Download

1 / 21
220 likes | 240 Views
Data annotation is adding labels or tags to a training dataset to provide context and meaning to the data. All kinds of data, including text, images, audio and video, are annotated before being fed into an AI model. Annotated data helps machine learning models to learn and recognize patterns, make predictions, or generate insights from labeled data.

E N D
Data annotation: The key to AI model accuracy leewayhertz.com/data-annotation There has been a surge in interest and investment in Artificial Intelligence (AI) across industries. However, the success of AI initiatives depends considerably on high-quality data. Without quality data, AI algorithms cannot function effectively and can even lead to inaccurate or undesired outcomes. Hence, the discourse on AI is slowly shifting to optimizing AI solutions with high-quality data. As per Global Enterprise Data Management Market Size Report, 2030, the enterprise data management market was valued at USD 89.34 billion in 2022 and is expected to experience a compound annual growth rate (CAGR) of 12.1% from 2023 to 2030. To develop AI models that can closely emulate human behavior and make decisions or execute actions just like humans would, high volumes of high-quality training data are required. However, preparing high-quality data for training AI models requires appropriate and accurate annotation. Data annotation is a technique used to categorize and label data for AI model training. Proper data annotation ensures that AI implementations can achieve the desired performance, accuracy, and effectiveness in solving specific tasks or problems. For example, annotated data can enable computer vision-based models to identify and classify images accurately, resulting in improved visual search outcomes. Likewise, chatbots trained on accurately annotated data can understand user intents and offer more natural and intuitive interactions. 1/21
Annotated data can also enhance speech recognition systems, allowing for greater accuracy in transcribing speech and making voice-based interfaces more user-friendly. Search algorithms can better understand the user’s query context with data annotation, leading to more accurate results. This technique is also highly important for building recommendation systems, which involves training an AI model to detect consumer behavior and preference patterns to offer personalized recommendations to each user. Clearly, data annotation is vital for AI systems to successfully accomplish their intended purposes, driving a notable growth in demand for both human annotators and annotation tools. As per Data Annotation Tools Market Size Report, 2030 the value of the global data annotation tools market was USD 805.6 million in 2022, and it is predicted to increase at a compound annual growth rate (CAGR) of 26.5% from 2023 to 2030. This article offers a comprehensive overview of data annotation, encompassing its operational mechanics, types, various tools and techniques, and other pertinent aspects. What is data annotation? Types of data annotation Data annotation tools How does data annotation work? Annotation techniques How to annotate text data? Use cases of data annotation What is data annotation? Data annotation is adding labels or tags to a training dataset to provide context and meaning to the data. All kinds of data, including text, images, audio and video, are annotated before being fed into an AI model. Annotated data helps machine learning models to learn and recognize patterns, make predictions, or generate insights from labeled data. The quality and accuracy of data annotations are crucial for the performance and reliability of machine learning models. When developing an AI model, it is essential to feed data to an algorithm for analysis and generating outputs. However, for the algorithm to accurately understand the input data, data annotation is imperative. Data annotation involves precisely labeling or tagging specific parts of the data that the AI model will analyze. By providing annotations, the model can process the data more effectively, gain a comprehensive understanding of the data, and make judgments based on its accumulated knowledge. Data annotation plays a vital role in enabling AI models to interpret and utilize data efficiently, enhancing their overall performance and decision-making capabilities. Data annotation plays a crucial role in supervised learning, a type of machine learning where labeled examples are provided to train a model. In supervised learning, the model learns to make predictions or classifications based on the labeled data it receives. when fed with a larger volume of accurately annotated data, the model can learn from more 2/21
diverse and representative examples. The process of training with annotated data helps the model develop the ability to make predictions autonomously, gradually improving its performance and reducing the need for explicit guidance Virtual personal assistants, like Siri or Alexa, rely on data annotation to precisely recognize and understand commands given to them in natural language. Data annotation enables machine learning models to grasp the intent of a user’s speech or text and to enable more precise replies and actions. When a user requests a virtual assistant to “set a reminder for a doctor’s appointment on Tuesday,” data annotation enables the machine learning model to correctly identify the reminder’s date, time, and objective, enabling it to set the reminder successfully. The virtual assistant could overlook crucial information or misinterpret the user’s intent if the data is not properly annotated, resulting in mistakes and inconvenience for the user. Data annotation can take various forms depending on the type of data and the purpose at hand. For instance, image recognition may entail drawing bounding boxes around items of interest and labeling them to the appropriate object categories. Data annotation in Natural Language Processing (NLP) may involve assigning named entities, sentiment scores, or part-of-speech tags to text data. Data annotation in speech recognition may involve converting spoken words into written text. Types of data annotation Data annotation finds application in two prominent fields of AI: computer vision and natural language processing. And