Download

1 / 41
820 likes | 2.03k Views
(text mining) متن كاوي. سارا مصباح بهار 88. فهرست مطالب. مقدمه مشكلات هدف متن كاوي كاربردهاي متن كاوي فرآيند متن كاوي يافتن روابط ( Rajman_97 ) روش TextMiner ( Karanikas_2000 ) روش DIScoTEX ( Kanya_07, Mooney_05 ) بهبود روش DIScoTEX ( Kanya_07, Mooney_05 ).

E N D
(text mining) متن كاوي سارا مصباح بهار 88
فهرست مطالب • مقدمه • مشكلات • هدف متن كاوي • كاربردهاي متن كاوي • فرآيند متن كاوي • يافتن روابط (Rajman_97) • روش TextMiner (Karanikas_2000) • روش DIScoTEX(Kanya_07, Mooney_05 ) • بهبود روش DIScoTEX (Kanya_07, Mooney_05 )
منابع براي توضيحات اين بخش • M. Rajman. Text Mining, knowledge extraction from unstructured textual data. Proc. of EUROSTAT Conference, Francfort (Deutchland), may, 1997 • Data mining Concepts and Techniques: jiawei Han and Michelinekamber
مقدمه • موجود بودن بخش قابل ملاحظه اي از اطلاعات در پايگاه داده هاي متني • تعريف • استخراج مفهوم و اطلاعات مفيد از دادها ي غير ساخت يافته • جستجوي الگو در متن غير ساخت يافته • مثال: مقالات خبري، paperها، كتاب ها، ايميل هاو..... • نوع اطلاعات ذخيره شده در پايگاه داده هاي متني: غير ساختيافته • مثال: در نظر گرفتن يك سند
مقدمه (ادامه..) • تكنيك هاي پيشنهاد شده براي متن كاوي: • ساختارهاي مفهومي • كاوش كردن association ruleها • درخت هاي تصميم گيري • روش هاي استنتاج قوانين • تكنيك ها ي بازيابي اطلاعات
مشكل • بيش از 80 درصد اطلاعات به صورت متن هستند • مشكل • غير ساختيافته بودن • دريافت دانش از اطلاعات • كمبود دانشي كه از اطلاعات حاصل مي شود • عدم وجود عاميت در داده كاوي • فرض: اطلاعات به فرم پايگاه داده هاي رابطه اي هستند • بازيابي اطلاعات • بازيابي مرتبط ترين مستندات با توجه به نياز كاربر و نه دانش • مثال: ثبت كردن سابقه ايميل ها • ناكارآمد بودن تكنيك هاي بازيابي اطلاعات سنتي براي حجم زيادي از اطلاعات غير ساختيافته • بازيابي سندهاي مربوط كم كشف كردن دانش از متن نيمه ساخت يافته يا غير ساختيافته
هدف • طاقت فرسا بودن، پردازش كردن پايگاه داده هاي متني غير ساختيافته به صورت دستي • اتوماتيك كردن درك معني متن • نياز به ابزارهايي كارآمد براي مقايسه سندهاي مختلف، مرتب كردن سندها بر اساس مربوط بودن، يافتن الگوها براي داده هاي غير ساختيافته با حجم زياد • نام هاي مختلف براي متن كاوي • Text mining • Text data mining • Knowledge Discovery in Text
كاربردها متن كاوي • جستجو و بازيابي • Clustering و classification • خلاصه سازي • استخراج روابط • POS(Part of Speech Tagging)
كاربردهاي متن كاوي (ادامه...) • جستجو و بازيابي اطلاعات • روش هاي جديد در زمينه جستجو و بازيابي اطلاعات با استفاده از متن كاوي • هدف بازيابي اطلاعات: بازيابي مرتبط ترين متون با توجه به نياز كاربر • مبتني بر NLP و machine learning • نياز به يك پايگاه دانش ساخته شده با استفاده از روش هاي مبتني بر NLP و روش هاي آماري بر روي اسناد • Clustering • كمك به يافتن سريعتر اطلاعات مورد نظر كاربر • دادن نگاه كلي از مجموعه اسناد • ساختن كلاس ها به صورت اتوماتيك بدون داشتن مجموعه training • Classification • داشتن كلاس هاي از پيش تعريف شده اي از مفاهيم • نگاشت كردن سندهاي جديد به يكي از كلاس ها
