Download

1 / 48
500 likes | 903 Views
Print out the two PI questions on cache diagrams and bring copies to class for students to work on. Reading – 5.3, 5.4. Memory Subsystem Design. or Nothing Beats Cold, Hard Cache.

E N D
Print out the two PI questions on cache diagrams and bring copies to class for students to work on. Reading – 5.3, 5.4 Memory Subsystem Design or Nothing Beats Cold, Hard Cache Peer Instruction Lecture Materials for Computer ArchitecturebyDr. Leo Porteris licensed under aCreative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
The memory subsystem Computer Control Input Memory Output Datapath
Movie Rental Store • You have a huge warehouse with EVERY movie ever made (hits, training films, etc.). • Getting a movie from the warehouse takes 15 minutes. • You can’t stay in business if every rental takes 15 minutes. • You have some small shelves in the front office. Think for a bit about what you Might do to improve this (on your own) Office Warehouse
Here are some suggested improvements to the store: • Whenever someone rents a movie, just keep it in the front office for a while in case someone else wants to rent it. • Watch the trends in movie watching and attempt to guess movies that will be rented soon – put those in the front office. • Whenever someone rents a movie in a series (Star Wars), grab the other movies in the series and put them in the front office. • Buy motorcycles to ride in the warehouse to get the movies faster • Extending the analogy to locality for caches, which pair of changes most closely matches the analogous cache locality? Office Warehouse
Memory Locality • Memory hierarchies take advantage of memory locality. • Memory locality is the principle that future memory accesses are near past accesses. • Memories take advantage of two types of locality • -- near in time => we will often access the same data again very soon • -- near in space/distance => our next access is often very close to our last access (or recent accesses). (this sequence of addresses exhibits both temporal and spatial locality) 1,2,3,1,2,3,8,8,47,9,10,8,8...
From the book we know SRAM is very fast, expensive ($/GB), and small. We also know Disks are slow, inexpensive ($/GB), and large. Which statement best describes the role of cache when it works.
Locality and cacheing • Memory hierarchies exploit locality by cacheing (keeping close to the processor) data likely to be used again. • This is done because we can build large, slow memories and small, fast memories, but we can’t build large, fast memories. SRAM access times are 0.5 – 2.5ns at cost of $2000 to $5000 per GB. DRAM access times are 60-120ns at cost of $20 to $75 per GB. Disk access times are 5 to 20 million ns at cost of $.20 to $2 per GB.
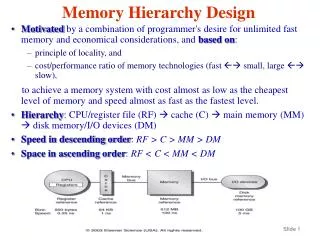
A typical memory hierarchy CPU memory small expensive $/bit fast on-chip cache(s) memory off-chip cache memory main memory memory big disk cheap $/bit slow • so then where is my program and data??
Cache Fundamentals cpu lowest-level cache • cache hit -- an access where the data is found in the cache. • cache miss -- an access which isn’t • hit time -- time to access the cache • miss penalty -- time to move data from further level to closer, then to cpu • hit ratio -- percentage of time the data is found in the cache • miss ratio -- (1 - hit ratio) next-level memory/cache
Cache Fundamentals, cont. cpu • cache block size or cache line size– the amount of data that gets transferred on a cache miss. • instruction cache -- cache that only holds instructions. • data cache -- cache that only caches data. • unified cache -- cache that holds both. lowest-level cache next-level memory/cache
Cacheing Issues cpu access On a memory access - • How do I know if this is a hit or miss? On a cache miss - • where to put the new data? • what data to throw out? • how to remember what data this is? lowest-level cache miss next-level memory/cache
A simple cache address string: 4 00000100 8 00001000 12 00001100 4 00000100 8 00001000 20 00010100 4 00000100 8 00001000 20 00010100 24 00011000 12 00001100 8 00001000 4 00000100 the tag identifies the address of the cached data • A cache that can put a line of data anywhere is called ______________ • The most popular replacement strategy is LRU ( ). tag data 4 blocks, each block holds one word, any block can hold any word. Fully associative Point out the tag IDs the address (pointer) data is The value
Fully Associative Cache addresses 4 00 00 01 00 8 00 00 10 00 12 00 00 11 00 4 00 00 01 00 8 00 00 10 00 20 00 01 01 00 4 00 00 01 00 8 00 00 10 00 20 00 01 01 00 24 00 01 10 00 12 00 00 11 00 8 00 00 10 00 4 00 00 01 00 tag data 4 blocks, each block holdsone word, any block can hold any word.
