Download
1 / 1
10 likes | 96 Views
h0. h1. h2. h3. x0. x1. x2. x3. x4. x5. x6. x7. h0. h0. h1. h2. h3. h1. h2. h3. X 1. X 1. X 1. X 2. X 2. X 2. X 3. X 3. X 3. H. x0. x1. x2. x3. x4. x5. x6. x7. x0. x1. x2. x3. x4. x5. x6. x7. H. Y 1. Y 1. Y 1. Y 2. Y 2. Y 2. Y 3. Y 3. Y 3. H.

E N D
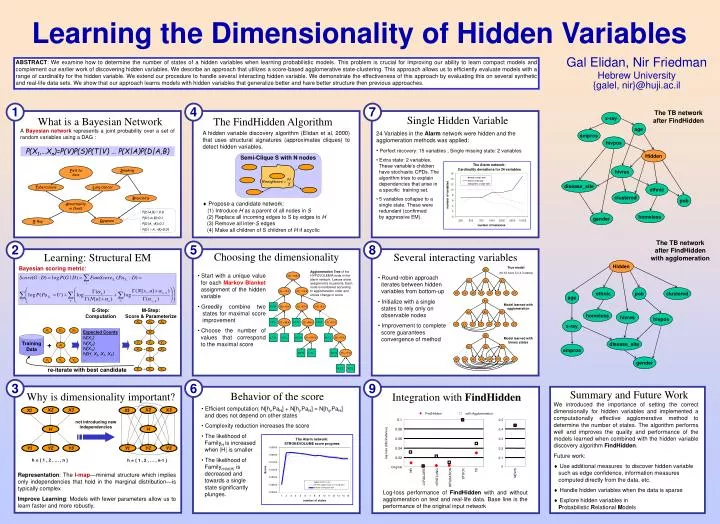
h0 h1 h2 h3 x0 x1 x2 x3 x4 x5 x6 x7 h0 h0 h1 h2 h3 h1 h2 h3 X1 X1 X1 X2 X2 X2 X3 X3 X3 H x0 x1 x2 x3 x4 x5 x6 x7 x0 x1 x2 x3 x4 x5 x6 x7 H Y1 Y1 Y1 Y2 Y2 Y2 Y3 Y3 Y3 H Visit to Asia Smoking Tuberculosis Lung Cancer Bronchitis Abnormality in Chest Dyspnea X-Ray (12) –185.5 Semi-Clique S with N nodes (9) +10.0 (11) –19.6 H,F,H (8) +10.6 (4) +23.4 (10) +5.0 L,F,L L,F,N L,F,H (3) +38.4 (2) +46.4 (7) +12.3 L,T,N H,F,L H,F,N (1) +610.6 H,T,L (6) +15.6 N,F,N L,T,L N,F,H (5) +17.5 N,F,L N,T,L X2 X3 X1 H Y1 Y2 Y3 Learning the Dimensionality of Hidden Variables ABSTRACT: We examine how to determine the number of states of a hidden variables when learning probabilistic models. This problem is crucial for improving our ability to learn compact models and complement our earlier work of discovering hidden variables. We describe an approach that utilizes a score-based agglomerative state-clustering. This approach allows us to efficiently evaluate models with a range of cardinality for the hidden variable. We extend our procedure to handle several interacting hidden variable. We demonstrate the effectiveness of this approach by evaluating this on several synthetic and real-life data sets. We show that our approach learns models with hidden variables that generalize better and have better structure then previous approaches. Gal Elidan, Nir Friedman Hebrew University {galel, nir}@huji.ac.il 7 1 4 The TB network after FindHidden x-ray What is a Bayesian Network Single Hidden Variable The FindHidden Algorithm age A Bayesian network represents a joint probability over a set of random variables using a DAG : A hidden variable discovery algorithm (Elidan et al, 2000) that uses structural signatures (approximates cliques) to detect hidden variables. • 24 Variables in the Alarm network were hidden and the agglomeration methods was applied: • Perfect recovery: 15 variables ; Single missing state: 2 variables • Extra state: 2 variables. These variable’s children have stochastic CPDs. The algorithm tries to explain dependencies that arise in a specific training set. • 5 variables collapse to a single state. These were redundant (confirmed by aggressive EM). smpros hivpos P(X1,…Xn)=P(V)P(S)P(T|V) … P(X|A)P(D|A,B) Hidden hivres disease_site ethnic clustered pob • Propose a candidate network: (1) Introduce H as a parent of all nodes in S (2) Replace all incoming edges to S by edges to H (3) Remove all inter-S edges (4) Make all children of S children of H if acyclic P(D|A,B) = 0.8 P(D|¬A,B)=0.1 P(D|A, ¬B)=0.1 P(D| ¬ A, ¬B)=0.01 homeless gender The TB network after FindHidden with agglomeration 2 5 8 Choosing the dimensionality Several interacting variables Learning: Structural EM Hidden Bayesian scoring metric: True model (h0-h3 have 3,2,4,3 states) Agglomeration Tree of the HYPOVOLEMIA node in the alarm network. Leaves show assignments to parents. Each node is numbered according to agglomeration order and shows change in score • Start with a unique value for each Markov Blanketassignment of the hidden variable • Greedily combine two states for maximal score improvement • Choose the number of values that correspond to the maximal score • Round-robin approach iterates between hidden variables from bottom-up • Initialize with a single states to rely only on observable nodes • Improvement to complete score guarantees convergence of method ethnic pob clustered age Model learned with agglomeration E-Step: Computation M-Step: Score & Parameterize homeless hivres hivpos x-ray Expected Counts N(X1) N(X2) N(X3) N(H, X1, X1, X3) ... Training Data Model learned with binary states disease_site + smpros gender re-iterate with best candidate 3 6 9 Summary and Future Work Behavior of the score Why is dimensionality important? Integration with FindHidden We introduced the importance of setting the correct dimensionally for hidden variables and implemented a computationally effective agglomerative method to determine the number of states. The algorithm performs well and improves the quality and performance of the models learned when combined with the hidden variable discovery algorithm FindHidden. Future work: • Use additional measures to discover hidden variable such as edge confidence, information measures computed directly from the data, etc. • Handle hidden variables when the data is sparse • Explore hidden variables in Probabilistic Relational Models • Efficient computation: N[hi,PaH] + N[hj,PaH] = N[hij,PaH] and does not depend on other states • Complexity reduction increases the score • The likelihood of FamilyH is increased when |H| is smaller • The likelihood of Familychild(H) is decreased and towards a single state significantly plunges. X2 X3 X1 FindHidden with Agglomeration 0.1 0.5 not introducing new independencies H 0.08 0.4 0.06 0.3 log-loss (bits/instance) Y1 Y2 Y3 0.04 0.2 0.02 0.1 h { 1 , 2 , … , n } h { 1 , 2 , … , n-1 } 0 Original Representation: The I-map—minimal structure which implies only independencies that hold in the marginal distribution—is typically complex Improve Learning: Models with fewer parameters allow us to learn faster and more robustly. NEWS HR LVFAILURE VENTLUNG STOCK TB INTUBATION Log-loss performance of FindHidden with and without agglomeration on test and real-life data. Base line is the performance of the original input network