Download
1 / 23
230 likes | 451 Views
Discrete-Time Survival Analysis. Presented by Chien -ti Lee September 12, 2014. Purpose?. To study the probability (or hazard), of experiencing an event. Unlike logistic regression, it takes into a ccount “time” until the event occurs.

E N D
Discrete-Time Survival Analysis Presented by Chien-ti Lee September 12, 2014
Purpose? To study the probability (or hazard), of experiencing an event. • Unlike logistic regression, it takes into account “time” until the event occurs. • It is also different from continuous-time survival analysis (e.g., cox regression) in the following ways: • The data are only collected in time intervals (vs. the exact time an event occurred) • Does not assume hazard-related probability • Probability of hazard: The shape of the survival function over time is the same for all cases/groups • Can be extended with time-varying covariates, mixture components, and distal outcomes etc.
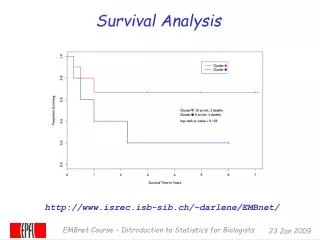
Survival Probability vs. Hazard Probability • T stands for the time interval of the event • Survival Probability= S(J) • J = The time interval in which the event occurs • S(J) = P(T > J) means that the probability of surviving beyond time interval J • Hazard probability= H(J) • H(J) = P(T= J|T ≥ J) means that the probability of the event occurs in the time interval J, provided it has not occurred prior to j • It is the probability of the event occurring in the interval j among those at risk in j • S(J) = P(T ≠J|T≥J)P(T≠J-1|T≥ J-1)…P(T≠2 | T≥2) P(T≠1 | T≥1) =∏ [1- h(k) ]; {k = 1 to a} • ∏ = product of all values in range of series
First you must…Restructure the Dataset Using the “Data Survival” Command in Mplus to Save Time in Restructuring (See Mplus Manual 7, p.379) • To create variables for discrete-time survival modeling where a binary discrete-time survival variable represents whether or not a single *non-repeatable* event has occurred in a specific time period • Here are the rules… • If the original variable is missing, the new binary variable is missing • If the value of the original variable is *greater than* the cutpoint value, the new binary value is “1” indicating that the event has occurred • If the value of the original variable is less than or equal the cutpoint value, the new binary value is “0” indicating that the event has not occurred • After a discrete-time survival variable for an observation is assigned the value “1”, then subsequent discrete-time survival variables for that observation are assigned the value of the missing value flat “ * ”.
Transformation Before After
What about…Missing Data • In the context of survival analysis, missing data usually refers to the event times for some subject that are unknown to the researcher (aka: censoring). • Right Censoring • When a subject has not experienced the event at the end of the observation • Left Censoring • When a subject has experienced the event before you began the observation • It is a very rare phenomenon • The focus of survival analysis is about what happens when risk exposure begins
Truncation • Left truncation often arises when patient information, such as time of diagnosis, is gathered retrospectively. • For example, in a study of disease mortality where the outcome of interest is survival from the time of diagnosis, many patients may not have been enrolled in the study until several months or years after their diagnosis. Those patients, by virtue of having survived to the time of enrollment, could not have had an event between diagnosis and the study enrollment, and therefore they should be removed from the risk set between those two time points. To leave them in the risk set would bias the survival estimates. • Right truncation happens when the individuals whose event time are less than some truncation threshold. • For example, the experiment wants to study the effect of smoking before college. Your question for a group of participants, “when do you start smoking”, can effectively truncate the participants who start smoking after going to college.
Mplus Syntax – Example 6.20 TITLE: this is an example of a *continuous-time* survival analysis using the Cox regression model DATA: FILE = ex6.20.dat; VARIABLE: NAMES = t x tc; ! x is the predictor SURVIVAL = t (ALL); ! t is the variable that contains time-to-event information TIMECENSORED = tc (0 = NOT 1 = RIGHT); ! Information about right censoring ANALYSIS: BASEHAZARD = OFF; ! Non-parametric baseline hazard function is used MODEL: t ON x;
Mplus Syntax – Example 6.19 TITLE: this is an example of a discrete-time survival analysis DATA: FILE IS ex6.19.dat; VARIABLE: NAMES ARE u1-u4 x; CATEGORICAL = u1-u4; MISSING = ALL (999); ANALYSIS: ESTIMATOR = MLR; MODEL: f BY u1-u4@1; ! This represents a proportional odds assumption where the covariate x has the same influence on u1-u4 f ON x; f@0; ! Residual variance is fixed at zero (default)
Title: YTP project Data: file = "C:\Users\cl396\Documents\Research Work\Taiwanese Work\USU\TYP\TEST_SURVIVALDAT.dat"; Variable: names are confirm indthk respect harmony ID urban SUBURBAN AGE gender income pedu relation ASSESSNE DEP1 DEP2 DEP3 DEP4 DEP5 p1-p5 class; missing are all (-9999); usevariables are gender income peduurban relation confirm indthk respect harmony dep1-dep5; categoricalare dep1-dep5; DSURVIVAL= dep1-dep5; Analysis: estimator = MLR; starts = 1000 250; optseed=476295; processors=8 (starts); Model: f by dep1-dep5@1; f on gender income pedu urban relation confirm indthk respect harmony; f@0; Output: tech1 RESIDUAL; Plot: type is plot2;