A simpler cache an index is used to determine which line an address might be found in address string: 4 00000100 8 00001000 12 00001100 4 00000100 8 00001000 20 00010100 4 00000100 8 00001000 20 00010100 24 00011000 12 00001100 8 00001000 4 00000100 • A cache that can put a line of data in exactly one place is called __________________. • Advantages/disadvantages vs. fully-associative? tag data 00000100 4 blocks, each block holds one word, each word in memory maps to exactly one cache location. Direct Mapped
Direct Mapped Cache 4 8 12 4 8 20 4 8 20 24 12 8 4 addresses 00 00 01 00 00 00 10 00 00 00 11 00 00 00 01 00 00 00 10 00 00 01 01 00 00 00 01 00 00 00 10 00 00 01 01 00 00 01 10 00 00 00 11 00 00 00 10 00 00 00 01 00 A M M M H H M M H H M H H H B M M M H H M M H M M H M M C M M M H H M H H H M M H M D M H M H H M H H H M H H M E None are correct tag data 00 01 10 11 4 blocks, each block holds one word, each word in memory maps to exactly one cache location.
An n-way set-associative cache address string: 4 00000100 8 00001000 12 00001100 4 00000100 8 00001000 20 00010100 4 00000100 8 00001000 20 00010100 24 00011000 12 00001100 8 00001000 4 00000100 • A cache that can put a line of data in exactly n places is called n-way set-associative. • The cache lines/blocks that share the same index are a cache ____________. 00000100 tag data tag data 4 entries, each block holds one word, each word in memory maps to one of a set of n cache lines Set
2-way Set Associative Cache 4 8 12 4 8 20 4 8 20 24 12 8 4 addresses 00 000 1 00 00 001 0 00 00 001 1 00 00 000 1 00 00 001 0 00 00 010 1 00 00 000 1 00 00 001 0 00 00 010 1 00 00 011 0 00 00 001 1 00 00 001 0 00 00 000 1 00 A M M M H H M H H H M M H M B M M M H H M M H M M H M M C M M M H H M M H H M M H M D M H M H H M H H H M H H M E None are correct tag data tag data 0 1 4 entries, each block holds one word, each word in memory maps to one of a set of n cache lines
Longer Cache Blocks address string: 4 00000100 8 00001000 12 00001100 4 00000100 8 00001000 20 00010100 4 00000100 8 00001000 20 00010100 24 00011000 12 00001100 8 00001000 4 00000100 00000100 tag data • Large cache blocks take advantage of spatial locality. • Too large of a block size can waste cache space. • Longer cache blocks require less tag space DM, 4 blocks, each block holds two words, each word in memory maps to exactly one cache location (this cache is twice the total size of the prior caches).
Longer Cache Blocks 4 8 12 4 8 20 4 8 20 24 12 8 4 addresses 00 0 00 100 00 0 01 000 00 0 01 100 00 0 00 100 00 0 01 000 00 0 10 100 00 0 00 100 00 0 01 000 00 0 10 100 00 0 11 000 00 0 01 100 00 0 01 000 00 0 00 100 tag data DM, 4 blocks, each block holds two words, each word in memory maps to exactly one cache location (this cache is twice the total size of the prior caches).
