Download
1 / 10
120 likes | 311 Views
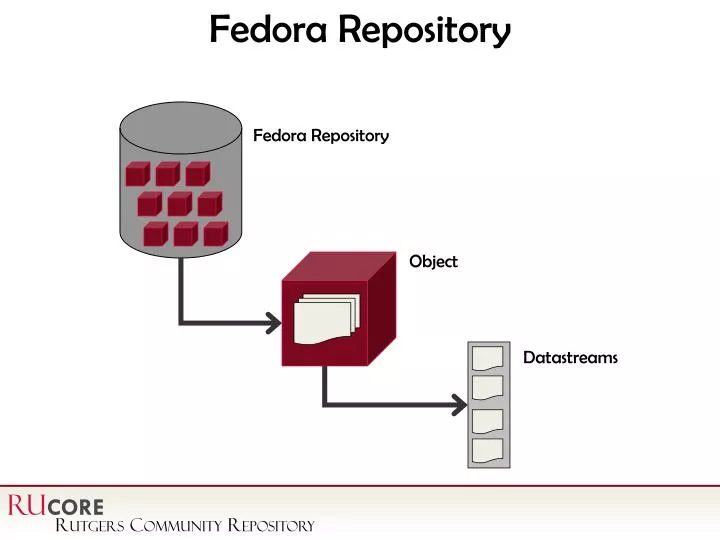
Fedora Repository. Object. Datastreams. Fedora Repository. Pre-indexing Program. Fedora Database. Search Database. The pre-indexing program populates the Search database with sorting and path information from the Fedora database as well as collection information from the Objects.

E N D
Fedora Repository Object Datastreams Fedora Repository
Pre-indexing Program Fedora Database Search Database The pre-indexing program populates the Search database with sorting and path information from the Fedora database as well as collection information from the Objects. Fedora Objects
Search Database Create Indexes The indexing program uses the search database to find Objects for particular collections and then combines Descriptive metadata with XML full text datastreams to Create “search objects” for indexing with Amberfish. Search Objects Filter Atomic Amberfish Indexes
Amberfish® • Amberfish is text retrieval software distributed as open source software under the terms of version 2 of the GNU General Public License (GPL). • Automatic searching across multiple databases (allowing modular indexing). We refer to this as atomic indexes. • Indexing/search of semi-structured text (i.e. both free text and multiply nested fields) • Boolean queries, right truncation, phrase searching, relevance ranking, support for multiple documents per file, incremental indexing. • Read more - http://www.etymon.com/tr.html
Search Results Search Database Searching… User Search Interface [Coll1][Coll2][Coll3] Ambersearch.php + + Coll1 Index Coll2 Index Coll3 Index Sort Results
Collection Hierarchy A MySQL database is used to create and display parent/child collection relationships. The database is a compact straightforward relational model. Functions were written to build collection hierarchies in the search interface and create structure maps of the collection when needed. Collection Hierarchy Search Interface A start point (collection id) along with the max depth are defined in a function call. The collection tree is then built in the search interface. Structure Map (SMAP) Generation When a collection objects structure/hierarchy is changed a structure map(XML) can be generated and stored in the collection object in the repository. In the event a collections hierarchy needs to be rebuilt we have preserved the collections lineage in the repository. To create the SMAP a start point (collection id) need only be defined. A function then probes the database to determine the collections maximum depth. Once this is discovered an appropriate SMAP is generated and appended to the object.
Partner Portals • Background • Provide the capability to allow partners, other institutions and individuals to attach the repository search engine with selected collections to their website • Built off existing search code used on NJDH and RUcore sites. • An extension offered to NJDH partners and RUcore participants. • Minimal systems requirements. • Simple setup and maintenance for partners, assumed they are not technically orientated. • Ability to customize their collection list, subscribe. • How it works… • Username/password and a unique key are generated and assigned. • Partner has access to subscribing to collections of their choice. • Partner embeds a URI, IFrame, on their web site that allows for access.
Partner Portal URL’s Northwestern University http://lefty.scc-net.rutgers.edu/portals/nwu/ Penn State University http://lefty.scc-net.rutgers.edu/portals/psu/ Princeton University http://lefty.scc-net.rutgers.edu/portals/princeton/
Electronic Theses & Dissertations Example of a project using all the capabilities outlined. ETD is a product developed at RUL and is based off of the open source Open Journal System. Theses & Dissertations are uploaded and minimal amounts of metadata are supplied by the student. Our graduate school uses the ETD application to track and approve theses & dissertations. Once a theses or dissertations is approved and all levels of sign off are completed the metadata and document are packaged up and delivered to the WMS for further cataloging. This is done using the XML import functionality built into the WMS. The paper is then ingested into the repository and is searchable from RUcore. The graduate school has the ability to create a portal on their website to access these papers as well. Additional exporting takes place from the repository to our library catalog and to UMI ProQuest.
Contact Chad: cmmills@rci.rutgers.edu Jeffery: triggs@rutgers.edu




















