Download

1 / 22
220 likes | 225 Views
This text discusses natural language understanding in SDS, meaning representations, and evaluating SDS. It explores the use of semantic grammars and semantic HMMs, as well as managing user input and priming user responses. It also covers the issues of training and evaluating dialogue systems.

E N D
Building and Evaluating SDS Julia Hirschberg LSA07 353
Today • Natural Language Understanding (NLU) in SDS • Meaning representations • Evaluating SDS
The NLU Component • What kinds of meanings do we want to capture? • Entities, actions, events, times… • E.g. an airline travel domain • Entities: flights, airlines, cities • Actions: look up, reserve, fly • Modifiers: first, next, latest • Events: departures, arrivals • Temporals: dates, hours • How should we represent these in our system? • What does an SDS need from a meaning representation?
Be able to • Answer questions • When does the first flight from Boston to Philadelphia leave on July 7? • Determine truth • Is there a flight from Boston to Philadelphia? • Draw inferences • Is there a connecting flight to Denver?
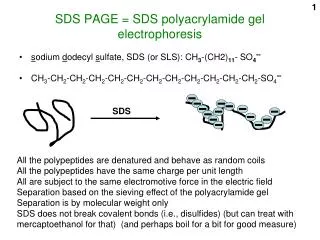
Most SDS use Semantic Grammars • Robust parsing, or, information extraction • Define grammars specifically in terms of the semantic information we want to extract • Domain specific rules correspond to items in the domain I want to go from Boston to Baltimore on Thursday, September 24th • TripRequest Greeting Need-specification travel-verb from City to City on Date • Greeting {Hello|Hi|Um|ε} • Need-specification {I want|I need} • …
Grammar elements can be mapped directly to slots in semantic frames
Drawbacks of Semantic Grammars • Lack of generality • A new one for each application • Very costly in development time • Constant updates • Can be very large, depending on how much coverage you want them to have • If users go outside grammar, things may break disastrously I want to leave from my house at 10 a.m. I want to talk to a person.
Semantic HMMs • Train sequential model on labeled corpora to identify semantic slots from user input I want /Need spec to go /Travel verb to Boston /To-city on Thursday /Date. • Relies on training corpus to provide • Likely sequences of semantic slots • Likely words associated with those slots • Can be used to fill slots in template • Or to directly generate a response while processing input
Managing User Input • Rely heavily on knowledge of task and constraints on user actions • Handle fairly sophisticated phenomena I want to go to Boston next Thursday. I want to leave from there on Friday for Baltimore. • TripRequest Need-spec travel-verb from City on Date for City • Dialogue postulates and simple discourse history handle reference resolution • Use prior probabilities based on training corpus to resolve ambiguities, e.g. Boston Baltimore on July 12
Priming User Input • Hypothesis: Users tend to use the vocabulary and syntax the system uses • Lexicalentrainment experiments(Clark & Brennan ’96) • Re-use of system prompt vocabulary/syntax: Please tell me where you would like to leave/depart from. I would like to leave/depart from Boston… • Evidence from KTH data collections in field
User Responses to Vaxholm The answers to the question: “What weekday do you want to go?” (Vilken veckodag vill du åka?) • 22% Friday (fredag) • 11% I want to go on Friday (jag vill åka på fredag) • 11% I want to go today (jag vill åka idag) • 7% on Friday (på fredag) • 6% I want to go a Friday (jag vill åka en fredag) • - are there any hotels in Vaxholm?(finns det några hotell i Vaxholm)
Verb Priming: How often do you go abroad on holiday? Hur ofta åker du utomlands på semestern? Hur ofta reser du utomlands på semestern? jag reser en gång om året utomlands jag reser inte ofta utomlands på semester det blir mera i arbetet jag reserreser utomlands på semestern vartannat år jag reser utomlands en gång per semester jag reser utomlands på semester ungefär en gång per år jag brukar resa utomlands på semestern åtminståne en gång i året en gång per år kanske en gång vart annat år varje år vart tredje år ungefär nu för tiden inte så ofta varje år brukar jag åka utomlands jag åker en gång om året kanske jag åker ganska sällan utomlands på semester jag åker nästan alltid utomlands under min semester jag åker ungefär 2 gånger per år utomlands på semester jag åker utomlands nästan varje år jag åker utomlands på semestern varje år jag åker utomlands ungefär en gång om året jag är nästan aldrig utomlands en eller två gånger om året en gång per semester kanske en gång per år ungefär en gång per år åtminståne en gång om året nästan aldrig
Results no reuse no answer 4% 2% other 24% reuse 52% 18% ellipse
Issue: Training and SDS • Is implicit training ‘better’ than explicit? • Is it easier to train the user than to retrain the system
Evaluating Dialogue Systems • PARADISE framework (Walker et al ’00) • “Performance” of a dialogue system is affected both by whatgets accomplished by the user and the dialogue agent and howit gets accomplished Maximize Task Success Minimize Costs Efficiency Measures Qualitative Measures
Task Success • Task goals seen as Attribute-Value Matrix • ELVIS e-mail retrieval task(Walker et al ‘97) • “Find the time and place of your meeting with Kim.” Attribute Value Selection Criterion Kim or Meeting Time 10:30 a.m. Place 2D516 • Task success defined by match between AVM values at end of with “true” values for AVM
Metrics • Efficiency of the Interaction:User Turns, System Turns, Elapsed Time • Quality of the Interaction: ASR rejections, Time Out Prompts, Help Requests, Barge-Ins, Mean Recognition Score (concept accuracy), Cancellation Requests • User Satisfaction • Task Success: perceived completion, information extracted
Experimental Procedures • Subjects given specified tasks • Spoken dialogues recorded • Cost factors, states, dialog acts automatically logged; ASR accuracy,barge-in hand-labeled • Users specify task solution via web page • Users complete User Satisfaction surveys • Use multiple linear regression to model User Satisfaction as a function of Task Success and Costs; test for significant predictive factors
Was Annie easy to understand in this conversation? (TTS Performance) In this conversation, did Annie understand what you said? (ASR Performance) In this conversation, was it easy to find the message you wanted? (Task Ease) Was the pace of interaction with Annie appropriate in this conversation? (Interaction Pace) In this conversation, did you know what you could say at each point of the dialog? (User Expertise) How often was Annie sluggish and slow to reply to you in this conversation? (System Response) Did Annie work the way you expected her to in this conversation? (Expected Behavior) From your current experience with using Annie to get your email, do you think you'd use Annie regularly to access your mail when you are away from your desk? (Future Use) User Satisfaction:Sum of Many Measures
Performance Functions from Three Systems • ELVIS User Sat.= .21* COMP + .47 * MRS - .15 * ET • TOOT User Sat.= .35* COMP + .45* MRS - .14*ET • ANNIE User Sat.= .33*COMP + .25* MRS +.33* Help • COMP: User perception of task completion (task success) • MRS: Mean recognition accuracy (cost) • ET: Elapsed time (cost) • Help: Help requests (cost)
Performance Model • Perceived task completion and mean recognition score are consistently significant predictors of User Satisfaction • Performance model useful for system development • Making predictions about system modifications • Distinguishing ‘good’ dialogues from ‘bad’ dialogues • But can we also tell on-line when a dialogue is ‘going wrong’
Next Class • J&M 22.5 • Jurafsky et al ’98 • Rosset & Lamel ‘04