Download
1 / 12
120 likes | 237 Views
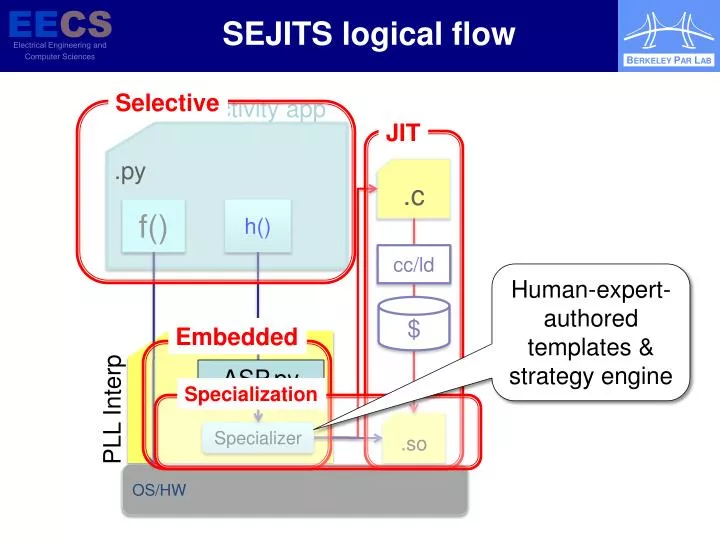
SEJITS logical flow. Selective. Productivity app. .py. JIT. Embedded. .c. Specialization. f(). h(). cc/ld. Human-expert-authored templates & strategy engine. $. PLL Interp. ASP.py. .so. Specializer. OS/HW. SEJITS logical flow. Productivity app. .py. .c. f(). h(). cc/ld. $.

E N D
SEJITS logical flow Selective Productivity app .py JIT Embedded .c Specialization f() h() cc/ld Human-expert-authored templates & strategy engine $ PLL Interp ASP.py .so Specializer OS/HW
SEJITS logical flow Productivity app .py .c f() h() cc/ld $ PLL Interp ASP.py AspDB .so Specializer OS/HW
Stencil example: input • Sum the distance-1 neighbors in a 2D stencil • from stencil_kernel import * import stencil_grid import numpy class ExampleKernel(object): def kernel(self, in_grid, out_grid): for x in out_grid.interior_points(): for y in in_grid.neighbors(x, 1): out_grid[x] = out_grid[x] + in_grid[y] in_grid = StencilGrid([5,5]) • in_grid.data = numpy.ones([5,5]) out_grid = StencilGrid([5,5]) ExampleKernel().kernel(in_grid, out_grid)
Stencil kernel example: unoptimized sequential C++ #include <boost/python.hpp> #include "arrayobject.h" namespaceprivate_namespace_000 { voidkernel(PyObject *in_grid, PyObject*out_grid) { for (inti = 1;i < 4; i++) { for (intj = 1;j < 4; j++) { #define _out_grid_array_macro(_d0,_d1) ((_d1) + 5 * (_d0)) #define _in_grid_array_macro(_d0,_d1) ((_d1) + 5 * (_d0)) double* _my_out_grid= (double *) PyArray_DATA(out_grid); double* _my_in_grid= (double *) PyArray_DATA(in_grid); intidxout = _out_grid_array_macro(i,j); intidxin = _in_grid_array_macro(i+1,j); _my_out_grid[idxout] = (_my_out_grid[idxout] + _my_in_grid[idxin]); idxin = _in_grid_array_macro(i-1,j); _my_out_grid[idxout] = (_my_out_grid[idxout] + _my_in_grid[idxin]); idxin = _in_grid_array_macro(i,j+1); _my_out_grid[idxout] = (_my_out_grid[idxout] + _my_in_grid[idxin]); idxin = _in_grid_array_macro(i,j-1); _my_out_grid[idxout] = (_my_out_grid[idxout] + _my_in_grid[idxin]); } } } } Specialized to dimensions of input data Kernel function lowered from Python to C++ Neighbor iterator expanded
C++ with loop unrolling by 4 void kernel_unroll_4(PyObject *in_grid, PyObject *out_grid) { for (int _EwzZcfet = 1; (_EwzZcfet <= 256); _EwzZcfet = (_EwzZcfet + 1)) cilk_for (int _HmEYIyVk = 1; (_HmEYIyVk <= 256); _HmEYIyVk += 1) for (int _QXalOpkr = 1; (_QXalOpkr <= 256); _QXalOpkr = (_QXalOpkr + 4)) { #define _out_grid_array_macro(_d0,_d1,_d2) (((_d2) + 258 * (_d1)) + 258 * (_d0)) #define _in_grid_array_macro(_d0,_d1,_d2) (((_d2) + 258 * (_d1)) + 258 * (_d0)) double* _my_out_grid = (double *) PyArray_DATA(out_grid); double* _my_in_grid = (double *) PyArray_DATA(in_grid);; int x; x = _in_grid_array_macro(_EwzZcfet, _HmEYIyVk, _QXalOpkr); { int y; y = _in_grid_array_macro((_EwzZcfet + 1), (_HmEYIyVk + 0), (_QXalOpkr + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + -1), (_HmEYIyVk + 