Download

1 / 20
200 likes | 305 Views
Towards More Accurate Retrieval of Duplicat e Bug Reports. A08 Software Maintenance I 筑波大学 北川データ工学研究室 中村 高士. 背景. Bug Tracking System ( BTS ) バグの報告,追跡に利用される 同一バグに対するレポートであるか人間が判別 最初のレポートを master, 他を duplicate とする 類似 するレポートの候補を提示 すること で 重複レポートの判別 を 支援. 同一バグレポート検索の流れ. 本論文より引用.

E N D
Towards More Accurate Retrieval of Duplicate Bug Reports A08 Software Maintenance I 筑波大学 北川データ工学研究室 中村 高士
背景 • Bug Tracking System(BTS) • バグの報告,追跡に利用される • 同一バグに対するレポートであるか人間が判別 • 最初のレポートをmaster, 他をduplicateとする • 類似するレポートの候補を提示することで重複レポートの判別を支援
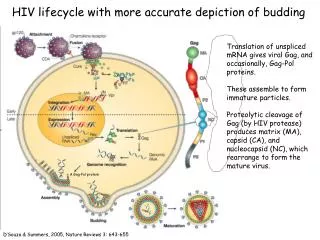
同一バグレポート検索の流れ 本論文より引用 Similarity Measureの改善
手法の概要 • 文書検索モデル を提案 • (単語集合を用いた検索モデル)を拡張 • 長いクエリに対応した文書検索モデル • クエリ内における単語の局所的重みを考慮 • レポート同士の関連度推定関数を提案 • テキスト情報だけでなくその他の情報も利用 • 内のパラメータを最適化 • Gradient descent(最速降下法)を利用
評価 • と, 既存手法とを比較 • OpenOffice, Mozilla, Eclipse のバグリポジトリを対象 • 古い順に200件のバグレポートを初期値として,残りのバグレポートのmasterを検索 • 評価基準 • MAP:masterが見つかった番号の逆数の平均 • Recall rate@k:k件まで表示した際にmasterが見つかったバグレポートの割合 • 結果 • 提案手法を用いることでMAP, Recall rate@kが改善
A Topic-based Approach forNarrowing the Search SpaceofBuggyFiles from a Bug Report Anh Tuan Nguyen Tung Thanh Nguyen Al-Kofahi, J. Hung Viet Nguyen Nguyen, T.N.
概要 • バグレポートに対する defect localization の手法を提案 • 修正すべきファイルを推定する • LDA(Latent Dirichlet Allocation) に基づいている • キーアイデア • バグレポートには,欠陥自体の説明と,欠陥に関連する機能の両方が記述されている • LDAの文書生成モデルを拡張し,ソースファイルとバグレポートの性質を表現する • 新しく届いたバグレポートのトピックを推定し,関連するファイルを推薦する
バグレポートの例 Bug Report #50900 Summary: Error saving state returned from update of external object; incomingsync will not be triggered. Description: This showed up in the server log. It’s not clear which interop component this belongs to so I just picked one of them. Seems like the code run in this scheduled task should be able to properly handle a stale data by refetching/retrying. Figure 1: Bug report #50900 InteropService.java // Implementation of the Interop service interface. // Fetch the latest state of the proxy // Fetch the latest state of the sync rule // Only return data from last synchronizedstate (後略) 欠陥自体の記述ではなく 関連する記述で つながっている Figure 2: Source File InteropService.java 出典: A. T. Nguyen et al., “A Topic-based Approach for Narrowing the Search Spaceof BuggyFiles from a Bug Report”, ASE2012
ソースファイルおよびバグレポートのトピックモデル (文書生成モデル) • S-Model: ソースファイルを,LDAでトピックモデリング • B-Model: バグレポートを,関連するソースファイルのトピックを取り込んだ形でモデリング(右図) 修正されたソースコードのトピック分布 出典: A. T. Nguyen et al., “A Topic-based Approach for Narrowing the Search Spaceof BuggyFiles from a Bug Report”, ASE2012
提案ツール BugScout • 過去のバグレポートと修正を使って,モデルを構築 • 新しく届いたバグレポート b に対して,ソースファイルとの類似度 sim(s,b) を計算する • sim(s, b) は,トピック分布 θ のコサイン類似度 • 類似度 sim(s,b) と defect-proneness P(s) で,relevance measureP(s|b) を定義 • P(s|b) = P(s) * sim(s,b) • 実装では,P(s)に,過去のバグ発見数をサイズで割ったものを使用
実験結果 • IBM Jazz, Eclipse, AspectJ, ArgoUML の4プロジェクトに対して提案手法を適用 • 比較対象 • SVM-based[19], LDA+VSM[12]
実験結果 • 提案手法が常に最上位 • 上位1件で30%の適合率の事例 • 上位10件では全てのデータセットで30%超 出典: A. T. Nguyen et al., “A Topic-based Approach for Narrowing the Search Spaceof BuggyFiles from a Bug Report”, ASE2012
Specifying and DetectingMeaningful Changes in Programs Yijun Yu Thein Than Tun Nuseibeh, B.
概要 • 人間が読むための,構造レベルの差分検出手法を提案. • 利用者がカスタマイズ可能なのが売り. • どんな差分を見たいかは人によって違う • 字面の違い?APIの変化? • 実行上の意味のない変更 (例: 修飾子の順序が変わった) を無視したい • インデントの変更などの,コード整形は無視したい • キーアイデア • 構文木を正規化 (抽象化) する • 正規化後の構文木に対して差分検出を行う
Motivating Example 行ベースの diff では,意味のある変更を取り出すのは困難! 出典: Y. Yu et al., “Specifying and DetectingMeaningful Changes in Programs”, ASE2012
他の差分検出手法は? • いろいろ提案されている • syntaxdiff, semantic diff …… • 固定的な基準で差分検出を行うか,カスタマイズできるものでも十分でない → 利用者が柔軟に設定できる差分検出手法が必要!
提案手法 • 構文木を正規化 (抽象化) する • 操作は3種類 • 特定の要素を捨てたり,(Ignore) • 並び順を無視したり,(Order) • 別の要素に置き換える (Prefer) • 操作によって構文エラーにならないよう,注意してルールを作成する • 正規化後の構文木から,クローン検出ツール NiCAD[11] を用いて差分を検出
提案手法の実装mct • 構文木の操作をメタ構文上で行えるツールTXL [10] 上に実装 • 3つの変換操作は,TXL上の言語で実装 • mctの利用者は,構文要素のクラスに対して,アノテーションをつけることで,変換操作を実現できる
事例 (Java の API 抽出) • TXL純正のJava5構文に注釈を加えて作成 • インポート文を無視(l.3) • クラスの直下の要素や (l.5)メソッドの修飾子 (l.6) を並び換えて正規化 • プライベートなメソッドを無視 (l.5, l.9) • メソッドボディをセミコロンに置き換えて正規化 (l. 7) 出典: Y. Yu et al., “Specifying and DetectingMeaningful Changes in Programs”, ASE2012
実験 • 比較対象 • 単なる diff(ldiff?) • 正規化 + diff • 提案手法 mct(正規化 + 構文クローン検出) • データセット • UART16650, JHotDraw, GMF (Eclipse) • 結果 • API変更の抽出ルールが正しく動作した • 実行時間は diff << mct<ldiff(Fig. 5) • 正規化はほとんど時間を消費していないので, NiCADを用いた差分検出が遅いと思われる.