Background • The purpose of this study was to identify patterns of cultural values among Taiwanese youth and explore the relationship of these value affiliations with emerging depressive symptoms at later time points. • Previous studies showed for Taiwanese youth, the well-being issue is of particular significance due to competitive educational environment” (Yi, Wu, Wu , Chang & Chang, 2009, p. 399).” • However, others have shown that there was no difference with the prevalence of depression between a Chinese and a U.S. sample (Chen, Rubin, Li, 1995; Stewart et al, 2002). • Academic strain is a cultural norm and therefore does not necessary lead to increased depressive symptoms
Cultural Values • Social Conformity—meeting parental (scholastic) expectations • Fail to meet parental academic expectations, family tension, which has been linked with depressive symptoms may increase. • Interdependent thinking—receiving parental approval before making important decisions • Western literature generally suggests that individuals are more likely to feel depressed when they perceive constraints restricting them from reaching a desire outcome or exerting undue influence on important, personal decisions • Vertical obedience—conforming to the wishes of parents and authority figures • Chinese adolescents’ attitudes have shifted to the point that many believe that parents do not have absolute authority and power over them • Chinese parents, compared to western families, still exact more parental influence on their adolescent children • Harmony maintenance—being socially sensitive and self-restraining to ensure peace in relationship • From a Chinese cultural perspective, free emotional expressions, particularly negative ones, may disrupt harmony within the family dynamic
Model Results F ON Est. S.E. Est./S.E. p value (2-tailed) GENDER 0.370 0.159 2.325 0.020 INCOME 0.024 0.028 0.867 0.386 PEDU 0.022 0.054 0.414 0.679 URBAN 0.125 0.170 0.737 0.461 RELATION -0.883 0.159 -5.538 0.000 CONFIRM 0.122 0.178 0.688 0.492 INDTHK 0.086 0.180 0.477 0.633 RESPECT 0.024 0.166 0.142 0.887 HARMONY 0.247 0.178 1.390 0.164 Thresholds DEP1$1 2.949 0.832 3.542 0.000 DEP2$1 6.708 1.028 6.522 0.000 DEP3$1 4.804 0.871 5.518 0.000 DEP4$1 3.522 0.848 4.155 0.000 DEP5$1 3.607 0.874 4.128 0.000
Estimated Baseline Survival Curve for Emerging Depressive Symptoms with Covariates
Model Diagram Dep_w1 Social Conformity Dep_w2 f c Independent Thinking Dep_w3 Vertical Obedience Dep_w4 Dep_w6 Harmony Control Variables Mplus Diagram Currently Does Not Support Mixture Analysis
Estimated means of cultural values across class memberships (N = 2,458). The 5-class average latent class probabilities for the most likely latent class membership were .99, .88, .87, .82, and .80 respectively, indicating acceptable prediction of class membership.
TITLE: YTP project Data: file = "C:\Users\cl396\Desktop\LPA_5class_n.dat"; variable: names are CONFIRM INDTHK RESPECT HARMONY ID1 URBAN SUBURBAN AGE GENDER INCOME PEDU RELATION ASSESSNE DEP1_D DEP2_D DEP3_D DEP4_D DEP6_D CPROB1 CPROB2 CPROB3 CPROB4 CPROB5 kc; missing are all (-9999); usevariablesare PEDU URBAN GENDER INCOME ASSESSNE DEP1_D DEP2_D DEP3_D DEP4_D DEP6_D relation confirm indthk respect harmony CPROB1 CPROB2 CPROB3 CPROB4 CPROB5; Categorical are DEP1_D DEP2_D DEP3_D DEP4_D DEP6_D; DSURVIVAL= DEP1_D DEP2_D DEP3_D DEP4_D DEP6_D; knownclass= c1(kc=1 kc=2 kc=3 kc=4 kc=5); classes=c (5); training = CPROB1 CPROB2 CPROB3 CPROB4 CPROB5 (probabilities); Analysis: Type=mixture; Estimator = MLR; ALGORITHM = INTEGRATION; starts = 1000 250; optseed= 490123; processors=8 (starts); Model: %overall% f by DEP1_D DEP2_D DEP3_D DEP4_D DEP6_D@1; f on gender RELATION urban pedu INCOME ASSESSNE; f@0; Output: tech1 LOGRANK; Plot: type is plot2;
Logrank Outputs LOGRANK OUTPUT LOGRANK TEST FOR DEP1_D-DEP6_D COMPARING CLASS 2 AGAINST CLASS 1 Chi-Square Value 17.829 Degrees of Freedom 1 P-value 0.000
Estimated Survival Curve for Emerging Depressive Symptoms with Covariates Stratified by Class Membership
Estimated survival rate of each class membership across time points (N = 2,310). Summary Table of Chi-square Tests for Estimated Survival Rate between Each Pair of Class Membership. Note: The decreased sample size in Fig 2 is due to the missing value in control variables (e.g., family income, parental education, family relationships).
Findings • Adolescents in Class 1 (3% of the sample) consists of 42.5 % females with a mean age of 15.49 (SD = .55) and had a medium/low mean score across cultural values variables. • It is the class most likely to develop depressive. • Class 4 included 18 % of the sample, 46.7 % of whom were female, and the average age was 15.39 (SD = .50). Adolescents in this group had the highest mean scores across domains of traditional cultural values including interdependent thinking. • This Class most closely resembles that of traditional Eastern societies. • They also had the least likely chance of developing depressive symptoms over time.
Resources • http://www.ats.ucla.edu/stat/mplus/seminars/DiscreteTimeSurvival/default.htm • http://www.statmodel.com/bmuthen/masynSurvival2V31.pdf • http://www.ats.ucla.edu/stat/dae/