Download
1 / 13
0 likes | 13 Views
Explore federated learning, a privacy-focused AI that trains models across devices without sharing data, enhancing security and collaboration.<br>https://www.leewayhertz.com/federated-learning/

E N D
Federated learning: Unlocking the potential of secure, distributed AI leewayhertz.com/federated-learning/ In the rapidly advancing realm of Artificial Intelligence (AI), the sophistication of our daily digital companions—ranging from spam filters to chatbots and personalized recommendation engines—is fundamentally powered by data. These AI innovations have traditionally been fueled by centralized repositories of vast data sets harvested online or donated by users. However, a paradigm shift is underway within AI, steering towards a decentralized methodology that harnesses the collective strength of distributed data. Federated learning stands at the forefront of this shift, enabling AI models to be trained on the very devices that fill our pockets and homes—mobile phones, laptops, and private servers. This approach ensures that personal data remains local, thereby safeguarding privacy and adhering to strict regulatory standards on data management. Federated learning is not just a response to privacy concerns; it explores the wealth of untapped data. It processes information where it originates, leveraging the latent power of data streams from a multitude of sources, such as satellites and urban infrastructure, to the myriad of smart devices that have become integral to our domestic settings. Emergen Research reports that the federated learning market, valued at USD 112.7 million in 2022, is expected to expand at a compound annual growth rate of 10.5% in the coming years. This article delves into the core of federated learning, examining its operational principles, its diverse applications, and the significant benefits it offers. 1/13
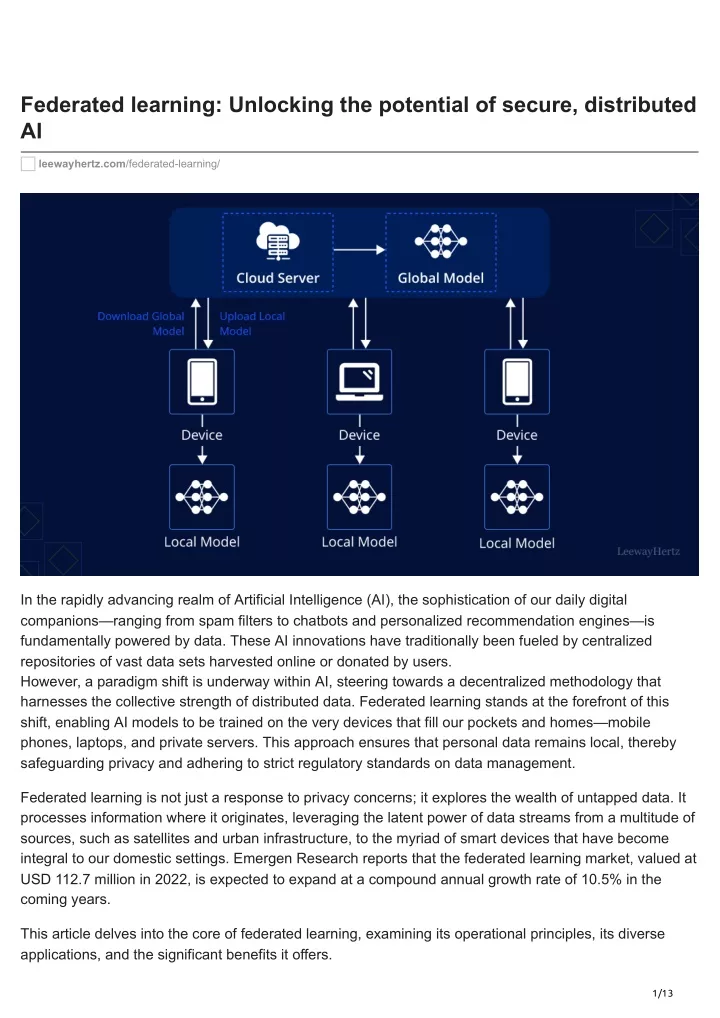
What is federated learning? How does federated learning work? How can we enhance data privacy in federated learning through advanced security techniques? Types of federated learning Model-centric federated learning Data-centric federated learning Algorithms used in federated learning Benefits of federated learning How to do text generation using federated learning? Use cases of federated learning What is federated learning? Federated learning is a machine learning technique that enables multiple client devices to collaboratively train a shared model without exchanging individual data with each other or a central server. This approach allows training to occur locally on client devices, upholding the principles of data decentralization and privacy. The essence of federated learning lies in harnessing the collective knowledge from distributed datasets across client devices rather than aggregating data in a single repository. This methodology not only addresses data privacy and security concerns but also circumvents the challenges associated with transferring large volumes of sensitive data to a central server. By enabling models to be trained directly on client devices, federated learning takes advantage of diverse datasets reflective of various real-world scenarios and user behaviors. Such diversity bolsters the model’s ability to generalize across different conditions, enhancing its robustness and predictive performance. Federated learning fosters a form of collective intelligence through its collaborative training process. Local models on client devices contribute to refining the global model, facilitating a shared learning experience while preserving the privacy of each client’s data. This technique is invaluable in contexts where privacy is paramount, including healthcare and any domain dealing with sensitive user information. Federated learning thus represents an optimal trade-off, maximizing the utility of shared learning experiences while safeguarding individual data sovereignty and privacy. How does federated learning work? Federated learning aims to train a unified model using data from multiple sources without the need to exchange the data itself. Below is a streamlined explanation of the federated learning process: Initialization of a baseline model by a central server: The process begins with a central server initializing a baseline model. This initial model embodies a generic set of knowledge, serving as the foundational framework. 2/13
The participation of devices (nodes or clients): The devices, like smartphones or computers, each containing their own data, participate as nodes or clients. These clients prioritize privacy and choose not to share their data. Local training: Each client device independently trains the baseline model using its unique local data. For instance, a smartphone may utilize data from user interactions like photos or text messages to enhance the model’s knowledge, thus personalizing it based on individual usage. Model updates: After local training, the client devices send their updated model parameters or weights back to the central server. These updated parameters capture the knowledge gained from training on the local data. Secure aggregation: The central server uses secure aggregation techniques to combine and average the model updates received from multiple client devices. This process ensures that the privacy of the individual data sources is maintained. By aggregating the updates, the central model gains insights from diverse sources of data. Iterative improvement of thecentral