the choice of data annotation technique varies according to the nature of the data involved. Computer vision (CV): In computer vision, data annotation involves labeling and annotating visual elements in images, photographs, and videos to train AI models for tasks such as object recognition, facial detection, motion tracking, and autonomous driving. Annotations provide the necessary ground truth information that enables AI models to understand and interpret visual data accurately. Natural language processing (NLP): In NLP, data annotation focuses on textual information and language-related elements. It involves annotating text within images or directly processing textual data. NLP data annotation aims to train AI models to understand human speech, comprehend natural language, and perform tasks like text classification, sentiment analysis, named entity recognition, and machine translation. Annotating data can take many different shapes in CV and NLP. Let’s discuss the types of data annotation in CV and NLP. Computer vision tasks where data annotation plays a vital role Image categorization 3/21
Image annotation plays a significant role in facilitating the training of machine learning models and enhancing their capabilities for visual data analysis and decision-making. The importance of image annotation in preparing datasets for machine learning can’t be overemphasized. Image annotation involves labeling or classifying photos, providing the necessary information for machine learning models to understand and identify patterns and characteristics within the data. Various techniques such as bounding box annotation, semantic segmentation, and landmark annotation can be employed during the annotation process. By annotating photos, supervised machine learning models can be trained to make informed judgments about unseen images. This process is particularly valuable for computer vision tasks like object detection, image recognition, and facial recognition. Proper image annotation is essential to achieve high accuracy in machine learning and deep learning applications within the field of computer vision. Object recognition/detection One of the most important computer vision tasks is object recognition, which is applied in many real-world applications, such as autonomous vehicles, surveillance systems, and medical imaging. Identifying and labeling the existence, location, and number of objects in an image is known as object recognition. The objects of interest in the image can be marked using various methods, including bounding boxes, polygons, and annotation tools like CVAT, label boxes, etc. In some instances, objects of various classes can be labeled inside a single image using object recognition techniques. This enables fine-grained annotation, where distinct items with distinctive labels may be recognized and labeled individually within the same image. Object identification can be used in more complex environments like medical images, such as CT or MRI scans. Continuous or frame-by-frame annotation can be employed to mark objects or features of interest, particularly in multi-frame or time-series data. This enables machine learning models to recognize and track changes in the data over time, which can be beneficial in medical diagnosis and monitoring. Accurate object recognition and annotation are essential for building precise machine- learning models that automatically recognize and categorize items in unlabeled photos or videos. It plays a vital role in the creation of reliable computer vision systems for various applications. Segmentation Segmentation is a complex image annotation technique that involves separating an image into sections or segments and labeling them according to their visual content. Semantic segmentation, instance segmentation, and panoptic segmentation are the three most common segmentation types. 4/21
Semantic segmentation Establishing borders between related objects in an image and labeling them with the same identifier is known as semantic segmentation. It is a computer vision technique that assigns a label or category to each pixel of an image. It is commonly used to identify specific areas or objects in an image, such as vehicles, pedestrians, traffic signs, and pavement for self-driving cars. Semantic segmentation has many applications, including medical imaging and industrial inspection. It can classify an image into multiple categories and can differentiate between various classes, such as a person, sky, water, and background. Let’s consider the example of annotating photographs of a baseball game, specifically identifying players in the field and the stadium crowd. By marking the pixels corresponding to the crowd, the annotation process can separate the crowd from the field. This annotation technique enables machine learning algorithms to easily identify and differentiate between different elements present in a photo or scene. This shows how data annotation can label specific objects or regions of interest within an image or video, making it easier for machine learning algorithms to identify and differentiate between different elements in the photo or scene. Machine learning models can be trained to recognize and respond to specific objects or scenarios in a given context by providing this annotated data. Instance segmentation Instance segmentation is a more advanced version of semantic segmentation, which can differentiate between different instances of objects within an image. Unlike semantic segmentation, which groups all pixels of the same class into a single category, instance segmentation assigns unique labels to each instance of an object. For example, in an image of a street scene, instance segmentation can identify each car, pedestrian, and traffic light within the image and assign a unique label to it. Instance segmentation is a complex task that requires advanced computer vision algorithms and machine learning models. One popular approach to instance segmentation is the Mask R-CNN model, which combines object detection and semantic segmentation to accurately identify and segment individual instances of objects within an image. It has many applications in autonomous driving, robotics, and medical imaging. In autonomous driving, instance segmentation can help a self- driving car identify and track individual vehicles, pedestrians, and other objects on the road, allowing it to navigate safely and avoid collisions. In medical imaging, for instance, segmentation can identify and separate individual organs or tissue types within an MRI or CT scan, helping doctors diagnose and treat medical conditions more accurately. 5/21
