Download
1 / 23
230 likes | 503 Views
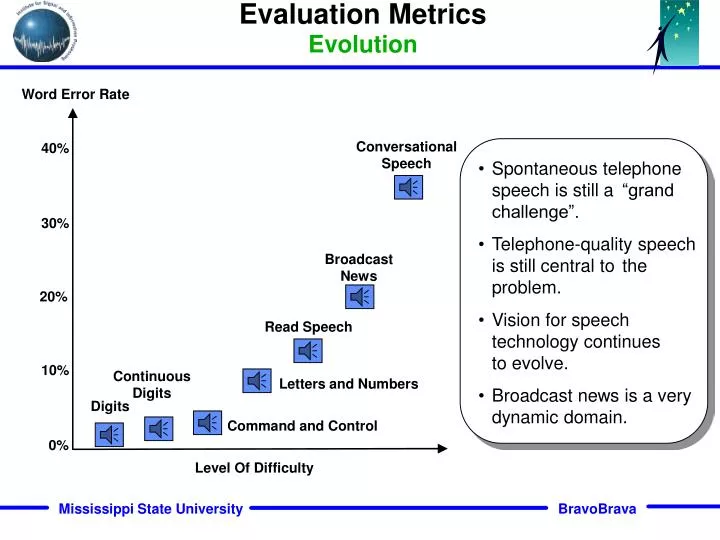
Evaluation Metrics Evolution. Word Error Rate. Conversational Speech. 40%. Spontaneous telephone speech is still a “grand challenge”. Telephone-quality speech is still central to the problem. Vision for speech technology continues to evolve. Broadcast news is a very dynamic domain.

E N D
Evaluation MetricsEvolution Word Error Rate Conversational Speech 40% • Spontaneous telephone speech is still a “grand challenge”. • Telephone-quality speech is still central to the problem. • Vision for speech technology continues • to evolve. • Broadcast news is a very dynamic domain. 30% Broadcast News 20% Read Speech 10% Continuous Digits Letters and Numbers Digits Command and Control 0% Level Of Difficulty
Evaluation MetricsHuman Performance Word Error Rate • Human performance exceeds machine • performance by a factor ranging from • 4x to 10x depending on the task. • On some tasks, such as credit card number recognition, machine performance exceeds humans due to human memory retrieval capacity. • The nature of the noise is as important as the SNR (e.g., cellular phones). • A primary failure mode for humans is inattention. • A second major failure mode is the lack of familiarity with the domain (i.e., business terms and corporation names). 20% Wall Street Journal (Additive Noise) 15% Machines 10% 5% Human Listeners (Committee) 0% Quiet 10 dB 16 dB 22 dB Speech-To-Noise Ratio
Evaluation MetricsMachine Performance • Common evaluations fuel • technology development. • Tasks become progressively • more ambitious and challenging. • A Word Error Rate (WER) • below 10% is considered • acceptable. • Performance in the field is • typically 2x to 4x worse than • performance on an evaluation. 100% (Foreign) Read Speech Conversational Speech Broadcast Speech 20k Spontaneous Speech Varied Microphones (Foreign) 10 X 10% 5k Noisy 1k 1% 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003
Evaluation MetricsBeyond WER: Named Entity F-Measure 100% • An example of named entity annotation: • Mr. <en type=“person”>Sears</en> bought • a new suit at <en type=“org”> Sears</en> • in <en type=“location”>Washington</en> • <time type=“date”>yesterday</time> • Evaluation Metrics: 90% 80% # slots correctly filled # slots filled in key Recall = 70% # slots correctly filled # slots filled by system 30% 0% 10% 20% Precision = Word Error Rate (Hub-4 Eval’98) 2 x recall x precision (recall + precision) F-Measure = • Information extraction is the analysis of • natural language to collect information • about specified types of entities. • As the focus shifts to providing enhanced annotations, WER may not be the most appropriate measure of performance (content-based scoring).
Recognition ArchitecturesWhy Is Speech Recognition So Difficult? • Comparison of “aa” in “IOck” vs. “iy” in bEAt for conversational speech (SWB) Feature No. 2 Ph_1 Ph_2 Ph_3 Feature No. 1 • Our measurements of the • signal are ambiguous. • Region of overlap represents classification errors. • Reduce overlap by introducing acoustic and linguistic context (e.g., context-dependent phones).
