Download
1 / 1
20 likes | 187 Views
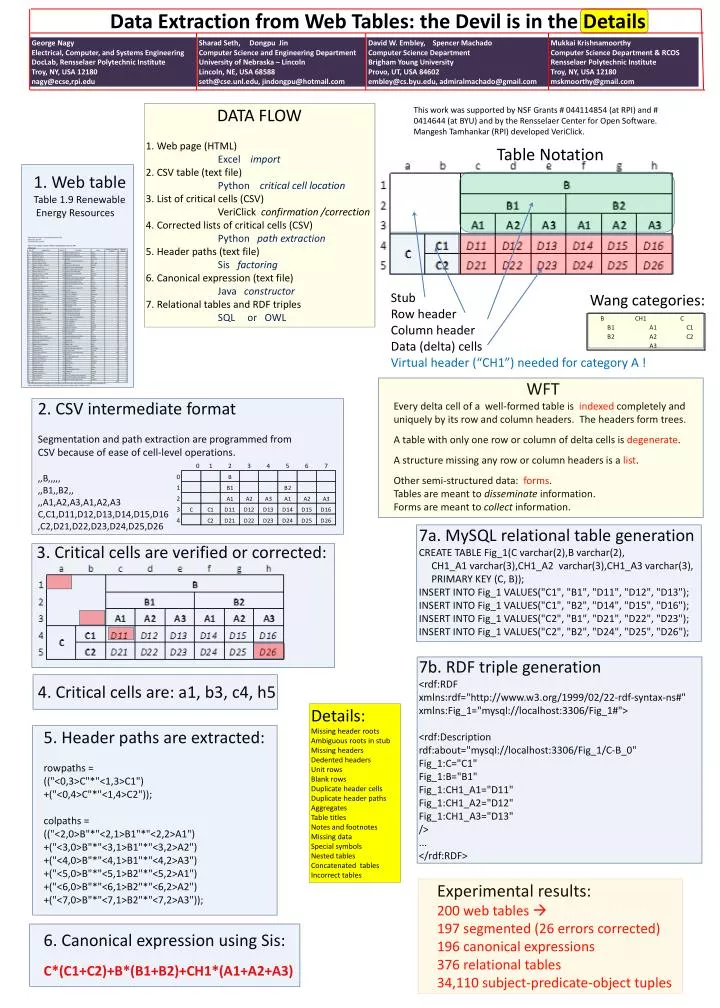
DATA FLOW 1. Web page (HTML) Excel import 2. CSV table (text file) Python critical cell location 3. List of critical cells (CSV) VeriClick confirmation /correction 4. Corrected lists of critical cells (CSV ) Python path extraction

E N D
DATA FLOW 1. Web page (HTML) Excel import 2. CSV table (text file) Python critical cell location 3. List of critical cells (CSV) VeriClick confirmation /correction 4. Corrected lists of critical cells (CSV) Python path extraction 5. Header paths (text file) Sisfactoring 6. Canonical expression (text file) Java constructor 7. Relational tables and RDF triples SQL or OWL This work was supported by NSF Grants # 044114854 (at RPI) and # 0414644 (at BYU) and by the Rensselaer Center for Open Software. MangeshTamhankar (RPI) developed VeriClick. Table Notation 1. Web table Table 1.9 Renewable Energy Resources Stub Row header Column header Data (delta) cells Virtual header (“CH1”) needed for category A ! Wang categories: Data Extraction from Web Tables: the Devil is in the Details WFT Every delta cell of a well-formed table is indexed completely and uniquelyby its row and column headers. The headers form trees. A table with only one row or column of delta cells is degenerate. A structure missing any row or column headers is a list. Other semi-structured data: forms. Tables are meant to disseminate information. Forms are meant to collect information. 2. CSV intermediate format Segmentation and path extraction are programmed from CSV because of ease of cell-level operations. ,,B,,,,, ,,B1,,B2,, ,,A1,A2,A3,A1,A2,A3 C,C1,D11,D12,D13,D14,D15,D16 ,C2,D21,D22,D23,D24,D25,D26 • 7a. MySQL relational table generation • CREATE TABLE Fig_1(C varchar(2),B varchar(2), • CH1_A1 varchar(3),CH1_A2 varchar(3),CH1_A3 varchar(3), • PRIMARY KEY (C, B)); • INSERT INTO Fig_1 VALUES("C1", "B1", "D11", "D12", "D13"); • INSERT INTO Fig_1 VALUES("C1", "B2", "D14", "D15", "D16"); • INSERT INTO Fig_1 VALUES("C2", "B1", "D21", "D22", "D23"); • INSERT INTO Fig_1 VALUES("C2", "B2", "D24", "D25", "D26"); 3. Critical cells are verified or corrected: • 7b. RDF triple generation • <rdf:RDF • xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" • xmlns:Fig_1="mysql://localhost:3306/Fig_1#"> • <rdf:Description • rdf:about="mysql://localhost:3306/Fig_1/C-B_0" • Fig_1:C="C1" • Fig_1:B="B1" • Fig_1:CH1_A1="D11" • Fig_1:CH1_A2="D12" • Fig_1:CH1_A3="D13" • /> • ... • </rdf:RDF> 4. Critical cells are: a1, b3, c4, h5 Details:Missing header roots Ambiguous roots in stub Missing headers Dedented headers Unit rows Blank rows Duplicate header cells Duplicate header paths Aggregates Table titles Notes and footnotes Missing data Special symbols Nested tables Concatenated tables Incorrect tables 5. Header paths are extracted: rowpaths= (("<0,3>C"*"<1,3>C1") +("<0,4>C"*"<1,4>C2")); colpaths = (("<2,0>B"*"<2,1>B1"*"<2,2>A1") +("<3,0>B"*"<3,1>B1"*"<3,2>A2") +("<4,0>B"*"<4,1>B1"*"<4,2>A3") +("<5,0>B"*"<5,1>B2"*"<5,2>A1") +("<6,0>B"*"<6,1>B2"*"<6,2>A2") +("<7,0>B"*"<7,1>B2"*"<7,2>A3")); 6. Canonical expression using Sis: C*(C1+C2)+B*(B1+B2)+CH1*(A1+A2+A3) Experimental results: 200 web tables 197 segmented (26 errors corrected) 196 canonical expressions 376 relational tables 34,110 subject-predicate-object tuples





















