Download
1 / 15
150 likes | 272 Views
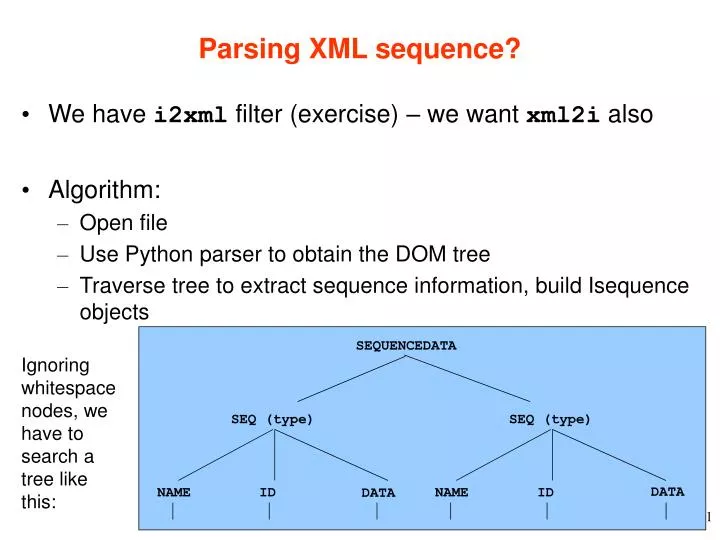
Parsing XML sequence?. We have i2xml filter (exercise) – we want xml2i also Algorithm: Open file Use Python parser to obtain the DOM tree Traverse tree to extract sequence information, build Isequence objects. SEQUENCEDATA. Ignoring whitespace nodes, we have to search a tree like this:.

E N D
Parsing XML sequence? • We have i2xml filter (exercise) – we want xml2i also • Algorithm: • Open file • Use Python parser to obtain the DOM tree • Traverse tree to extract sequence information, build Isequence objects SEQUENCEDATA Ignoring whitespace nodes, we have to search a tree like this: SEQ (type) SEQ (type) DATA NAME ID NAME ID DATA
We're still being systematic: Usual name for parse method Obtain a parse tree with the xml data for free xml2i.py (part 1) Convert this SEQ subtree to an Isequence object SEQUENCEDATA SEQ (type) SEQ (type)
Way of getting to all attributes of a node Way of getting to the value of a specific attribute xml2i.py (part 2) Recall: text kept in a #text node underneath SEQ (type) NAME ID DATA #text ..
What if the XML sequence format changes? • Now the name of the finder of the sequence is stored as a new tag: SEQUENCEDATA SEQ (type) SEQ (type) DATA NAME FOUNDBY FOUNDBY NAME ID ID DATA
Robustness of XML format • Our xml2i filter still works because the DOM parser still works • Can’t extract the finder information: ignores the foundby node: • But: doesn’t crash! Still extracts other information • Easy to update filter to incorporate new info NB: can also read old format SEQ (type) DATA FOUNDBY NAME ID
Compare with extending Fasta format Say that the Fasta format is modified so the finder appears in the second line after a >: >HSBGPG Human gene for bone gla protein (BGP) >BiRC CGAGACGGCGCGCGTCCCCTTCGGAGGCGCGGCGCTCTATTACGCGCGATCGACCC .. Our Fasta parser would go wrong!
XML robust • So, the good thing about XML is that it is robust because of its well-defined structure • Widely used, i.e. this overall tag structure won’t change and other applications can read your XML data • Parser available in Python already: • Read XML into a DOM tree • DOM tree can be traversed but also manipulated (see next slide)
See all the methods and attributes of a DOM tree on pages 537ff Possible to manipulate the DOM tree using these methods (add new nodes, remove nodes, set attributes etc.)
Convert old format XML sequence to new format SEQUENCEDATA Old format: sequence type has its own tag TYPE SEQ TYPE NAME ID DATA SEQUENCEDATA New format: sequence type is attribute of SEQ tag SEQ (type) NAME ID DATA
Add new method to original xml2i.py and call it after parsing the XML file old_xml2i.py
Import new module old_xml2phylip.py Check that type information is saved in the Isequence (not used in phylip format)
Testing on old format XML sequence <?xml version = "1.0"?> <SEQUENCEDATA> <TYPE>dna</TYPE> <SEQ> <NAME>Aspergillus awamori</NAME> <ID>U03518</ID> <DATA>aacctgcggaaggatcattaccgagtgcgggtcctttgggcccaacctcccatccgtgtctattgtaccctgttgcttcggcgggcccgccgcttgtcggccgccgggggggcgcctctgccccccgggcccgtgcccgccggagaccccaacacgaacactgtctgaaagcgtgcagtctgagttgattgaatgcaatcagttaaaactttcaacaatggatctcttggttccggc</DATA> </SEQ> </SEQUENCEDATA> U03518b.xml python old_xml2phylip.py U03518b.xml U03518b sequence is of type dna
Remark: book uses old version of DOM parser • XML examples in book won’t work (except the revised fig16.04) • Look in the presented example programs to see what you have to import • All the methods and attributes of a DOM tree on pages 537ff are the same
About Newick trees 20.59 Tree format: (monkey:100.85,cat:47.14):20.59; 47.14 100.85 cat monkey