Recognition ArchitecturesA Communication Theoretic Approach Message Source Linguistic Channel Articulatory Channel Acoustic Channel Features Observable: Message Words Sounds • Bayesian formulation for speech recognition: • P(W|A) = P(A|W) P(W) / P(A) Objective: minimize the word error rate Approach: maximize P(W|A) during training • Components: • P(A|W) : acoustic model (hidden Markov models, mixtures) • P(W) : language model (statistical, finite state networks, etc.) • The language model typically predicts a small set of next words based on • knowledge of a finite number of previous words (N-grams).
Recognition ArchitecturesIncorporating Multiple Knowledge Sources • The signal is converted to a sequence of feature vectors based on spectral and temporal measurements. • Acoustic models represent sub-word units, such as phonemes, as a finite-state machine in which states model spectral structure and transitions • model temporal structure. Acoustic Front-end Acoustic Models P(A/W) • The language model predicts the next • set of words, and controls which models are hypothesized. Search • Search is crucial to the system, since • many combinations of words must be • investigated to find the most probable • word sequence. Recognized Utterance Input Speech Language Model P(W)
Acoustic ModelingFeature Extraction • Incorporate knowledge of the • nature of speech sounds in • measurement of the features. • Utilize rudimentary models of • human perception. • Measure features 100 times per sec. • Use a 25 msec window forfrequency domain analysis. • Include absolute energy and 12 spectral measurements. • Time derivatives to model spectral change. Fourier Transform Input Speech Cepstral Analysis Perceptual Weighting Time Derivative Time Derivative Delta Energy + Delta Cepstrum Delta-Delta Energy + Delta-Delta Cepstrum Energy + Mel-Spaced Cepstrum
Acoustic ModelingHidden Markov Models • Acoustic models encode the temporal evolution of the features (spectrum). • Gaussian mixture distributions are used to account for variations in speaker, accent, and pronunciation. • Phonetic model topologies are simple left-to-right structures. • Skip states (time-warping) and multiple paths (alternate pronunciations) are also common features of models. • Sharing model parameters is a common strategy to reduce complexity.
Acoustic ModelingParameter Estimation • Initialization • Single • Gaussian • Estimation • 2-Way Split • Mixture • Distribution • Reestimation • 4-Way Split • Reestimation ••• • Closed-loop data-driven modeling supervised only from a word-level transcription • The expectation/maximization (EM) algorithm is used to improve our parameter estimates. • Computationally efficient training algorithms (Forward-Backward) have been crucial. • Batch mode parameter updates are typically preferred. • Decision trees are used to optimize parameter-sharing, system complexity, and the use of additional linguistic knowledge.
Language ModelingN-Grams: The Good, The Bad, and The Ugly • Unigrams (SWB): • Most Common: “I”, “and”, “the”, “you”, “a” • Rank-100: “she”, “an”, “going” • Least Common: “Abraham”, “Alastair”, “Acura” • Bigrams (SWB): • Most Common: “you know”, “yeah SENT!”, • “!SENT um-hum”, “I think” • Rank-100: “do it”, “that we”, “don’t think” • Least Common: “raw fish”, “moisture content”, • “Reagan Bush” • Trigrams (SWB): • Most Common: “!SENT um-hum SENT!”, “a lot of”, “I don’t know” • Rank-100: “it was a”, “you know that” • Least Common: “you have parents”, “you seen Brooklyn”
Language ModelingIntegration of Natural Language • Natural language constraints • can be easily incorporated. • Lack of punctuation and search • space size pose problems. • Speech recognition typically • produces a word-level • time-aligned annotation. • Time alignments for other levels • of information also available.
Implementation IssuesSearch Is Resource Intensive • Typical LVCSR systems have about 10M free parameters, which makes training a challenge. • Large speech databases are required (several hundred hours of speech). • Tying, smoothing, and interpolation are required.
Implementation IssuesDynamic Programming-Based Search • Dynamic programming is used to find the most probable path through the network. • Beam search is used to control resources. • Search is time synchronous and left-to-right. • Arbitrary amounts of silence must be permitted between each word. • Words are hypothesized many times with different start/stop times, which significantly increases search complexity.
Implementation IssuesCross-Word Decoding Is Expensive • Cross-word Decoding: since word boundaries don’t occur in spontaneous speech, we must allow for sequences of sounds that span word boundaries. • Cross-word decoding significantly increases memory requirements.