model: The central server then incorporates the aggregated updates into the central model, making it more refined and knowledgeable. The model learns from the collective intelligence of all the client devices. Model distribution: The updated central model is then shared again with the client devices. The client devices receive the improved model, which captures the combined knowledge from the entire federated learning process. Iterative process: The cycle of local training, model parameter updates, aggregation, and model distribution is repeated over multiple rounds. With each iteration, the models on the client devices become more personalized, and the central model becomes more generalized and accurate. The process continues, benefiting from collective intelligence while preserving privacy. Federated learning enables collaborative model training across multiple devices while keeping the data decentralized and protecting user privacy. It allows for personalized models on individual devices and a central model that captures collective knowledge without sharing raw data. 3/13
Central Server Updated Model Trained Model Base Model Local Training Local Training Local Training Client 1 Client 2 Client 3 LeewayHertz Build your AI model with LeewayHertz! We understand the risks associated with centralized model training. Hence, undertake decentralized training approaches like federated learning to ensure the safeguarding of sensitive data. Learn More How can we enhance data privacy in federated learning through advanced security techniques? The main advantage of federated learning is that organizations can leverage the power of AI without compromising the privacy and security of sensitive data. Keeping data within their secure premises significantly reduces the risk of data breaches or unauthorized access. Privacy in federated learning can be classified into two aspects: Local privacy It protects the privacy of local data at an individual level by sharing model updates instead of raw data. Global privacy It ensures that the model updates made during each round remain private and inaccessible to third parties, except for the central server. 4/13
Various techniques are employed for privacy in federated learning; they are: Differential privacy: Differential privacy is a critical technique in federated learning, where individual devices or clients train models on their local data without sharing the raw data. To ensure privacy, differential privacy can be applied by introducing random noise to the model updates before they are shared with the central server. This prevents the re-identification of specific data points and provides privacy for participants. By incorporating differential privacy in federated learning, organizations can strike a balance between data privacy and model accuracy. Homomorphic encryption: Homomorphic encryption enables secure computation on encrypted data. In the context of federated learning, homomorphic encryption allows data to remain encrypted while being processed by local devices. This means that the central server can perform operations on the encrypted model updates without decrypting the underlying data. By utilizing homomorphic encryption, federated learning can ensure end-to-end data privacy, as the sensitive information remains protected even during the model aggregation process. Secure Multiparty Computation (SMC): It plays a crucial role in preserving privacy in federated learning. By utilizing SMC, numerous devices or clients can work together to train a shared model without revealing their individual data to one another or the central server. This approach ensures that computations are distributed, enabling each client to contribute its model updates securely. SMC effectively prevents the disclosure of sensitive information and upholds the privacy of individual data throughout the federated learning cycle. Differential privacy, homomorphic encryption, and secure multiparty computation can be employed in conjunction with federated learning to strengthen privacy preservation at various stages of the learning process. By leveraging these techniques, federated learning enhances privacy and security, allowing organizations to collaboratively train models on decentralized data without compromising the confidentiality of the underlying information. Types of federated learning Federated learning encompasses two fundamental types: Model-centric and Data-centric. Model-centric federated learning is currently more prevalent and widely adopted. Let’s delve into this approach to gain a deeper understanding. Model-centric federated learning Model-centric federated learning prioritizes the development and enhancement of the machine learning model across decentralized data sources. It involves iterative experimentation to determine the most effective model architecture and training algorithms. In this approach, the emphasis is on refining the model’s code or architecture to boost its performance rather than altering the underlying data. The core goal is to advance the model’s capabilities through codebase enhancements, ensuring that the model can learn effectively from the distributed and varied datasets in a federated learning network. We will now explore the methodologies and practices that define model-centric federated learning: 5/13