Panoptic segmentation Panoptic segmentation is a computer vision task that combines both semantic segmentation and instance segmentation to produce a comprehensive understanding of an image. It aims to divide an image into semantically meaningful regions and identify every object instance within them. This means that in addition to labeling every pixel in an image with a category label, it also assigns a unique identifier to each object instance within the image. It typically involves a two-stage process. In the first stage, the image is segmented into semantic regions, similar to semantic segmentation. In the second stage, each instance within each region is identified and labeled with a unique identifier. The output of panoptic segmentation is a pixel-wise segmentation map of the image, where each pixel is labeled with a semantic category and an instance ID. Boundary recognition Image annotation for boundary recognition is essential for training machine learning models to identify patterns in unlabeled photos. Annotating lines or boundaries helps in various applications, such as identifying sidewalks, property boundaries, traffic lanes, and other artificial boundaries in images. In the development of autonomous vehicles, boundary recognition plays a crucial role in teaching machine learning models to navigate specific routes and avoid obstacles like power wires. Machines can learn to recognize and accurately follow these lines by adding boundaries to photos. Boundary recognition can also be used to establish exclusion zones or distinguish between the foreground and background in an image. For instance, in a photograph of a grocery store, you may label the boundaries of the stocked shelves and leave out the shopping lanes from the algorithmic input data. This may help narrow the analysis’ emphasis to particular areas of interest. Boundary recognition is often used in medical pictures, where annotators can mark the borders of cells or aberrant regions to help find diseases or anomalies. In video labeling, object tracking is a common type of annotation. Video annotations are somewhat similar to image annotations, but they take a greater amount of work. To begin with, a video needs to be broken up into separate frames. After that, each frame is considered a separate image, and the algorithm needs to detect objects because it enables it to establish links between frames, informing it of the objects in different frames that appear in different positions. The technique is called background subtraction or foreground detection. Background subtraction involves comparing each frame to a background model created from previous frames. Pixels significantly differing from the background model are classified as part of the foreground, representing moving objects. Background subtraction methods vary, including simple frame differencing and more sophisticated approaches that account for illumination changes and camera noise. After identifying foreground pixels, further analysis can be performed, such as tracking object motion or extracting features for object recognition and classification. 6/21
Data annotation in natural language processing In natural language processing (NLP), data annotation involves tagging text or speech data to create a labeled dataset for machine learning models. It is crucial for developing supervised NLP models for tasks like text classification, named entity recognition, sentiment analysis, and machine translation. Different types of data annotation methods are used in NLP, such as: Entity annotation This method involves annotating unstructured sentences by adding labels to entities, such as names, places, key phrases, verbs, adverbs, and more. It helps in finding, extracting, and tagging specific items within the text. This type of annotation is commonly used for chatbot training and can be customized based on specific use cases. Let’s understand this annotation technique by delving into its subsets. Named Entity Recognition (NER) Named Entity Recognition is a subset of entity annotation that entails locating and extracting particular named entities from text, such as names of people, companies, places, and other significant entities. Identifying and extracting named entities is essential for comprehending the meaning and context of the text for information extraction, sentiment analysis, and question answering.; NER is frequently employed in various NLP applications. The example sentence “John works at Redmond-based Microsoft” demonstrates the application of Named Entity Recognition (NER) for data annotation. NER is used to identify and annotate specific entities within the sentence. In this case, “John” is recognized as a person’s name, “Microsoft” as the name of an organization, and “Redmond” as a place name. By annotating these entities using NER, the sentence becomes structured, and the identified entities are labeled accordingly. Keyphrase extraction Keyphrase extraction is an entity annotation that entails finding and extracting keywords or phrases that represent the major ideas or themes in the text. Identifying keywords plays a crucial role in understanding the main ideas or context of a text. Keyphrase extraction is a technique used to extract these important keywords from the text. This application of keyphrase extraction is commonly used in tasks such as document summarization, content suggestion, and topic modeling. By extracting the keyphrases, it becomes easier to summarize the content, provide relevant suggestions, and analyze the main topics discussed in the text. For example, in the sentence, “The article discusses climate change, global warming, and its impact on the environment,” keyphrase extraction can be used to annotate the terms “climate change,” “global warming,” and “environment” in this statement. 7/21
