Download

1 / 18
190 likes | 338 Views
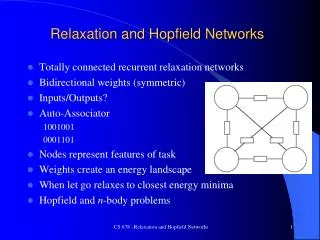
Concept Learning and Optimisation with Hopfield Networks. Kevin Swingler University of Stirling Presentation to UKCI 2011, Manchester. Hopfield Networks. Hopfield Networks. Hopfield Networks. Example – Learning Digit Images. How?. Learning w ij = w ij + u i u j Recall

E N D
Concept Learning and Optimisation with Hopfield Networks Kevin Swingler University of Stirling Presentation to UKCI 2011, Manchester
How? • Learning wij = wij + ui uj • Recall ui = Σj≠i wij uj uj wij ui
Learning Concepts or Optimal Patterns Concept = Symmetry σ
How? • Weight update rule is adapted to: wij = wij + σui uj uj wij ui
Examples Concept = Symmetry Concept = Horizontal
Speed Simple Target
Relation to EDA Current pattern, P = p1 ... pn f(P) = Score for pattern P EDA Probabilities, R = r1 ... rn Probability that element i=1: P(pi = 1) = ri Probability update rule: ri = ri+f(P) if pi = 1
Relation to EDA Probability that element i=1: P(pi = 1) = g(W, pj≠i) Not stochastic, but marginal probabilities are not known Settling the network from a random state samples from the learned distribution without the need for joint distribution sampling explicitly.
Practicalities 1 • If P is an attractor state for the network, then so is P` • Scores for target patterns need their distance metric altered accordingly • Or compare both the pattern and its inverse and score the highest =
Practicalities 2 • The random patterns used during training must have elements drawn from an even distribution • Deviation from this impairs learning
Uses and Benefits • In situations where there are many possible solutions, this provides a method of sampling random good solutions without the need for additional searching • Solutions tend to be close to the seeded start point, so you can use this method to find a local optimum that is close to a start point – again, without actually searching
Limitations • The storage capacity of the network • The size of the search space • Can we use a sparser connected network? • Inverse patterns need care • Currently: • Only tested on binary patterns • No evolution of patterns – stimuli must all be random
Thank You • kms@cs.stir.ac.uk • www.cs.stir.ac.uk/~kms