Cross-device federated learning Cross-device federated learning is a privacy-centric machine learning approach that enables a multitude of devices to collaboratively enhance a shared model while keeping their raw data private, not sharing it with a central server or amongst themselves. This method integrates the principles of federated learning with the ability to perform distributed training across a diverse array of devices. Unlike traditional setups, where a central server dispatches model updates to devices that then use their local data to compute and return updates, cross-device federated learning maintains a central server for coordination but does not require direct data exchange between devices. The primary aim is to harness the rich diversity of data across devices to refine the model’s effectiveness. Each device contributes by training on its own data and sharing model updates, which are then aggregated by the central server. Through this process, a more comprehensive and generalized model emerges, benefitting from the collective insights gathered across the various participating devices. Horizontal federated learning Horizontal federated learning, also known as sample-based federated learning or homogenous federated learning, is particularly suitable when datasets share the same feature space but differ in samples. In this case, the data is horizontally split, meaning each participating device or entity has rows of data with consistent features but potentially different samples. Horizontal federated learning is where multiple entities or organizations collaborate to train a shared model while keeping their data local. Unlike vertical federated learning, which involves different entities holding different types of data that can be combined to build a more comprehensive model, horizontal federated learning focuses on scenarios where the entities hold similar types of data. In horizontal federated learning, the participating entities typically have their own local datasets, which may be similar in terms of features or data types. These entities collaboratively train a shared model by exchanging model updates while keeping their data decentralized and private. Vertical federated learning Vertical federated learning is a type of federated learning where multiple entities or organizations collaborate to train a shared model by combining different types of data that are vertically partitioned across the entities. Unlike horizontal federated learning, which focuses on similar types of data with consistent features, vertical federated learning involves different entities holding complementary and non- overlapping data attributes or features. In vertical federated learning, the data from different entities are divided based on their specific attributes or features. Each entity holds a unique subset of attributes, and by combining these subsets, a more comprehensive model can be trained. The model updates are computed locally on each entity’s data, and only the updates, rather than the raw data, are exchanged among the entities. Cross-silo federated learning 6/13
Cross-silo federated learning is a variant of federated learning involving collaboration between multiple organizations or entities, each with its own separate data silo. In this context, a data silo refers to a storage system or repository where data is isolated and accessible only to a specific organization or entity. Cross-silo federated learning aims to train a shared model by leveraging the data available in each organization’s silo without directly sharing or centralizing the data. Each organization retains control over its own data, ensuring privacy and security. Federated transfer learning Federated transfer learning represents an intriguing area of research that combines the benefits of transfer learning and federated learning techniques. Transfer learning has demonstrated its effectiveness in leveraging knowledge acquired from one supervised learning task to improve performance on a related task. In conventional transfer learning, a common approach involves fine-tuning a pre-trained network by removing the last few layers and retraining it on a smaller dataset to recognize specific labels. In contrast, federated transfer learning involves additional steps that are more complex. These steps often include intermediate learning processes that aim to map the data from distributed entities to a shared feature subspace. This mapping facilitates knowledge transfer and collaborative model training, ensuring that privacy is maintained while leveraging diverse data sources. Data-centric federated learning Data-centric federated learning is a developing approach that extends traditional federated learning principles to emphasize data ownership, privacy, and secure access. This approach resembles a peer-to- peer model where data owners grant external entities the capability to build models using their data without actually transferring the data. The philosophy behind data-centric federated learning is not limited to merely providing access to private data. It envisages a network where private, siloed data could be accessible to various organizations, fostering the creation of machine-learning models for a broad spectrum of applications. Under this paradigm, data owners maintain their data in a secure environment, enabling external data scientists to conduct training or inference on this remotely hosted data. Unlike model-centric approaches that typically rely on pre-existing models, data-centric federated learning focuses on extracting value from the data itself. Realizing the full promise of data-centric federated learning necessitates tools for efficient data discovery, wrangling, and preparation within the network, ensuring readiness for model training and inference while upholding privacy. Furthermore, employing protective measures such as differential privacy and private set intersection (PSI) is crucial for preventing data exposure, thus supporting data governance and compliance. 7/13