Part-of-speech (POS) POS tagging is a type of entity annotation in which each word in a sentence has a grammatical label or tag to indicate its syntactic or grammatical role. POS tagging is a crucial activity in natural language processing (NLP) to analyze and understand the grammatical structure of phrases. This understanding is useful for many downstream NLP tasks, including parsing, named entity recognition, sentiment analysis, and translation. The POS tag represents the syntactic category or grammatical function of a word in a sentence, such as a noun, verb, adverb, adjective, preposition, conjunction and pronoun. POS tags are intended to clarify definitions and provide context for words used in sentences by indicating a sentence’s subject, object, or verb. POS tags are often assigned depending on a word’s meaning, where it appears in the sentence, and the nearby terms. For example, in “The quick brown fox jumps over the lazy dog,” the following words and phrases could be used as POS tags: “the” (article), “quick” (adjective), “brown” (adjective), “fox” (noun), “jumps” (verb), “over” (preposition), “the” (article), “lazy” (adjective), and “dog” (noun). Entity linking Entity linking (called named entity linking or NEL) is an entity annotation technique that involves locating and connecting named entities in the text to the relevant entries in a knowledge base or database. Entity linking tries to clarify named entities in text and link them to particular entities in a knowledge base, which might offer further details and context on the named entities mentioned in the text. For example: In the sentence “Barack Obama served as the President of the United States,” entity linking would recognize “Barack Obama” as a person and link it to the appropriate entry in a knowledge base, such as a database of people, which may include more details about Barack Obama’s presidency, biographical information, and professional accomplishments. Text classification Text classification refers to the process of labeling a piece of text or a collection of lines using a single label. It is a widely used technique in various applications, including: Document categorization Document categorization, sometimes referred to as text classification, is the process of automatically classifying documents into one of several predefined groups or labels based on the content of the documents. It involves reviewing a document’s text and selecting the most relevant category or label from predefined categories. Natural language processing and machine learning are frequently used to categorize documents, and it has a wide range of real-world applications. This tool can arrange, categorize, and manage large amounts of textual content, including articles, emails, social media posts, customer reviews, and more. In fields such as journalism, e-commerce, customer service, and marketing, it can also be utilized for content suggestion, information retrieval, and content filtering. 8/21
Sentiment annotation Sentiment annotation, often called sentiment analysis or opinion mining, automatically detects and classifies the sentiment or emotional tone expressed in a given text, such as positive, negative, or neutral. It entails examining the text to ascertain the attitude of the words, phrases, or expressions used in the sentence. Natural language processing and machine learning are frequently used in sentiment annotation, which has numerous applications in customer sentiment tracking, social media monitoring, brand reputation management, market research, and customer feedback analysis. Sentiment annotation can be done at several levels, such as the document, phrase, or aspect levels, where particular qualities or aspects of a good or service are annotated with the sentiment. For example, in the text, “The movie was okay, and it had some good moments but also some boring parts,” sentiment annotations would be: “The movie was okay” – Neutral “It had some good moments” – Positive “But also some boring parts” – Negative Overall sentiment: Neutral (with mixed positive and negative sentiments) Intent annotation Intent annotation, also known as intent categorization, is figuring out and labeling the intended purpose or meaning behind a passage of text or user input. It entails classifying the text according to predetermined groups or divisions based on the desired action or request. For example, in the text “Book a flight from New York to Los Angeles for next Monday,” the intent annotation is- “Book a flight from New York to Los Angeles for next Monday” – Request for flight booking. The creation of NLP systems, including chatbots, virtual assistants, and language translation tools, frequently uses text annotation. To deliver appropriate answers or actions, these systems rely on their ability to comprehend intentions or meanings effectively. Data annotation tools A data annotation tool is a software that can be used to annotate training data for machine learning. These tools can be cloud-based, on-premise, or containerized and are available via open-source or commercial offerings for lease and purchase. They are designed to annotate specific data types, such as image, video, text, audio, spreadsheet, or sensor data. Some of the frequently used data annotation tools are: Labelbox Labelbox is a data labeling platform that offers advanced features such as AI-assisted labeling, integrated data labeling services, and QA/QC tooling. With its user-friendly interface and various labeling tools, including polygons, bounding boxes, and lines, Labelbox allows users to annotate their data easily and provides strong labeler performance analytics and advanced quality control monitoring to ensure high-quality labeling results. 9/21