Cache Parameters Draw it #entries Cache size = Number of sets * block size * associativity -128 blocks, 32-byte block size, direct mapped, size = ? -128 KB cache, 64-byte blocks, 512 sets, associativity = ? 2^7*2^5=2^12 2^17 / 2^6 = 2^11 2^11/2^9 = 2^2
Equations • All “sizes” are in bytes • log2(block_size) • log2(cache_size /(assoc*block_size)) • 32 – log2(cache_size/assoc)
Descriptions of caches • Exceptional usage of the cache space in exchange for a slow hit time • Poor usage of the cache space in exchange for an excellent hit time • Reasonable usage of cache space in exchange for a reasonable hit time
ICache Reg Dcache Reg ALU Handling a Cache Access 1. Use index and tag to access cache and determine hit/miss. 2. If hit, return requested data. 3. If miss, select a cache block to be replaced, and access memory or next lower cache (possibly stalling the processor). -load entire missed cache line into cache -return requested data to CPU (or higher cache) 4. If next lower memory is a cache, goto step 1 for that cache. IF ID EX MEM WB
Accessing a Sample Cache Point out valid Bit – show the data Can be grabbed in || With tag compare • 64 KB cache, direct-mapped, 32-byte cache block size 31 30 29 28 27 ........... 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 tag index block offset 11 16 tag data valid 0 1 2 ... ... ... ... 2045 2046 2047 64 KB / 32 bytes = 2 K cache blocks/sets 256 = 32 hit/miss
Accessing a Sample Cache • 32 KB cache, 2-way set-associative, 16-byte block size 31 30 29 28 27 ........... 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 tag index block offset 10 18 tag data tag data valid valid 0 1 2 ... ... ... ... 1021 1022 1023 32 KB / 16 bytes / 2 = 1 K cache sets = = hit/miss
for(int i = 0; i<10,000,000;i++) sum+=A[i]; Assume each element of A is 4 bytes and sum is kept in a register. Assume a baseline direct-mapped 32KB L1 cache with 32 byte blocks. Which changes would help the hit rate of the above code? Isomorphic
for(int i=0; i<10,000,000;i++) for(int j = 0; j<8192;j++) sum+= A[j] – B[j]; Assume each element of A and B are 4 bytes and each array is at least 32KB in size. Assume sum is kept in a register. Assume a baseline direct-mapped 32KB L1 cache with 32 byte blocks. Which changes would help the hit rate of the above code?
Assume a 1KB Cache with 64 byte blocks. Assume the following byte-address are repeatedly accessed in a loop. 1 2 3 000000 0000 000000 000000 0100 000100 000001 0000 000000 000000 0000 000000 000000 1000 000100 000001 0000 000000 000000 0000 000000 000000 0100 000100 000001 1000 000000 *The addresses above are broken up (bitwise) for a DM Cache. For which of the address streams above does a 2-way set-associative cache (same size cache, same block size) suffer a worse hit rate than a DM cache? 1: 33% DM, 100% 2-way 2: 33% DM, 0% 2-way 3: 100% DM, 100% 2-way
Dealing with Stores There have been a number of issues glossed over – we’ll cover those now • Stores must be handled differently than loads, because... • they don’t necessarily require the CPU to stall. • they change the content of cache/memory (creating memory consistency issues) • may require a and a store to complete Load Draw value in cache vs. not in cache
Policy decisions for stores Write-through Write-back • Keep memory and cache identical? • => all writes go to both cache and main memory • => writes go only to cache. Modified cache lines are written back to memory when the line is replaced. • Make room in cache for store miss? • write-allocate => on a store miss, bring written line into the cache • write-around => on a store miss, ignore cache
Store Policies • Given either high store locality or low store locality, which policies might you expect to find?
Dealing with stores • On a store hit, write the new data to cache. In a write-through cache, write the data immediately to memory. In a write-back cache, mark the line as dirty. • On a store miss, initiate a cache block load from memory for a write-allocate cache. Write directly to memory for a write-around cache. • On any kind of cache miss in a write-back cache, if the line to be replaced in the cache is dirty, write it back to memory.