0), (_QXalOpkr + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 1), (_QXalOpkr + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + -1), (_QXalOpkr + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), (_QXalOpkr + 1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), (_QXalOpkr + -1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); } x = _in_grid_array_macro(_EwzZcfet, _HmEYIyVk, (_QXalOpkr+1)); { int y; y = _in_grid_array_macro((_EwzZcfet + 1), (_HmEYIyVk + 0), ((_QXalOpkr+1) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + -1), (_HmEYIyVk + 0), ((_QXalOpkr+1) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 1), ((_QXalOpkr+1) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + -1), ((_QXalOpkr+1) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), ((_QXalOpkr+1) + 1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), ((_QXalOpkr+1) + -1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); } x = _in_grid_array_macro(_EwzZcfet, _HmEYIyVk, (_QXalOpkr+2)); { int y; y = _in_grid_array_macro((_EwzZcfet + 1), (_HmEYIyVk + 0), ((_QXalOpkr+2) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + -1), (_HmEYIyVk + 0), ((_QXalOpkr+2) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 1), ((_QXalOpkr+2) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + -1), ((_QXalOpkr+2) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), ((_QXalOpkr+2) + 1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), ((_QXalOpkr+2) + -1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); } x = _in_grid_array_macro(_EwzZcfet, _HmEYIyVk, (_QXalOpkr+3)); { int y; y = _in_grid_array_macro((_EwzZcfet + 1), (_HmEYIyVk + 0), ((_QXalOpkr+3) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + -1), (_HmEYIyVk + 0), ((_QXalOpkr+3) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 1), ((_QXalOpkr+3) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + -1), ((_QXalOpkr+3) + 0)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), ((_QXalOpkr+3) + 1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); y = _in_grid_array_macro((_EwzZcfet + 0), (_HmEYIyVk + 0), ((_QXalOpkr+3) + -1)); _my_out_grid[x] = (_my_out_grid[x] + ((1.0 / 6.0) * _my_in_grid[y])); } } }
Fully optimized, parallel C++ int c2; for (c2=chunkOffset_2;c2<=255;c2+=256) { int c1; for (c1=chunkOffset_1;c1<=255;c1+=8) { int c0; for (c0=chunkOffset_0;c0<=255;c0+=256) { int b2; for (b2=c2 + threadOffset_2;b2<=c2 + 255;b2+=256) { int b1; for (b1=c1 + threadOffset_1;b1<=c1 + 7;b1+=8) { int b0; for (b0=c0 + threadOffset_0;b0<=c0 + 255;b0+=256) { int k; for (k=b2 + 1;k<=b2 + 256;k+=2) { int j; for (j=b1 + 1;j<=b1 + 8;j+=2) { int i; for (i=b0 + 1;i<=b0 + 256;i+=8) { Anext[_Anext_Index(i - 1,j - 1,k - 1)] = fac * A0[_A0_Index(i - 1,j - 1,k - 1)] + fac2 * (A0[_A0_Index(i,j - 1,k - 1)] + A0[_A0_Index(i - 2,j - 1,k - 1)] + A0[_A0_Index(i - 1,j,k - 1)] + A0[_A0_Index(i - 1,j - 2,k - 1)] + A0[_A0_Index(i - 1,j - 1,k)] + A0[_A0_Index(i - 