Labelbox’s superpixel coloring option for semantic segmentation significantly improves the accuracy of image labeling tasks. The platform also offers enterprise-friendly plans and SOC2 compliance, making it a reliable solution for large-scale data annotation projects. Its Python SDK allows users to integrate Labelbox with their existing machine- learning workflows, making it a versatile and powerful tool. Labelbox is an excellent choice for businesses and organizations seeking a comprehensive data labeling platform. Computer Vision Annotation Tool (CVAT) CVAT is a web-based, open-source platform for annotating images and videos. It provides an intuitive interface for labeling objects, such as polygons, bounding boxes, and key points for object detection and tracking tasks. With CVAT, users can also perform semantic segmentation and image classification tasks and benefit from advanced features like merging, review, and quality control tools to ensure accurate and consistent results. CVAT’s flexible architecture makes integrating it with machine learning frameworks like TensorFlow and PyTorch easy. It also offers customization options, allowing users to tailor the platform to their annotation needs. CVAT is free to use as an open-source tool and leverages community-driven development. It is a great choice for researchers and developers who require a customizable, open-source platform for their image and video annotation tasks. Diffgram Diffgram is a data labeling and management platform that aims to simplify the annotation and management of large datasets for machine learning tasks. It allows you to perform various annotation techniques, such as polygons, bounding boxes, lines, and segmentation masks, with tools for tracking changes and revisions over time. Its intuitive and user-friendly web-based interface offers team collaboration features, automation options, and integration with other machine-learning tools. Diffgram stands out with its live annotation feature, allowing multiple users to annotate the same dataset simultaneously and in real-time. This makes it useful for collaborative projects and speeding up the annotation of large datasets. Diffgram offers advanced data management capabilities such as version control, data backup, and sharing. These features ensure accurate and consistent annotations while streamlining the machine- learning workflow for businesses and organizations. Prodigy Prodigy is an annotation tool designed to simplify and expedite the labeling process for machine learning tasks. It boasts a user-friendly interface that allows users to annotate text, image, and audio data easily. Prodigy’s advanced labeling features include entity recognition, text classification, and image segmentation, and it also offers support for custom annotation workflows. 10/21
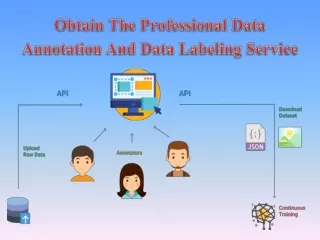
One of the key benefits of Prodigy is its active learning functionality, which allows users to train machine learning models more efficiently by selecting only the most informative examples for annotation. This saves time and reduces costs while improving model accuracy. Prodigy is also equipped with various collaboration features, making it ideal for team projects with large datasets. It integrates seamlessly with popular machine learning libraries and frameworks, such as spaCy and PyTorch, making it an excellent addition to your existing workflows. Overall, Prodigy is a powerful and versatile annotation tool that offers advanced features, active learning capabilities, and easy integration with existing workflows, making it an essential asset for machine learning projects. Brat Brat is an open-source tool that helps annotate text data for natural language processing tasks. Its user-friendly interface allows users to annotate various entities, relations, events, and temporal expressions. Brat provides advanced features like annotation propagation, customizable entity types and relations, and cross-document annotation. Brat also supports collaborative annotation and enables easy management of large annotated datasets. What sets Brat apart is its flexibility, allowing users to define their custom annotation schemas and create unique annotation interfaces. The tool also provides an API for programmatic access to annotations, making it easy to integrate with other workflows. Brat is a powerful and flexible annotation tool widely popular among researchers and developers working on natural language processing projects. Its open- source nature and API access make it an excellent choice for anyone seeking an effective text annotation solution. How does data annotation work? Data annotation typically involves the following steps: Define annotation guidelines: Before beginning the data annotation process, it is crucial to develop precise rules that guide the annotators on how to label the data. Annotation guidelines may outline the precise annotation tasks to be completed, the categories or labels to be applied, any particular rules or standards to adhere to, and samples for use as a guide. Choose an annotation tool: Once you have defined the annotation task, you must choose relevant tools. Many tools are available for data types, such as text, images, and video. Some popular annotation tools include Labelbox, Amazon SageMaker Ground Truth, and VGG Image Annotator. Prepare the data: Before annotating data, you must prepare it. This involves cleaning and organizing the data to be ready for annotation. For example, if you annotate text, you might need to remove any formatting or special characters that could interfere with the annotation process. 11/21
Select and train annotators: Annotators are individuals responsible for labeling the data based on the guidelines. Annotators can be domain experts, linguists, or trained annotators. It’s important to provide adequate training to annotators to ensure consistency and accuracy. Training may involve providing examples, conducting practice sessions, and giving feedback. Annotate data: Once the annotators are trained, they can start annotating the data according to the established guidelines. Annotations may involve adding labels, tags, or annotations to specific parts of the data, such as entities, sentiment, intent, or other relevant information, based on the annotation tasks defined in the guidelines. Quality control: Quality control must be made during the annotation process to ensure the correctness and consistency of the annotations. This can entail reviewing the annotations regularly, giving the annotators feedback, and clearing up any questions or ambiguities. Quality control techniques are crucial for the annotated data to be valid and reliable. Iterative feedback and refinement: Annotating data is frequently an iterative process that involves constant feedback and improvement. Regular meetings or discussions with annotators may be part of this to answer concerns, explain rules, and raise the quality of annotations. To ensure a seamless and efficient annotation process, keeping lines of communication open with