Download

1 / 0
0 likes | 81 Views
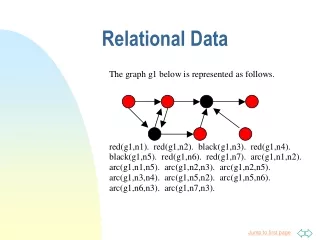
Pseudo-Likelihood for Relational Data. Oliver Schulte School of Computing Science Simon Fraser University Vancouver, Canada To appear at SIAM SDM conference on data mining. The Main Topic. In relational data, units are interdependent no product likelihood function for model.

E N D