كاربردهاي متني كاوي (ادامه...) • POS • داشتن نقش مهمي در پردازش زبان هاي طبيعي • مثال: سيستم GATE • ابزاري براي برچسب گذاري جملات • پيدا كردن نام موقعيتهاي جغرافيايي، نام اشخاص و... در يك متن
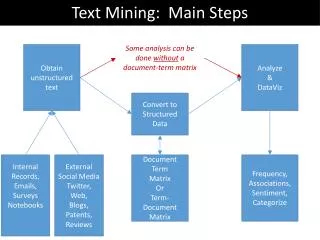
فرآيند متن كاوي • فاز پيش پردازش اسناد • مبتني بر سند • نحوه ي نمايش بهتري براي اسناد • تبديل اسناد به يك فرمت مياني و نيمه ساختيافته • هر entity در اين نمايش نهايتا يك سند است • مبتني بر مفهوم • بهبود بخشيدن به نمايش سند، مفاهيم و معاني موجود در سند و ارتباط ميان آن ها و.... • سر و كار داشتن با مفاهيم استخراج شده از سندها • فاز استخراج دانش از فرمت هاي مياني نمايش اسناد • نمايش مبتني بر سند: گرو بندي، طبقه بندي و..... • نمايش مبتني بر مفهوم: براي يافتن روابط ميان مفاهيم و ساختن اتوماتيك آنتولوژي • استفاده از استخراج اطلاعات به عنوان گام پيش پردازش
يافتن روابط (Rajman_97) • مجموعه اي از كلمات: • مجموعه اي از ميتندات ايندكس شده: • با رابطه • فرض • : مجموعه اي از كلمات كليدي • :مجموعه تمام مستندات t در T • [w]: مجموعه پوششي براي w • به ازاي هر زوج (W,w) كه مجموعه اي از لغات است و يك قانون رابطه خوانده مي شود و به شكل نمايش داده مي شود
يافتن روابط (ادامه..) • با فرض داريم • : ميزان پشتيباني از رابطه، با در نظر گرفتن T • :ميزان اطمينان از رابطه، با در نظر گرفتن T • هدف • يا فتن قوانين كه مقدار S(R,T) و C(R,T) آن ها از ميزاني بيشتر باشد
منبع • HaralamposKaranikas, et.al. An Approach to Text Mining using Information Extraction, 2000
روش Textminer • استخراج كردن termها و eventهاي هر سند براي پيدا كردن ويژگي ها • انجام عمل mining روي ويژگي هاي استخراج شده هر سند • كامپوننت هاي سيستم: • Text Analysis Component • تغيير دادن داده نيمه ساختيافته : سندها به داده ساختيافته ذخيره شده در پايگاه داده • Data mining component • اعمال كردن تكنيك هاي داده كاوي بر روي خروجي كامپوننت اول • اهداف اين روش • مديريت كردن همه اطلاعات موجود : طبقه بندي كردن سندها در category هاي مناسب • Mine كردن داده براي كشف كردن دانش مفيد
روش textminer)استخراج اطلاعات( • نگاشت كردن متن هاي زبان طبيعي (پايگاه داده هاي متني، مقالات، صفحات وب، ايميل هاو...) به يك نمايش ساختيافته و از پيش تعريف شده • نگاشت كردن متن هاي زبان طبيعي به قالب هايي كه منتخبي از اطلاعات كليدي متن را نشان مي دهند • استخراج اطلاعات و ذخيره آنها در پايگاه داده براي انجام پرس و جو، كاوش، خلاصه سازي و.....
مثال (دامنه مالي) • Event هاي براي يك دامنه مالي • نگه داري اطلاعات در جدولي به نام Event type • براي event، take-over • قرار دادن تعداد مختلفي صفت توصيف شده براي هر event • صفات: تاريخ، company targe، نوع take-overو...