annotators is crucial. Data validation: After the data is annotated, it’s important to validate the accuracy and quality of the annotations. This may involve manually reviewing a subset of the annotated data to ensure the annotations align with the defined guidelines and meet the desired quality standards. Post-annotation analysis: After the data has been validated and annotated, it can be analyzed for various activities in NLP or machine learning, including model training, evaluation, and other downstream tasks. The annotated data acts as a labeled dataset that may be used to test the efficacy of NLP algorithms or train supervised machine learning models. Data annotation is a critical step in NLP and machine learning workflows, as the quality and accuracy of the annotated data directly impact the performance and reliability of the subsequent models or applications. Annotation techniques After selecting your annotation method, the data annotation technique must be decided. This is the method that annotators will use to add annotations to your data. For instance, they might create multi-sided polygons, draw squares around objects, or attach landmarks. Here are some annotation techniques: 12/21
Bounding boxes In computer vision, object detection tasks often involve the use of bounding box annotation, which is a fundamental type of data annotation. In this annotation method, a rectangular or square box is drawn around the target object in an image or video frame. Bounding box annotation is popular in many applications since it is straightforward and adaptable. It is particularly suitable when the precise shape of the object is not crucial, such as in cases of food cartons or traffic signs. Additionally, bounding box annotation is valuable when determining the presence or absence of an object in an image is the primary requirement. In such cases, annotators mark a bounding box around the object to indicate its existence or absence, without focusing on detailed shapes or contours. Bounding box annotation, however, has limitations when working with complex objects that lack right angles and when thorough information about what’s happening inside the box is required. Polygonal segmentation When defining the location and bounds of a target object in an image or video frame, complicated shapes, commonly polygons, are used as a version of the bounding box annotation technique. Polygons can depict complicated shapes like those of automobiles, people, animals, logos, and other items more accurately than bounding boxes, which can only represent objects with right angles. By removing pointless pixels that can throw off the classification algorithm, polygons in data annotation enable more exact delineation of object boundaries. This improved accuracy can be especially helpful when doing tasks like object recognition or segmentation, where the item’s geometry is crucial to success. However, it may also have limitations when dealing with overlapping objects or complex scenes, requiring careful annotation strategies to ensure accurate and meaningful annotations. Polylines Polylines are a technique that involves plotting one or more continuous lines or segments to indicate the positions or boundaries of objects within an image or video frame. Polylines are especially helpful when significant characteristics of objects appear linear, such as establishing lanes or sidewalks for autonomous vehicles. Polylines are frequently used in jobs where the objects of interest are linear in character, and a basic bounding box or polygon may not adequately capture their shape or location. For instance, using polylines to define lanes and sidewalks in road scene analysis for autonomous vehicles can result in more accurate and thorough annotations than other methods. Polylines, however, might not be applicable or appropriate for all situations, particularly when objects are non-linear or wider than one pixel. 13/21
Landmarking Dot annotation or landmarking, is frequently used in computer vision and image analysis applications, such as item detection in aerial footage, facial recognition, and studying human body position. This entails placing tiny dots or marks on particular locations of interest in an image. In face recognition, landmarking is used to recognize and pinpoint facial characteristics like the mouth, nose, and eyes so that they may later be used to identify people uniquely. Similarly, landmarking can be used to annotate important body points like joints to assess the posture and alignment of the human body. When analyzing aerial imagery, landmarking can be used to find important items like cars, buildings, or other landmarks. However, landmarking can be time-consuming and prone to errors, particularly when working with huge datasets or complicated images. Tracking Annotating the movement of objects over numerous frames in a video or image sequence is known as tracking, object tracking or motion tracking. It is frequently employed in many computer vision applications, including surveillance, action recognition, and autonomous driving. Interpolation is a tracking technique where the annotator labels the object’s position in one frame, skip the next few, and then has the annotating tools fill in the movement and track the item through the frames. As opposed to manually annotating each frame, this can save time, but good tracking still requires high accuracy and dedication. However, tracking can be time- consuming and labor-intensive, particularly when working with lengthy recordings or complicated scenarios that contain numerous moving objects. Frame-by-frame annotation can easily become prohibitively expensive, especially for huge datasets. Furthermore, tracking might be difficult when objects are obscured, alter appearance, or have complex motion patterns. Researchers and professionals are creating automated tracking methods that use computer vision algorithms, like object detection and tracking algorithms based on deep learning or other machine learning methods, to overcome these issues. By automatically recognizing and following objects across frames, these automated tracking technologies seek to minimize the manual work and expense involved in tracking. 14/21