Cache Performance CPI = BCPI + MCPI • BCPI = base CPI, which means the CPI assuming perfect memory (BCPI = peak CPI + PSPI + BSPI) • PSPI => pipeline stalls per instruction • BSPI => branch hazard stalls per instruction • MCPI = the memory CPI, the number of cycles (per instruction) the processor is stalled waiting for memory. MCPI = accesses/instruction * miss rate * miss penalty • this assumes we stall the pipeline on both read and write misses, that the miss penalty is the same for both, that cache hits require no stalls. • If the miss penalty or miss rate is different for Inst cache and data cache (common case), then MCPI = I$ accesses/inst*I$MR*I$MP + D$ acc/inst*D$MR*D$MP
Cache Performance • Instruction cache miss rate of 4%, data cache miss rate of 10%, BCPI = 1.0 (no data or control hazards), 20% of instructions are loads and stores, miss penalty = 12 cycles, CPI = ? CPI = 1 + %insts*%miss*miss_penalty CPI = 1+(1.0)*.04*12 + .2*.10*12 = 1+ .48+.24 =1.72
Example -- DEC Alpha 21164 Caches Instruction Cache Unified L2 Cache • ICache and DCache -- 8 KB, DM, 32-byte lines • L2 cache -- 96 KB, ?-way SA, 32-byte lines • L3 cache -- 1 MB, DM, 32-byte lines Off-Chip L3 Cache 21164 CPU core Data Cache
Cache Alignment memory address tag index block offset • The data that gets moved into the cache on a miss are all data whose addresses share the same tag and index (regardless of which data gets accessed first). • This results in • no overlap of cache lines • easy mapping of addresses to cache lines (no additions) • data at address X always being present in the same location in the cache block (at byte X mod blocksize) if it is there at all. • Think of main memory as organized into cache-line sized pieces (because in reality, it is!). Memory 0 1 2 3 4 5 6 7 8 9 10 . . . . . .
Three types of cache misses • Compulsory (or cold-start) misses • first access to the data. • Capacity misses • we missed only because the cache isn’t big enough. • Conflict misses • we missed because the data maps to the same line as other data that forced it out of the cache. address string: 4 00000100 8 00001000 12 00001100 4 00000100 8 00001000 20 00010100 4 00000100 8 00001000 20 00010100 24 00011000 12 00001100 8 00001000 4 00000100 tag data DM cache
Reading Quiz Variant • Suppose you experience a cache miss on a block (let's call it block A). You have accessed block A in the past. There have been precisely 1027 different blocks accessed between your last access to block A and your current miss. Your block size is 32-bytes and you have a 64KB cache. What kind of miss was this? Explain the way to know if it Is a capacity vs. conflict – awould A fully associative cache of the Same size get a miss
So, then, how do we decrease... Block Size, Prefetch • Compulsory misses? • Capacity misses? • Conflict misses? Increase Cache Size Increase Associativity
Cache Miss Components One-way conflict Two-way conflict Four-way conflict Capacity
LRU replacement algorithms • only needed for associative caches • requires one bit for 2-way set-associative, 8 bits for 4-way, 24 bits for 8-way. • can be emulated with log n bits (NMRU) • can be emulated with use bits for highly associative caches (like page tables) • However, for most caches (eg, associativity <= 8), LRU is calculated exactly.
Caches in Current Processors • A few years ago, they were DM at highest level (closest to CPU), associative further away (this is less true today). Now they are less associative near the processor (4-8), and more farther away (8-16). • split I and D close to the processor (for throughput rather than miss rate), unified further away. • write-through and write-back both common, but never write-through all the way to memory. • 64-byte cache lines common (but getting larger) • Non-blocking • processor doesn’t stall on a miss, but only on the use of a miss (if even then) • this means the cache must be able to keep track of multiple outstanding accesses.
Prefetching • “Watch the trends in movie watching and attempt to guess movies that will be rented soon – put those in the front office.” • Hardware Prefetching • suppose you are walking through a single element in an array of large objects • hardware determines the “stride” and starts grabbing values early • Software Prefetching • Load instruction to $0 a fair number of instructions before it is needed
Writing Cache-Aware Code • Focus on your working set • If your “working set” fits in L1 it will be vastly better than a “working set” that fits only on disk. • If you have a large data set – do processing on it in chunks. • Think about regularity in data structures (can a prefetcher guess where you are going – or are you pointer chasing) • Instrumentation tools (PIN, Atom, PEBIL) can often help you analyze your working set • Profiling can give you idea of which section of code is dominant which can tell you where to focus HW – matrix example
Working Set Size Hit Rate 64, 256, 4096 Nehalem Cache Size (KB)
Key Points • Caches give illusion of a large, cheap memory with the access time of a fast, expensive memory. • Caches take advantage of memory locality, specifically temporal locality and spatial locality. • Cache design presents many options (block size, cache size, associativity, write policy) that an architect must combine to minimize miss rate and access time to maximize performance.