Navigating the complexities of automated control and meeting the diverse requirements of data handling, privacy, and compliance presents significant challenges in data-centric federated learning. Integrating automated processes with privacy-enhancing technologies like differential privacy and PSI will be critical in realizing the potential of this approach, all while maintaining stringent data security and regulatory compliance. Build your AI model with LeewayHertz! We understand the risks associated with centralized model training. Hence, undertake decentralized training approaches like federated learning to ensure the safeguarding of sensitive data. Learn More Algorithms used in federated learning Federated learning encompasses several algorithms that enable collaborative training of machine learning models in a decentralized manner. Some of the commonly used federated learning algorithms include: Federated Stochastic Gradient Descent (FedSGD) In traditional stochastic gradient descent (SGD), the computation of gradients is based on mini-batches, which are subsets of data samples drawn from the entire dataset. In the context of federated learning, these mini-batches can be viewed as individual client devices, each having access to its own local data. With Federated Stochastic Gradient Descent (FedSGD), the central model is initially distributed to all participating clients. Each client independently computes the gradients using its local data, reflecting the model’s performance on its specific dataset. These client-specific gradients are then transmitted back to the central server. At the central server, the gradients received from each client are aggregated, considering the proportion of data samples each client represents. This aggregation process ensures that clients with larger datasets contribute more significantly to calculating the gradient descent step. By considering the relative sizes of the local datasets, the central server appropriately weighs the gradients from different clients during the aggregation process. The resulting aggregated gradient updates the central model, reflecting the collective knowledge and insights gained from the distributed clients. This iterative process of distributing the model, computing gradients locally, and aggregating them at the central server continues for multiple rounds, progressively refining the global model based on the diverse datasets held by the clients. FedSGD enables collaborative training while respecting data privacy and security. It allows clients to contribute knowledge without transmitting raw data to the central server. By leveraging the distributed nature of client devices, FedSGD enables efficient and privacy-preserving model updates in the federated learning setting. 8/13
Federated Averaging (FedAvg) FedAvg is an extension of the FedSGD algorithm that introduces the concept of aggregating client model weights instead of gradients. In FedAvg, clients have the flexibility to perform multiple local gradient descent updates before sharing their model weights with the central server. This allows clients to fine- tune their local models based on their specific datasets and computation resources. Unlike FedSGD, where clients transmit gradients to the central server, FedAvg focuses on exchanging model weights. Instead of directly sharing gradients, clients send their updated model parameters (weights) to the central server. This shift from gradients to weights enables more flexibility in the training process. The central server aggregates the received model weights from the clients, typically by taking the weighted average of the models based on the size of each client’s local dataset. By averaging the client’s data weights, the central server obtains a refined global model that incorporates the knowledge contributed by each client. The key advantage of FedAvg is that it allows clients to perform multiple local updates and fine-tune their models before sharing the results with the central server. This flexibility enables clients to take advantage of their local data and computational resources, potentially improving the quality of the shared global model. Moreover, if all clients start from the same initial model, averaging the gradients is equivalent to averaging the weights, allowing for efficient aggregation and convergence. FedAvg is a powerful technique in federated learning as it strikes a balance between client-specific fine- tuning and collaborative model improvement. By combining local updates and global aggregation, FedAvg enables the collective intelligence of distributed clients to contribute to the creation of an accurate and robust global model. Federated Learning with Dynamic Regularization (FedDyn) Regularization is a fundamental technique in traditional machine learning that enhances model performance by introducing a penalty term to the loss function, encouraging model simplicity and reducing overfitting. In the federated learning context, where disparate devices train a shared model on their own data, integrating local losses into a cohesive global loss presents a unique challenge. FedDyn offers a solution by implementing dynamic regularization. Instead of applying a static regularization term, FedDyn dynamically adjusts the regularization based on the local updates from each device. This dynamic adjustment ensures that local models stay closely aligned with the global model despite the inherent differences in local data distributions. The innovation of FedDyn lies in mitigating the discrepancies between local model updates and the global objective. By customizing the regularization term for each device’s updates, FedDyn guides local models to minimize global loss collectively and more effectively. This approach facilitates a more cohesive and efficient federated learning process, yielding improved model performance across the network. Benefits of federated learning 9/13