2D boxes Computer vision tasks frequently employ 2D bounding boxes, commonly called object bounding boxes, as a data annotation technique. They entail drawing rectangular boxes to locate and categorize objects of interest in an image. This annotation style is utilized in numerous applications, including autonomous driving, object recognition and detection. When annotating a picture, bounding boxes are drawn around any objects with the top-left and bottom-right corners being specified. The bounding boxes show the objects’ spatial extent and detail about their position, dimensions, and shape. Due to the simplicity in implementation and interpretability, 2D bounding boxes are frequently employed in various computer vision tasks to annotate objects in images. However, they might not be appropriate for applications that call for more in-depth annotations and may not capture fine-grained features of objects, such as their exact shape or position. For instance, 2D bounding boxes might only sometimes be sufficient for precise object localization and tracking in complicated situations with occlusions or overlapping objects. 3D cuboids The concept of 2D bounding boxes is expanded into the third dimension by 3D cuboids, commonly referred to as 3D bounding boxes or cuboid annotations. They are used to annotate objects in pictures or videos with extra details on their three- dimensional (3D) spatial characteristics, such as size, position, orientation, and movement. The most common way to depict 3D cuboids is as rectangular prisms or cuboids with six faces, each corresponding to a bounding box with a distinct orientation (for example, front, back, top, bottom, left, right). By recording an object’s position and size, orientation, rotation, and anticipated movement, the 3D cuboid annotations can offer a more thorough and accurate depiction of objects in 3D space. In computer vision applications like 3D object detection, scene understanding, and robotics that call for more in-depth knowledge of objects in 3D space, 3D cuboid annotation is very helpful. It can offer deeper information for tasks like assessing object postures, tracking objects in three dimensions, and forecasting future object movements.In contrast to 2D bounding boxes, annotating 3D cuboids can be more difficult and time-consuming since it calls for annotators to precisely estimate the 3D attributes of objects from 2D photos or videos. 15/21
Polygonal annotation The process of polygonal annotation, sometimes called image segmentation or polygon annotation, involves tracing the outline of objects in photographs using a network of connected vertices to create a closed polygon shape. Complex object shapes that are too intricate for simple bounding boxes to depict accurately can be captured using polygonal annotations. Compared to bounding boxes, polygonal annotations offer better precision since they can accurately capture the shape and contour of objects in pictures and videos. They are especially helpful for natural objects with uneven shapes, curving edges, or many sides. Annotators can more precisely define the boundaries of objects and provide more specific information about their spatial characteristics, such as their precise size, shape, and location in the image, using polygonal annotations. Contrary to other annotation techniques, polygonal annotation might be more time-consuming and difficult because annotators call for meticulous and exact delineation of item boundaries. Accurate annotation of complicated item shapes may require additional skill or topic knowledge. Polygonal annotations, however, are a potent technique for capturing precise item forms and offering extensive data.Although many data annotation techniques exist, your choice should be based on the use case at hand. Each technique has its own limitations, and it is important to be aware of these limitations, even if you have limited options in selecting a technique. Some techniques may be more expensive, which can impact the amount of data you can annotate within your budget. On the other hand, techniques that introduce variation in annotations may require careful consideration of how small discrepancies can affect the performance of your model. How to annotate text data? Here, we will see how text annotation is done using Python. Step 1: First, install streamlit and then install this library using pip. pip install streamlit pip install st-annotated-text Step 2: Import the text to annotate for labeling. from annotated_text import annotated_text annotated_text( "This ", ("is", "Verb"), " some ", ("annotated", "Adj"), 16/21
("text", "Noun"), " for those of ", ("you", "Pronoun"), " who ", ("like", "Verb"), " this sort of ", ("thing", "Noun"), ". ", "And here's a ", ("word", ""), " with a fancy background but no label.", ) In the code above, we use the annotated_text function from the annotated_text package to display a text with annotations. The annotated_text function takes a series of arguments, where each argument can either be a plain string or a tuple with two elements: the annotated word and its label. The labels indicate what type of word or phrase is annotated (e.g., Noun, Verb, Adj, Pronoun, etc.). The example has a string with several annotated words and labels. For instance, the word “is” is annotated as a “Verb”, the word “annotated” is annotated as an “Adj”, and the word “text” is annotated as a “Noun”. The annotated_text function will render this text with each annotated word highlighted and its corresponding label displayed next to it. The result is a visually appealing way to highlight and label specific words within a body of text, making it easier to understand the meaning and context of the text. Step 3: Pass nested arguments You can also pass lists (and lists within lists!) as an argument: my_list = [ "Hello ", [ "my ", 17/21