1,j - 1,k - 2)]); Anext[_Anext_Index(i,j - 1,k - 1)] = fac * A0[_A0_Index(i,j - 1,k - 1)] + fac2 * (A0[_A0_Index(i + 1,j - 1,k - 1)] + A0[_A0_Index(i - 1,j - 1,k - 1)] + A0[_A0_Index(i,j,k - 1)] + A0[_A0_Index(i,j - 2,k - 1)] + A0[_A0_Index(i,j - 1,k)] + A0[_A0_Index(i,j - 1,k - 2)]); Anext[_Anext_Index(i + 1,j - 1,k - 1)] = fac * A0[_A0_Index(i + 1,j - 1,k - 1)] + fac2 * (A0[_A0_Index(i + 2,j - 1,k - 1)] + A0[_A0_Index(i,j - 1,k - 1)] + A0[_A0_Index(i + 1,j,k - 1)] + A0[_A0_Index(i + 1,j - 2,k - 1)] + A0[_A0_Index(i + 1,j - 1,k)] + A0[_A0_Index(i + 1,j - 1,k - 2)]); Anext[_Anext_Index(i + 2,j - 1,k - 1)] = fac * A0[_A0_Index(i + 2,j - 1,k - 1)] + fac2 * (A0[_A0_Index(i + 3,j - 1,k - 1)] + A0[_A0_Index(i + 1,j - 1,k - 1)] + A0[_A0_Index(i + 2,j,k - 1)] + A0[_A0_Index(i + 2,j - 2,k - 1)] + A0[_A0_Index(i + 2,j - 1,k)] + A0[_A0_Index(i + 2,j - 1,k - 2)]); . . . . . . . . . . . . . ~70 similar lines . . . . . . . . . . . . } } } } } } } } }
Phase 1:Python AST => Domain AST def kernel(self, in_grid, out_grid): for x in out_grid.interior_points(): for y in in_grid.neighbors(x, 1): out_grid[x] = out_grid[x] + in_grid[y] defvisit_for(self, node): if (node.isFunctionCall("interior_points")): grid = self.visit(node.iter.func.value).id body = map(self.visit, node.body) target = self.visit(node.target) newnode = StencilKernel.StencilInterior(grid, body, target) return newnode … • Visit each AST node of Python call to specializer (available via Python’s introspection) • Convert calls to interior_pointsandneighborsto domain-specific, target-independent AST nodes for later processing • Note use of Python in manipulating/traversing AST
AST phase 1 Generic => Domain-Specific For x StencilInterior out_grid, x iter for x in out_grid.interior_points Call interior_points For y StencilNeighbor in_grid, y, 1 for y in in_grid.neighbors iter Call neighbors(x,1) := := out_grid[x] + out_grid[x] + out_grid[x] = out_grid[x] + in_grid[y] out_grid[x] in_grid[y] out_grid[x] in_grid[y]
AST phase 2: Optimize DAST For ( i over GridSize) StencilInterior out_grid, x For ( j over GridSize) LoopUnroller().unroll(node, factor) Unrolled Neighbor Loop StencilNeighbor in_grid, y, 1 Initialize variables := := := := := + + + + … … … … out_grid[x] + … … … … … … … … out_grid[x] in_grid[y] out_grid[x] = out_grid[x] + in_grid[y]
AST phase 3 & 4: bind platform, generate/compile/cache code For ( i over GridSize) CilkFor(...) • Transform to platform-specific AST (PAST) • optimizations can be reused across "similar" platforms (eg, SIMDize generically, let compiler map onto ISA) For ( j over GridSize) CilkFor(...) Unrolled Neighbor Loop block scope { ... } Initialize variables Initialize variables := := := := := := := :=
Who writes what App author (PLL) Specializer author (ELL) SEJITSteam 3rd partylibrary Application ASP core CodePy Specializer Python AST Kernel Kernel call Input data Utilities TargetAST Compiled module ASP Module Kernel call Cache hit