Download
1 / 1
10 likes | 86 Views
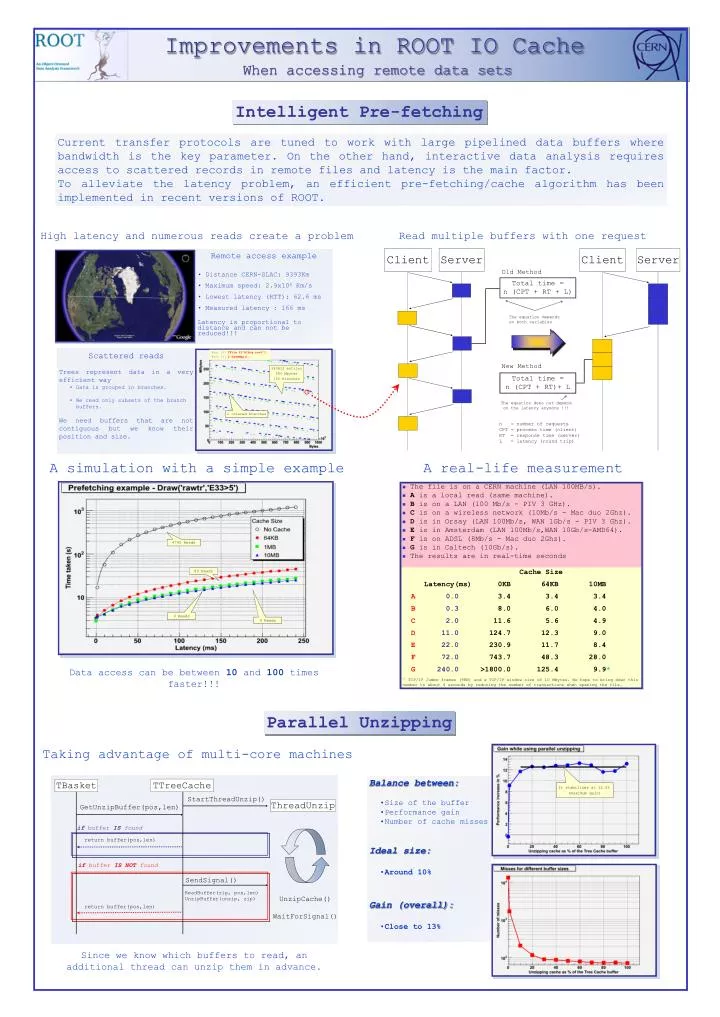
Intelligent Pre-fetching. Current transfer protocols are tuned to work with large pipelined data buffers where bandwidth is the key parameter. On the other hand, interactive data analysis requires access to scattered records in remote files and latency is the main factor.

E N D
Intelligent Pre-fetching Current transfer protocols are tuned to work with large pipelined data buffers where bandwidth is the key parameter. On the other hand, interactive data analysis requires access to scattered records in remote files and latency is the main factor. To alleviate the latency problem, an efficient pre-fetching/cache algorithm has been implemented in recent versions of ROOT. High latency and numerous reads create a problem Read multiple buffers with one request Client Server Client Server • Remote access example • Distance CERN-SLAC: 9393Km • Maximum speed: 2.9x106 Km/s • Lowest latency (RTT): 62.6 ms • Measured latency : 166 ms • Latency is proportional to distance and can not be reduced!!! Old Method Total time = n (CPT + RT + L) The equation depends on both variables • Scattered reads • Trees represent data in a very efficient way • Data is grouped in branches. • We read only subsets of the branch • buffers. • We need buffers that are not contiguous but we know their position and size. Root [0]TFile f("h1big.root"); Root [1]f.DrawMap(); New Method 283813 entries 280 Mbytes 152 branches Total time = n (CPT + RT)+ L The equation does not depend on the latency anymore !!! 2 colored branches n = number of requests CPT= process time (client) RT= response time (server) L = latency (round trip) A simulation with a simple example A real-life measurement • The file is on a CERN machine (LAN 100MB/s). • A is a local read (same machine). • B is on a LAN (100 Mb/s - PIV 3 GHz). • C is on a wireless network (10Mb/s - Mac duo 2Ghz). • D is in Orsay (LAN 100Mb/s, WAN 1Gb/s - PIV 3 Ghz). • E is in Amsterdam (LAN 100Mb/s,WAN 10Gb/s-AMD64). • F is on ADSL (8Mb/s - Mac duo 2Ghz). • G is in Caltech (10Gb/s). • The results are in real-time seconds 4795 Reads Cache Size Latency(ms) 0KB 64KB 10MB A 0.0 3.4 3.4 3.4 B0.3 8.0 6.0 4.0 C2.0 11.6 5.6 4.9 D 11.0 124.7 12.3 9.0 E 22.0 230.9 11.7 8.4 F72.0 743.7 48.3 28.0 G 240.0 >1800.0 125.4 9.9* * TCP/IP Jumbo frames (9KB) and a TCP/IP window size of 10 Mbytes. We hope to bring down this number to about 4 seconds by reducing the number of transactions when opening the file. 89 Reads 9 Reads 4 Reads Data access can be between 10 and 100 times faster!!! Parallel Unzipping Taking advantage of multi-core machines • Balance between: • Size of the buffer • Performance gain • Number of cache misses • Ideal size: • Around 10% • Gain (overall): • Close to 13% TTreeCache TBasket It stabilizes at 12.5% (maximum gain) StartThreadUnzip() ThreadUnzip GetUnzipBuffer(pos,len) ifbufferIS found return buffer(pos,len) ifbufferIS NOT found SendSignal() ReadBuffer(zip, pos,len) UnzipBuffer(unzip, zip) UnzipCache() WaitForSignal() return buffer(pos,len) Since we know which buffers to read, an additional thread can unzip them in advance.



















