ScienceHigh Energy/Nuclear Physics (HENP) SIGFall 2004 Internet2 Member Meeting Yang Xia, HEP, Caltech yxia@caltech.edu September 28, 2004 8:00 AM – 10:00 AM
Agenda • Introduction • 10GE NIC comparisons & contrasts • Overview of LHCnet • High TCP performance over wide area networks • Problem statement • Benchmarks • Network architecture and tuning • Networking enhancements in Linux 2.6 kernels • Light paths : UltraLight • FAST TCP protocol development
Introduction • High Engery Physics LHC model shows data at the experiment will be stored at the rate of 100 – 1500 Mbytes/sec throughout the year. • Many Petabytes per year of stored and processed binary data will be accessed and processed repeatedly by the worldwide collaborations. • Network backbone capacities advancing rapidly to 10 Gbps range and seamless integration into SONETs. • Proliferating GbE adapters on commodity desktops generates bottleneck on GbE Switch I/O ports. • More commercial 10GbE adapter products entering the market, e.g. Intel, S2io, IBM, Chelsio etc.
10GbE NICs Comparison (Intel vs S2io) • Standard Support: • 802.3ae Standard, full duplex only • 64bit/133MHz PCI-X bus • 1310nm SMF/850nm MMF • Jumbo Frame Support Major Difference in Performance Features:
LHCnet Network Setup • 10 Gbps transatlantic link extended to Caltech via Abilene and CENIC. NLR wave local loop is in working progress. • High-performance end stations (Intel Xeon & Itanium, AMD Opteron) running both Linux and Windows • We have added a 64x64 Non-SONET all optical switch from Calient to provision a dynamic path via MonALISA, in the context of UltraLight.
Glimmerglass StarLight CERN LHCnet Topology: August 2004 • Services: • IPv4 & IPv6 ; Layer2 VPN ; QoS ; scavenger ; large MTU (9k) ; MPLS ; links aggregation ; monitoring (Monalisa) • Clean separation of production and R&D traffic based on CCC. • Unique Multi-platform / Multi-technology optical transatlantic test-bed • Powerful Linux farms equipped with 10 GE adapters (Intel; S2io) • Equipment loan and donation; exceptional discount • NEW: Photonic switch (Glimmerglass T300) evaluation • Circuit (“pure” light path) provisioning Alcatel 7770 Procket 8801 Alcatel 7770 Procket 8801 Cisco 7609 Juniper M10 Cisco 7609 Juniper M10 Linux Farm 20 P4 CPU 6 TBytes Linux Farm 20 P4 CPU 6 TBytes 10GE 10GE 10GE LHCnet tesbed LHCnet tesbed Juniper T320 Juniper T320 10GE American Partners 10GE EuropeanPartners InternalNetwork Caltech/DoE PoP - Chicago OC192 (Production and R&D) CERN - Geneva
GMPLS controlled PXCs and IP/MPLS routers can provide dynamic shortest path set-up and path setup based on priority of links. LHCnet Topology: August 2004 (cont’d) Optical Switch Matrix Calient Photonic Cross Connect Switch
Problem Statement • To get the most bangs for the buck on 10GbE WAN, packet loss is the #1 enemy. This is because of slow TCP responsive from AIMD algorithm: • No Loss: cwnd := cwnd + 1/cwnd • Loss: cwnd := cwnd/2 • Fairness: TCP Reno MTU & RTT bias • Different MTUs and delays lead to a very poor sharing of the bandwidth.
Internet 2 Land Speed Record (LSR) • IPv6 record: 4.0 Gbps between Geneva and Phoenix (SC2003) • IPv4 Multi-stream record with Windows: 7.09 Gbps between Caltech and CERN (11k km) • Single Stream 6.6 Gbps X 16.5 k km with Linux • We have exceeded 100 Petabit-m/sec with both Linux & Windows • Testing on different WAN distances doesn’t seem to change TCP rate: • 7k km (Geneva - Chicago) • 11k km (Normal Abilene Path) • 12.5k km (Petit Abilene's Tour) • 16.5k km (Grande Abilene's Tour) Monitoring of the Abilene Traffic in LA:
Internet 2 Land Speed Record (cont’d) Single Stream IPv4 Category
Primary Workstation Summary • Sending Station: • Newisys 4300, 4 x AMD Opteron 248 2.2GHz, 4GB PC3200/Processor. Up to 5 x 1GB/s 133MHz/64bit PCI-X slots. No FSB bottleneck. HyperTransport connects CPUs (up to 19.2GB/s peak BW per processor), 24 SATA disks RAID system @ 1.2GB/s read/write • Opteron white box with Tyan S2882 motherboard, 2x Opteron 2.4 GHz , 2 GB DDR. • AMD8131 chipset PCI-X bus speed: ~940MB/s • Receiving Station: • HP rx4640, 4x 1.5GHz Itanium-2, zx1 chipset, 8GB memory. • SATA disk RAID system
Linux Tuning Parameters • PCI-X Bus Parameters: (via setpci command) • Maximum Memory Read Byte Count (MMRBC) controls PCI-X transmit burst lengths on the bus: Available values are 512Byte (default), 1024KB, 2048KB and 4096KB • “max_split_trans” controls outstanding splits. Available values are: 1, 2, 3, 4 • latency_timer to 248 • Interrupt Coalescence: • It allows a user to change the CPU-affinity of the interrupts in a system. • Large window size = BW*Delay (BDP) • Too large window size will negatively impact throughput. • 9000byte MTU and 64KB TSO
Linux Tuning Parameters (cont’d) • Use sysctl command to modify /proc parameters to increase TCP memory values.