روش text miner (ادامه...) • پر كردن جدولي به شكل زير بعد از استخراج eventها Eventهاي استخراج شده • ساختن جدول زير به عنوان ورودي براي الگوريتم كلاسترينگ • در نظر گرفتن سندها به عنوان ركودها در پايگاه داده • در نظر گرفتن term/eventهاي هر سند به عنوان صفات ركورد داده ورودي براي الگوريتم كلاسترينگ
روش text miner (الگوريتم كلاسترينگ) • اعمال الگوريتم كلاسترينگ بر روي پايگاه داده حاصل • ايجاد زيرمجموعه هايي از مجموعه اي از اسناد • كشف ساختار در مجموعه اسناد • قرار دادن سندهايي كه ويژگي هاي مشترك دارند در يك گروه • دادن ديدكلي از داده ها • آسان كردن، يافتن اطلاعات مربوط • استفاده از كلاسترينگ در taskهاي ديگر: آناليز relevance، classification و .................... • انتخاب الگوريتم كلاسترينگ • وابسته به نوع مجموعه داده و task • معروف ترين كلاسترينگ ها • Binary relational clustering • كلاستريگ سلسله مراتبي
الگوريتم كلاسترينگ (ادامه..) • كارا نبودن آناليز كلاسترينگ مبتني بر فاصله • Conceptual clustering • كلاستر ها تنها مجموعه اي از اشيا با شباهت عددي نيستند • مجموعه اي از توصيفات صفات • يك زبان توصيف براي توصيف كلاسترهاي اشيا • يك معيار كيفيت رده بندي • هدف • بيشينه كردن معيار كيفيت • تعيين كردن توصيفات عمومي از كلاسترها • استفاده از روش هاي كلاسترينگ براي داده هاي categorical
الگوريتم كلاسترينگ (ادامه..) • نمايش سندها در پايگاه داده با صفات بولين • متناظر بودن هر صفت با يك event/term • اگر سند شامل term/event متناظر باشد صفت true است • استفاده از frameforkالگوريتم Rock و مفهوم لينك (RI, RC) • Link(pi, pj): بيانگر تعداد همسايه هاي مشترك بين pi و pj استفاده از الگوريتم كلاسترينگ و قرار گرفتن سندهايي با الگوهاي مشابه (term/eventها) در يك كلاستر
الگوريتم classification • اعمال رده بندي بعد از توصيفات به دست آمده از كلاسترينگ • معتبرسازي بيشتر نتايج حاصل از كلاسترينگ • بهره برداري بهتر از دانش كشف شده • الگوريتم درخت تصميم گيري • بازيابي سلسله مراتبي از مفاهيم • تست كردن درستي توصيفات كشف شده
منبع • N. Kanya*, S. Geetha“INFORMATION EXTRACTION -A TEXT MININGAPPROACH” 2007 produced IEEE • “Text mining with InformatinExteraction” Raymond J. Mooney and Un Yong Nahm 2005
DIScoTEX (Discovery form text extraction) • يكپارچه كردن: • سيستم استخراج اطلاعات learn شده (IE) • تبديل سندهاي متن به داده ساخت يافته تر • جستجو كردن بخش هاي خاصي از داده • ماجول استنتاج كردن قوانين استاندارد (KDD) • Mine كردن پايگاه داده ساخت يافته شده حاصل از ماجول IE براي يافتن روابط مورد علاقه • استفاده از قوانين به دست آمده و پيش بيني كردن اطلاعاتي كه از سندهاي جديد استخراج مي شوند • استفاده از applicationهاي آماري و متدهاي machine learning
DIScoTEX(ادامه) ديد كلي از چارچوب mine كردن متن مبتني بر IE • ساختن يك سيستم IE: • استفاده از متدهاي machine learnin براي اتوماتيك كردن ساخت سيستم هاي IE • به صورت دستي توصيف كردن تعداد كمي سند، استخراج داده ها از آن، استنتاج سيستم IE با دقت قابل قبولي و اعمال آن به مجموعه بزرگي از سندها • پايگاه داده استخراج شده به صورت اتوماتيك شامل خطاست
DIScoTEX(ادامه) • ”آيا دانش كشف شده از پايگاه داده داراي نويز reliabity آن خيلي كمتر از دانش كشف شده از يك پايگاه داده تميز تر است؟“ • هدف IE • پيدا كردن داده خاص در يك متن به زبان طبيعي • نمايش داده ها به صورت يك template Template پر شده براي دامنه job-posting