("dear", "Adj"), " ", ], ("world", "Noun"), ".", ] annotated_text(my_list) Hello, my dear Adj world Noun The output here is a formatted string with the annotated text, where the annotated words are highlighted, and the corresponding labels are displayed next to them. Step 4: Customize color If an annotation tuple has more than two items, the third item will be used as the background color, and the fourth item will be used as the foreground color. annotated_text( "This ", ("is", "Verb", "#8ef"), " some ", ("annotated", "Adj", "#faa"), ("text", "Noun", "#afa"), " for those of ", ("you", "Pronoun", "#fea"), " who ", ("like", "Verb", "#8ef"), " this sort of ", ("thing", "Noun", "#afa"), ". " "And here's a ", ("word", "", "#faf"), " with a fancy background but no label.", ) In the above code, the third item in some of the annotation tuples contains a hexadecimal color code (e.g., “#8ef”), which is used to set the background color of the annotated text. The fourth item, if provided, would set the foreground color (i.e., the color of the text). The default text color will be used if the foreground color is not provided. The output will be a formatted string with the annotated text, where the annotated words are highlighted with the specified background color and the corresponding labels are displayed next to them. The words with no label will be displayed with the specified background color but no label. Step 5: Custom style The annotated_text module provides a set of default parameters that control the appearance of the annotated text, such as the color, font size, border radius, padding, etc. from annotated_text import annotated_text, parameters parameters.SHOW_LABEL_SEPARATOR = False parameters.BORDER_RADIUS = 0 18/21
parameters.PADDING = "0 0.25rem" You can customize the parameters module by overriding their default values by importing the parameters module. In the example code you provided, the SHOW_LABEL_SEPARATOR parameter is set to False, which means that the separator between the annotated text and the label will not be shown. The BORDER_RADIUS parameter is set to 0, meaning the annotated text will have square instead of rounded corners. The PADDING parameter is set to “0 0.25rem” meaning the annotated text will have smaller padding than the default value. By customizing these parameters, you can create different styles for the annotated text to match your needs. Step 6: Further customization If you want to go beyond the customizations above, you can bring your own CSS! from annotated_text import annotated_text, annotation annotated_text( "Hello ", annotation("world!", "noun", font_family="Comic Sans MS", border="2px dashed red"), ) Hello world!noun The above code uses the annotation function to create an annotated text with a custom CSS style. The annotation function takes the annotated text as its first argument and any CSS style properties as additional keyword arguments. In this example, the annotated text “world!” is given the label “noun” and is styled with a custom font family (“Comic Sans MS”) and a border of 2 pixels dashed in red. By using custom CSS styles, you can have full control over the appearance of the annotated text and create styles that match your specific needs. Step 7: Have a look at the output 19/21
Decide Pre-defined Guidelines Choose Select & Train Annotators Prepare Data Annotation Tool Raw Data Post Annotation Analysis Data Validation & Feedback Quality Control Annotate Date LeewayHertz Use cases of data annotation Data annotation has numerous use cases across industries. Here are a few examples: Autonomous vehicles Data annotation is used to create labeled datasets of images and videos for training self- driving cars to recognize and respond to various objects and scenarios on the road, such as traffic lights, pedestrians, and other vehicles. It enables self-driving cars to recognize and respond to objects and scenarios on the road, determine their position, and confidently navigate complex roadways. Healthcare Data annotation labels medical images, such as X-rays, CT scans, and MRIs, to train machine learning models to identify tumors, lesions, and other anomalies. It also labels electronic health records to improve patients’ health for effective outcomes. E-commerce Data annotation is used in e-commerce to analyze customer behavior patterns such as purchase history and preferences. This information is then used to provide personalized recommendations and improve product search results, increasing customer satisfaction and sales. Social media Data annotation is used to analyze content and detect spam, identify trends, and monitor sentiment analysis for marketing and customer service purposes. This enables businesses to understand their customers and their needs better and engage with them more effectively on social media platforms. Robotics Data annotation is used in robotics to label images and videos for training robots to recognize and respond to various objects and scenarios in industrial and commercial settings. This enables robots to perform tasks more efficiently and accurately, increasing productivity. 20/21
Sports analytics Data annotation labels video footage of games like soccer and basketball to analyze player performance and improve team strategies. This enables coaches and analysts to identify patterns and insights that can lead to more effective training, game planning, and performance optimization for athletes and teams. Data annotation is used in various real-life scenarios to improve machine learning models and create more efficient and effective systems in numerous industries. Endnote Data annotation is an essential component of ML technology and has played a vital role in developing some of the most advanced AI applications available today. The increasing demand for high-quality data annotation services has led to the emergence of dedicated data annotation companies. As the volume of data continues to grow, the need for accurate and comprehensive data annotation will increase. Sophisticated datasets are necessary to address some of the most challenging problems in AI, such as image and speech recognition. By providing high-quality annotated data, data annotation companies can help businesses and organizations leverage the full potential of AI, leading to more personalized customer experiences and improved operational efficiency. As AI continues to evolve, the role of data annotation will become increasingly critical in enabling businesses to stay competitive and meet the growing demands of their customers. By investing in high-quality data annotation services, organizations can ensure that their machine-learning models are accurate, efficient, and capable of delivering superior results. Enhance your machine learning models with high-quality training data – start annotating now! Contact LeewayHertz experts for your requirements. 21/21