10GbE Network Testing Tools • In Linux: • Iperf: • Version 1.7.0 doesn’t work by default on the Itanium2 machine. Workarounds: 1) Compile using RedHat’s gcc 2.96 or 2) make it single threaded • UDP send rate limits to 2Gbps because of 32-bit date type • Nttcp: Measures the time required to send preset chunk of data. • Netperf (v2.1): Sends as much data as it can in an interval and collects result at the end of test. Great for end-to-end latency test. • Tcpdump: Challenging task for 10GbE link • In Windows: • NTttcp: Using Windows APIs • Microsoft Network Monitoring Tool • Ethereal
Networking Enhancements in Linux 2.6 • 2.6.x Linux kernel has made many improvements in general to improve system performance, scalability and hardware drivers. • Improved Posix Threading Support (NGPT and NPTL) • Supporting AMD 64-bit (x86-64) and improved NUMA support. • TCP Segmentation Offload (TSO) • Network Interrupt Mitigation:Improved handling of high network loads • Zero-Copy Networking and NFS: One system call with: sendfile(sd, fd, &offset, nbytes) • NFS Version 4
TCP Segmentation Offload • Must have hardware support in NIC. • It’s a sender only option. It allows TCP layer to send a larger than normal segment of data, e,g, 64KB, to the driver and then the NIC. The NIC then fragments the large packet intosmaller (<=mtu) packets. • TSO is disabled in multiple places in the TCP functions. It is disabled when sacks are received, in tcp_sacktag_write_queue, and when a packet is retransmitted, in tcp_retransmit_skb. However, TSO is never re-enabled in the current 2.6.8 kernel when TCP state changes back to normal (TCP_CA_Open). Need to patch the kernel to re-enable TSO. • Benefits: • TSO can reduce CPU overhead by 10%~15%. • Increase TCP responsiveness. • p=(C*RTT*RTT)/(2*MSS) • p: Time to recover to full rate • C: Capacity of the link • RTT: Round Trip Time • MSS: Maximum Segment Size
The Transfer over 10GbE WAN • With 9000byte MTU and stock Linux 2.6.7 kernel: • LAN: 7.5Gb/s • WAN: 7.4Gb/s (Receiver is CPU bound) • We’ve reached the PCI-X bus limit with single NIC. Using bonding (802.3ad) of multiple interfaces we could bypass the PCI X bus limitation in mulple streams case only • LAN: 11.1Gb/s • WAN: ??? • (a.k.a. doom’s day for Abilene)
UltraLight: Developing Advanced Network Services for Data Intensive HEP Applications • UltraLight(funded by NSF ITR): a next-generation hybrid packet- and circuit-switched network infrastructure. • Packet switched: cost effective solution; requires ultrascale protocols to share 10G efficiently and fairly • Circuit-switched: Scheduled or sudden “overflow” demands handled by provisioning additional wavelengths; Use path diversity, e.g. across the US, Atlantic, Canada,… • Extend and augment existing grid computing infrastructures (currently focused on CPU/storage) to include the network as an integral component • Using MonALISA to monitor and manage global systems • Partners: Caltech, UF, FIU, UMich, SLAC, FNAL, MIT/Haystack; CERN, Internet2, NLR, CENIC; Translight, UKLight, Netherlight; UvA, UCL, KEK, Taiwan • Strong support from Cisco and Level(3)
“Ultrascale” protocol development: FASTTCP • FAST TCP • Based on TCP Vegas • Uses end-to-end delay and loss to dynamically adjust the congestion window • Achieves any desired fairness, expressed by utility function • Very high utilization (99% in theory) • Compare to Other TCP Variants: e.g. BIC, Westwood+ Capacity = OC-192 9.5Gbps; 264 ms round trip latency; 1 flow BW use 50% BW use 79% BW use 30% BW use 40% Linux TCP Linux Westwood+ Linux BIC TCP FAST
Summary and Future Approaches • Full TCP offload engine will be available for 10GbE in the near future. There is a trade-off between maximizing CPU utilization and ensuring data integrity. • Develop and provide cost-effective transatlantic network infrastructure and services required to meet the HEP community's needs • a highly reliable and performance production network, with rapidly increasing capacity and a diverse workload. • an advanced research backbone for network and Grid developments: including operations and management assisted by agent-based software (MonALISA) • Concentrate on reliable Terabyte-scale file transfers, to drive development of an effective Grid-based Computing Model for LHC data analysis.