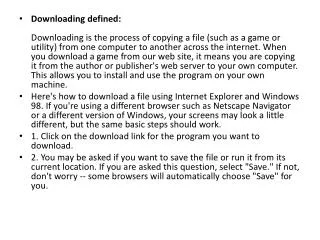
Download

1 / 17
200 likes | 537 Views
Workshop, 3rd Semester. Web Crawler. What is a Web Crawler ?. A crawler could be a part of: a search engine, where every page is searched for a search string a spam agent that visits all sites and collects email addresses a site map creation application. Goal for workshop.

E N D
Workshop, 3rd Semester Web Crawler
What is a Web Crawler ? • A crawler could be a part of: • a search engine, where every page is searched for a search string • a spam agent that visits all sites and collects email addresses • a site map creation application
Goal for workshop • Develop a web crawler that takes an URI as input and visits all pages at the identified site. • The web crawler must search HTML documents for links and build a graph containing documents as vertices (nodes) and links as edges.
Subjects • Graphs • HTML • Simple parsing • http and tcp • Design patterns
Graphs • To represent the site you can use a directed graph: • HTML documents being represented by vertices (nodes) • links being represented by edges
HTML • Every page the crawler visits is a HTML document. • The HTML document should be investigated for link tags • <a href = ”http://www.prenhall.com”>Prentice Hall</a> • Frames (frame sets) are to be considered as individual and independent HTML pages
Simple parsing • The simple version searches the HTML documents for links by using ”brute force” • It is obvious to investigate other techniques • state machines • regular expressions • recursive descend
Communication • For communication use the .NET sockets class • HTTP and TCP • URI, URL etc.
Design patterns • Design patterns should be applied wherever appropriate
The program • Overall structure • Graph • HTML • HTTP • Crawler
Testsite • http://public.noea.dk/fen/testsite/
Schedule for the Week • Day 1 – Monday • .Net socket class and graph implementation. (PQC) • Day 2 – Tuesday • Working with practical html parsing, coupling with the http class. Parsing techniques. (CHJO) • Day 3 – Wednesday • Continue working on your own. • Day 4 – Thursday • Putting it all together: graph-, html- and the http part. The crawler algorithm. (PQC) • Day 5 – Friday • Finishing up and preparing the presentation (CHJO). • Presentation and evaluation • Thursday, April 29, 8.30 – 10.00
Evaluation • Nothing in writing, but every team gives a presentation: • Results are presented in Powerpoint presentations: • class model • design issues etc. • A demo • Review and discussion of interesting code fragments • Approximately 20 minutes per team • Participation in the evaluation is mandatory. • Need to hand in report if you do not attend evaluation.