Download

1 / 29
290 likes | 422 Views
A Sorting Classification of Parallel Rendering. Molnar et al., 1994. What’s this about?. Describes a classification scheme for comparing parallel rendering systems Based on where the sort from object coordinates to screen coordinates occurs

E N D
A Sorting Classification of Parallel Rendering Molnar et al., 1994
What’s this about? • Describes a classification scheme for comparing parallel rendering systems • Based on where the sort from object coordinates to screen coordinates occurs • Supports analysis of computational and communication costs and encompasses current and proposed highly parallel renderers (both hardware and software)
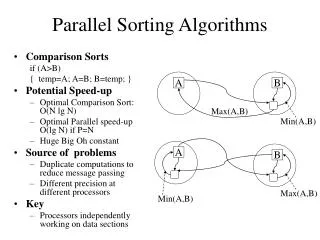
Parallel rendering as a sorting problem • The classification scheme is for “Fully Parallel” systems, i.e. rendering rate is high enough that geometry processing and rasterization must be done in parallel • geometry processing (transformation, clipping, lighting) • rasterization (scan conversion, shading, visibility determination) • Usually geometry is parallelized by assigning each processor a subset of primitives (objects) in a scene • And rasterization is parallelized by assigning each processor a portion of the pixel calculations • Mainly by rendering we are trying to calculate the effect each primitive (object) has on a pixel • Since a primitive may be on or off the screen, rendering can be viewed as a problem of sorting primitives to the screen [Sutherland] • For “fully parallel” renders, sorting involves a redistribution of data between processors because the responsibility for primitives and pixels is distributed
Parallel rendering (cont) • The location of the sort determines the structure of the resulting parallel rendering system and in general the sort can take place anywhere in the rendering pipeline. • sort-first : sort during geometry processing • redistributing “raw” primitives before their screen space parameters are known • sort-middle : sort between geometry processing and rasterization • redistributing screen-space primitives • sort-last : sort during rasterization • redistributing pixels, samples or pixel fragments
Sort-first • No known implementations? • Goal is to distribute primitives early in the rendering pipeline to processors that can do the remaining rendering calculations. • Done by dividing the screen into disjoints regions and making processors (renderers) responsible for all rendering calculations that affect their screen region. • Initially, primitives are assigned to renderers in an arbitrary fashion. • At the start of rendering, each renderer does enough transformation to determine which region(s) each primitive falls. This is pre-transformation. • If a renderer contains a primitive which does not belong in it’s screen region, the primitive is redistributed over an interconnect network to the appropriate renderer(s) which perform the remaining geometry processing and rasterization for the primitive. • Redistribution (at the beginning of rendering) is the distinguishing feature of sort-first.
Analysis • Advantages: • Communication requirements are low when the tessellation ratio and the degree of oversampling are high, or when frame-to-frame coherence can be exploited • Processing nodes implement the entire rendering pipeline for a portion of the screen • Disadvantages: • Susceptibility to load imbalance. Primitives may clump into regions, concentrating the work on a few renders. • Necessity of retained mode and complex data handling code to take advantage of frame-to-frame coherence.
Sort-middle • Most common approach. • Primitives are redistributed in the middle of the rendering pipeline between geometry processing and rasterization. • At the point of redistribution, primitives have been transformed into screen coordinates and are ready for rasterization. • Many systems use separate processors for geometry processing and rasterization so this is a natural point to divide the pipeline. • In sort-middle, geometry processors are assigned arbitrary subsets of the primitives to be displayed and rasterizer(s) are assigned a portion of the display screen • During each frame, geometry processors transform, light, etc their portion of the primitives and classify them with respect to screen region boundaries. • Then they transmit all these screen-space primitives to the appropriate rasterizer(s).
Analysis • Advantages: • General and straightforward • Redistribution occurs at natural place in the pipeline • Disadvantages: • High communication costs if the tessellation ratio is high • Susceptibility to load imbalance between rasterizers when primitives are distributed unevenly over the screen
Sort-last • Sorting deferred until end of rendering pipeline, after primitives have been rasterized • Each renderer is assigned an arbitrary subset of the primitives • Each renderer computes pixel values for its primitives • Pixel values are then transmitted over interconnect network to compositing processors which resolve the visibility of the pixels from each renderer • Two approaches: • SL-sparse: minimizes communication by distributing only those pixels actuall produced by rasterization • SL-full: stores and transfers a full image from each renderer
Analysis • Advantages: • Processing nodes implement the entire rendering pipeline for a portion of the primitives • Less prone to load imbalance • SL-full merging can be embedded in a linear network, making it linearly scalable • Disadvantages: • Pixel traffic can be extremely high
Talisman: Commodity Realtime 3D Graphics for the PC Jay Torborg and Jim Kajiya, Microsoft Corporation 1996
What is it? • New architecture for 3D graphics • Cost $200-$300 • Requirements? Smooth motion, synchronized with sound and video and low-latency interaction (want real-time at 72-85Hz)
Limitations of Traditional Architectures • High Memory Bandwidth Requirement • System Latency • Cost/Memory Cost
Composited Image Layers • Independent image layer for each non-interpenetrating object in the scene • Each object can be updated independently (optimize updates based on priority) • Layers can be arbitrary size and shape • Image layers are composited at video rates • Support image layer transformations at video rates (scaling, rotation) • Typically, the same rendered image can be used for 4 frames
Image Compression • Used for textures and image layers • Lossless and lossy compression supported • Significantly reduces bandwidth and capacity requirements • 16:1 texture compression • 5:1 image layer compression
Chunking • Each image layer is rendered in 32x32 chunks • All polygons for a 32x32 chunk are rendered before proceeding to next chunk • Allows 32x32 depth buffer to be on-chip • Anti-aliasing supported with depth buffering and translucency using on-chip fragment buffer
High Quality Rendering • Anisotropic filtering of textures • Multipass rendering • Shadows, spot lights, fog • Antialiasing
Reference Hardware • Targets high-end consumer PC market • Uses PCI expansion bus • Replaces: • Windows accelerator board • 3D accelerator board • MPEG playback board • Video conferencing board • Sound board • modem
Polygon Object Processor • Polygons are processed in 32x32 chunks • Initial Evaluation • Computes intersection of a chunk with a triangle and computes the values for color, transparency, depth and texture coordinates for the starting point of the triangle within the chunk • Pixel Engine • Performs pixel level calculations (compositing, depth buffering, fragment generation) for pixels which are partially covered • Fragment Resolve • Performs final anti-aliasing by resolving depth sorted pixel fragments with partial coverage or transparency
Image Layer Compositor • Responsible for generating the graphics output from a collection of depth sorted image layers • Locked to the video refresh • Data structure maintains z-sorted list of image layers visible in each 32 scanline region • Performs affine transforms (scaling, rotation) • Passes pixel and alpha data to compositing buffer at four pixels per clock cycle
Compositing Buffer • Simple specialty memory • Contains two 32-scanline buffers for double buffering of scanline regions • one sl buffer for compositing the other for display
Software • DirectDraw, Direct3D, DirectSound • Media DSP • Real-time kernel on DSP for scheduling and load balancing
Performance • High Resolution Display • 1344x1024 @ 75Hz • 24 bit color at all resolutions • 20-30k polygon scene complexity • 40 MPix/sec w/ anisotropic texturing and anti-aliasing