The benefits of federated learning include: Privacy preservation: Federated learning prioritizes data privacy by keeping user data on local devices. Instead of sending raw data to a central server, model updates are shared, ensuring that sensitive information remains secure and confidential. This decentralized approach helps address privacy concerns and regulatory requirements. Data security: Federated learning minimizes the need for data transfer, limiting exposure to potential security vulnerabilities during transmission or storage. Since data remains on local devices, the risk of data breaches or unauthorized access is significantly reduced. Efficient resource utilization: Clients participate in model training using their own devices, eliminating the necessity for extensive data transfers and minimizing computational and communication costs. By leveraging local computing resources, federated learning reduces the need for massive centralized infrastructure. Collaborative learning: Federated learning enables devices like mobile phones to train a shared prediction model collectively. This collaborative approach keeps training data on the device itself, eliminating the need for data uploads to a central server. It fosters a sense of cooperation and knowledge sharing while maintaining data privacy. Time efficiency: Organizations can collaborate to address challenges in machine learning models more efficiently. For instance, highly regulated sectors like hospitals can collaboratively train life-saving models while upholding patient privacy, accelerating the development process. With federated learning, there is no need to repeatedly invest time in collecting and aggregating data from diverse sources. Build your AI model with LeewayHertz! We understand the risks associated with centralized model training. Hence, undertake decentralized training approaches like federated learning to ensure the safeguarding of sensitive data. Learn More How to do text generation using federated learning? In this section, we will leverage TensorFlow Federated (TFF) to implement federated learning on a pre- trained text generation model. The model, initially trained on Charles Dickens’s novels, will be fine-tuned using federated learning specifically for Shakespeare’s works. We’ll load the pre-trained model, generate text using it, and then proceed with the federated learning process to adapt the model to Shakespearean language patterns. Let’s embark on this journey to explore the fascinating intersection of deep learning and federated learning in natural language processing. With the help of the following codes, you can generate text using federated learning. pip install --quiet --upgrade tensorflow-federated import collections import functools 10/13
import os import time import numpy as np import tensorflow as tf import tensorflow_federated as tff np.random.seed(0) # Test that TFF is working: tff.federated_computation(lambda: 'Hello, World!')() b'Hello, World!' Load a pre-trained model Load a pre-trained model that was trained using the TensorFlow tutorial on text generation with a Recurrent Neural Network (RNN) and eager execution (Eager execution allows operations to be executed immediately as they are called, providing a more imperative and interactive interface similar to other deep learning frameworks like PyTorch or NumPy). However, instead of training it on the complete works of Shakespeare, we pre-trained the model using the text from Charles Dickens’s novels, specifically “A Tale of Two Cities” and “A Christmas Carol.” This initial model may not be state-of-the-art, but it produces reasonable predictions and is sufficient for the purposes of this tutorial. The final model was saved using the tf.keras.models.save_model(include_optimizer=False). We will employ federated learning to fine-tune this pre-trained model specifically for Shakespeare’s works. To achieve this, we will use a federated version of the data provided by the TensorFlow Federated (TFF) library. Generate the vocab lookup tables # A fixed vocabularly of ASCII chars that occur in the works of Shakespeare and Dickens: vocab = list('dhlptx@DHLPTX $(,048cgkoswCGKOSW[_#\'/37;? bfjnrvzBFJNRVZ"&*.26:\naeimquyAEIMQUY]!%)-159\r') # Creating a mapping from unique characters to indices char2idx = {u:i for i, u in enumerate(vocab)} idx2char = np.array(vocab) Load the pre-trained model and generate some text def load_model(batch_size): urls = { 1: 'https://storage.googleapis.com/tff-models-public/dickens_rnn.batch1.kerasmodel', 8: 'https://storage.googleapis.com/tff-models-public/dickens_rnn.batch8.kerasmodel'} assert batch_size in urls, 'batch_size must be in ' + str(urls.keys()) url = urls[batch_size] local_file = tf.keras.utils.get_file(os.path.basename(url), origin=url) return tf.keras.models.load_model(local_file, compile=False) 11/13