TechnologyConversational Speech • Conversational speech collected over the telephone contains background • noise, music, fluctuations in the speech rate, laughter, partial words, • hesitations, mouth noises, etc. • WER has decreased from 100% to 30% in six years. • Laughter • Singing • Unintelligible • Spoonerism • Background Speech • No pauses • Restarts • Vocalized Noise • Coinage
TechnologyAudio Indexing of Broadcast News • Broadcast news offers some unique • challenges: • Lexicon: important information in • infrequently occurring words • Acoustic Modeling: variations in channel, particularly within the same segment (“ in the studio” vs. “on location”) • Language Model: must adapt (“ Bush,” “Clinton,” “Bush,” “McCain,” “???”) • Language: multilingual systems? language-independent acoustic modeling?
TechnologyReal-Time Translation • Imagine a world where: • You book a travel reservation from your cellular phone while driving in • your car without ever talking to a human (database query) • You converse with someone in a foreign country and neither speaker • speaks a common language (universal translator) • You place a call to your bank to inquire about your bank account and • never have to remember a password (transparent telephony) • You can ask questions by voice and your Internet browser returns • answers to your questions (intelligent query) • From President Clinton’s State of the Union address (January 27, 2000): • “These kinds of innovations are also propelling our remarkable prosperity... • Soon researchers will bring us devices that can translate foreign languages • as fast as you can talk... molecular computers the size of a tear drop with the • power of today’s fastest supercomputers.” • Human Language Engineering: a sophisticated integration of many speech and • language related technologies... a science for the next millennium.
TechnologyFuture Directions Hidden Markov Models Dynamic Time-Warping Analog Filter Banks 2000 1990 1980 1970 1960 • What have we learned? • supervised training is a good machine learning technique • large databases are essential for the development of robust statistics • What are the challenges? • discrimination vs. representation • generalization vs. memorization • pronunciation modeling • human-centered language modeling • What are the algorithmic issues for the next decade: • Better features by extracting articulatory information? • Bayesian statistics? Bayesian networks? • Decision Trees? Information-theoretic measures? • Nonlinear dynamics? Chaos?
To Probe FurtherReferences Journals and Conferences: [1] N. Deshmukh, et. al., “Hierarchical Search for LargeVocabulary Conversational Speech Recognition,” IEEE Signal Processing Magazine, vol. 1, no. 5, pp. 84- 107, September 1999. [2] N. Deshmukh, et. al., “Benchmarking Human Performance for Continuous Speech Recognition,” Proceedings of the Fourth International Conference on Spoken Language Processing, pp. SuP1P1.10, Philadelphia, Pennsylvania, USA, October 1996. [3] R. Grishman, “Information Extraction and Speech Recognition,” presented at the DARPA Broadcast News Transcription and Understanding Workshop, Lansdowne, Virginia, USA, February 1998. [4] R. P. Lippmann, “Speech Recognition By Machines and Humans,” Speech Communication, vol. 22, pp. 1-15, July 1997. [5] M. Maybury (editor), “News on Demand,” Communications of the ACM, vol. 43, no. 2, February 2000. [6] D. Miller, et. al., “Named Entity Extraction from Broadcast News,” presented at the DARPA Broadcast News Workshop, Herndon, Virginia, USA, February 1999. [7] D. Pallett, et. al., “Broadcast News Benchmark Test Results,” presented at the DARPA Broadcast News Workshop, Herndon, Virginia, USA, February 1999. [8] J. Picone, “Signal Modeling Techniques in Speech Recognition,” IEEE Proceedings, vol. 81, no. 9, pp. 1215- 1247, September 1993. [9] P. Robinson, et. al., “Overview: Information Extraction from Broadcast News,” presented at the DARPA Broadcast News Workshop, Herndon, Virginia, USA, February 1999. [10] F. Jelinek, Statistical Methods for Speech Recognition,MIT Press, 1998. URLs and Resources: [11] “Speech Corpora,” The Linguistic Data Consortium, http://www.ldc.upenn.edu. [12] “Technology Benchmarks,” Spoken Natural Language Processing Group, The National Institute for Standards, http://www.itl.nist.gov/iaui/894.01/index.html. [13] “Signal Processing Resources,” Institute for Signal and Information Technology, Mississippi State University, http://www.isip.msstate.edu. [14] “Internet- Accessible Speech Recognition Technology,” http://www.isip.msstate.edu/projects/speech/index.html. [15] “A Public Domain Speech Recognition System,” http://www.isip.msstate.edu/projects/speech/software/index.html. [16] “Remote Job Submission,” http://www.isip.msstate.edu/projects/speech/experiments/index.html. [17] “The Switchboard Corpus,” http://www.isip.msstate.edu/projects/switchboard/index.html.






