DIScoTEX(ادامه) • استفاده از machine learning براي ساختن استخراج كننده ها • استفاده از دو سيستم state-of-the-art • RAPIER(Robust Automated Production of Information Exteraction Rules) • BWI(Boosted Wrapper induction) • خروجي سيستم IE: • مجموعه اي از Slot ها • به كار بردن الگوهاي استخراج اطلاعات • يك پايگاه داده قابل سرچ و ساخت يافته
DIScoTEX(ادامه) • اعمال تكنيك هاي KDD استاندارد بر روي پايگاه داده نتيجه شده • Training روي مجموعه اي از سندهاي توصيف شده با قالب ها • براي slot، platform داريم پركننده Wnidows XP: Win XP، WinXP، MS Win XP • تبديل كردن termها به يك مقدار قبل از mine كردن قوانين از داده ها • استفاده از يك ديكشنري شامل واژه هاي مترادف با 111 شي • استفاده از C4.5Rules، RIPPER و APRIORI براي كشف قوانين از داده ها
DIScoTEX(ادامه) • APRIORI • الگوريتمي براي كاوش كردن association ruleها با توجه به min sup و min confidence • RIPPER • به سادگي درك شدن • بهتر از درخت تصميم گيري • به سادگي پياده سازي شدن در prolog • الگوريتمي كارا براي داده هاي داراي نويز • توصيف كردن روابط بين مقادير Slotها به فرم قوانين • مثال
DIScoTEX(ادامه..) نمونه قوانين mine شده از يك پايگاه داده 600 resunes (از گروه خبري USENET با استفاده از BWI) • نمونه قوانين mine شده از يك پايگاه داده با 600 job (گروه خبري USENET)با استفاده از RAPIER و C4.5RULES
DIScoTEX (ارزيابي) • اندازه گيري دقت دانش كشف شده • استنتاج كردن قوانيني براي پيش بيني كردن پركننده هاي Slotها • معيارهاي ارزيابي • Precision • Recall • F-measure
نتايج • حذف كردن سندهاي نامربوط توسط bag-of-word Naïve-Bayes text categorizer قبل از ساختن پايگاه داده توسط سيستم IE • Precision براي classifier: 98 درصد • Recall براي classifier • Train كردن RAPIER روي 60 سند برچسب گذاري شده • Precision استخراج: 91.9 درصد • Recall استخراج : 52.4 درصد
بهبود IE • استفاده کردن از قوانین mine شده برای ÷یش بینی استخراج پرکننده های بیشتر • پیش بینی کردن اطلاعات از دست رفته • دو معیار برای ارزیابی IE • Precision • Recall • الگوریتم • بهبود دادن recall بدون قربانی کردن precision • مثال : • استخراج کردن • استخراج نکردن اضافه کردن mobile به Slot, area
بهبود IE(ادامه....) • الگوریتم • اضافه کردن پرکننده به قالب در صورت وجود آن (یا مترادفی از آن) در سند • شبه کد برای mine کردن قوانین
بهبود IE(ادامه....) • شبه کد برای بهبود recall با استفاده از قوانین mine شده
ارزیابی روش بهبود یافته • مجموعه تست • Computer-science job posting600 hand-labeledجمع آوری شده در گروه خبری austin • 4000 سند تفسیر نشده • نتایج
نتايج • ميانگين f-measureبين 86.4درصد تا 88.1 درصد • افزايش recall با افزايش نمونه هاي برچسب گذاري نشده • كاهش precision با افزايش recall • Matching filler به عنوان baseline
منابع • HaralamposKaranikas, et.al. An Approach to Text Mining using Information Extraction, 2000 • N. Kanya*, S. Geetha“INFORMATION EXTRACTION -A TEXT MININGAPPROACH” 2007 produced IEEE • Raymond J. Mooney and Un Yong Nahm 2005 “Text mining with InformatinExteraction” • M. Rajman. Text Mining, knowledge extraction from unstructured textual data. Proc. of EUROSTAT Conference, Francfort (Deutchland), may, 1997 • Data mining Concepts and Techniques: jiawei Han and Michelinekamber