def generate_text(model, start_string): # From https://www.tensorflow.org/tutorials/sequences/text_generation num_generate = 200 input_eval = [char2idx[s] for s in start_string] input_eval = tf.expand_dims(input_eval, 0) text_generated = [] temperature = 1.0 model.reset_states() for i in range(num_generate): predictions = model(input_eval) predictions = tf.squeeze(predictions, 0) predictions = predictions / temperature predicted_id = tf.random.categorical( predictions, num_samples=1)[-1, 0].numpy() input_eval = tf.expand_dims([predicted_id], 0) text_generated.append(idx2char[predicted_id]) return (start_string + ''.join(text_generated)) # Text generation requires a batch_size=1 model. keras_model_batch1 = load_model(batch_size=1) print(generate_text(keras_model_batch1, 'What of TensorFlow Federated, you ask? ')) You can utilize the code provided in the TensorFlow article, which covers the entire process from loading the pre-trained model to implementing federated learning. Use cases of federated learning Federated learning has made significant inroads across various industries, offering privacy-preserving and collaborative training opportunities. Let’s explore some of the most common applications: Mobile applications: Federated learning is well-suited for mobile applications, enabling the enhancement of user-centric features while preserving data privacy. By processing data on the users’ devices and only exchanging model improvements, this approach allows for the advancement of personalized experiences such as tailored recommendations, adaptive keyboards, and responsive voice assistants, all without exporting personal data from the device. Transportation: Self-driving cars heavily rely on computer vision and machine learning to analyze real- time surroundings and adapt to dynamic environments. Federated learning enables these models to continuously improve and enhance precision by learning from diverse datasets. This decentralized approach enables faster learning and robust model development. Manufacturing: In manufacturing, federated learning can significantly enhance predictive analytics and operational efficiency. By utilizing data across a broad network of sensors and devices without compromising confidentiality, manufacturers can derive insights into machine performance and production processes. This can lead to improved maintenance schedules and supply chain management. While its role in product recommendation systems may not be direct, the insights gained can indirectly influence customer satisfaction and demand forecasting. Additionally, federated learning has potential applications 12/13
in AR/VR for tasks like object detection in complex assembly operations and facilitating remote assistance, contributing to the creation of sophisticated models tailored to specific manufacturing scenarios. Industrial environment monitoring: Federated learning facilitates the analysis of industrial environment factors obtained from multiple sensors and companies. By performing time-series analysis while maintaining the privacy of confidential data, federated learning enables comprehensive monitoring and optimization of industrial environments. Healthcare: The sensitive nature of healthcare data and privacy concerns make federated learning invaluable in this industry. It allows models to be trained securely on patient and medical institution data without compromising privacy. Federated learning enables collaboration among healthcare providers, enabling models to learn from diverse datasets while adhering to privacy regulations. It also empowers smaller hospitals and clinics to access advanced AI technologies, granting them insights from broader demographic areas and improving patient care. These applications represent just a snapshot of the widespread adoption and versatile applications of federated learning. Its ability to leverage decentralized data while preserving privacy opens up innovative possibilities across various industries, driving advancements in AI and machine learning. Endnote Federated learning presents a groundbreaking approach to machine learning, addressing privacy and data security challenges. By decentralizing the training process and allowing models to be trained directly on user devices, federated learning ensures the protection of sensitive user data. This decentralized form of machine learning offers significant advantages, including personalization, minimal latency, and the ability to tap into a vast array of distributed data sources. It empowers individuals to retain control over their data while contributing to model enhancement. Federated learning represents a significant step forward in the pursuit of ethical and privacy-centric AI solutions. It enables organizations to develop robust and accurate models while preserving user privacy. Despite being in its early stages and facing certain challenges, federated learning demonstrates a highly secure and collaborative approach to AI. By prioritizing privacy and data protection, federated learning paves the way for a new era of machine learning, where individuals can enjoy the benefits of AI without compromising their personal information. Implement federated learning to safeguard sensitive data while harnessing the full power of AI. Contact LeewayHertz’s experts today to break the trade-off between privacy and AI! 13/13